Nico
27 posts












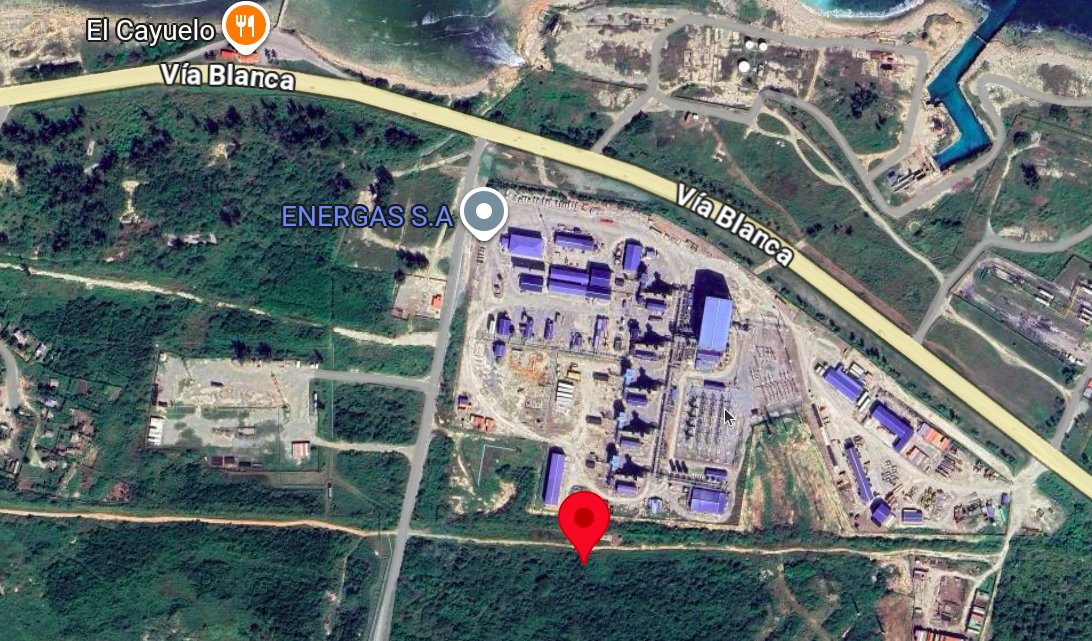
⚽️🇦🇷| Escala la tensión entre el Gobierno y la AFA tras la liberación de Nahuel Gallo. "La AFA tendrá que explicar su relación con el régimen chavista", dijo el jefe de Gabinete, Manuel Adorni. "El chavismo quería entregarlo a través de amigos de ellos". Patricia Bullrich El abogado de la AFA, Gregorio Dalbón, es el mismo abogado que el de Cristina Kirchner. Dalbón denunció penalmente al juez que frenó el viaje de Claudio “Chiqui” Tapia, que buscaba cerrar el acuerdo con el gobierno venezolano. 🤡🤡 ARCA prepara una denuncia contra la AFA por la emisión de presuntas facturas truchas en obras del predio de Ezeiza.






Gemma 4 26B MoE (4B active) on a single RTX 4090: - 162 t/s decode - 8,400 t/s prefill - Full 262K native context — 19.5 GB VRAM - Only 10 Elo below the 31B dense Q8_0 on dual 4090+3090: 9,024 t/s prefill at 10K. 2,537 t/s at full 262K — that's a novel in about 100 seconds. Q4_K_M + q8_0 K / turbo3 V using @no_stp_on_snek 's TurboQuant fork (github.com/TheTom/turboqu…). KV quant saves 1.8 GB, costs nothing. 3.7x faster decode than the dense. Single 4090 (262K): llama-server -m gemma-4-26B-A4B-it-UD-Q4_K_M.gguf -c 262144 -np 1 -ctk q8_0 -ctv turbo3 -fa on --fit off --cache-ram 0 -dev CUDA0 Dual GPU (Q8_0, 262K): llama-server -m gemma-4-26B-A4B-it-Q8_0.gguf -c 262144 -np 1 -fa on --fit off --cache-ram 0 llama.cpp b8635 + turboquant fork #Gemma4 #LocalLLM #llama_cpp #TurboQuant #RTX4090 #MoE #AI #OpenSource #GGUF #LocalAI