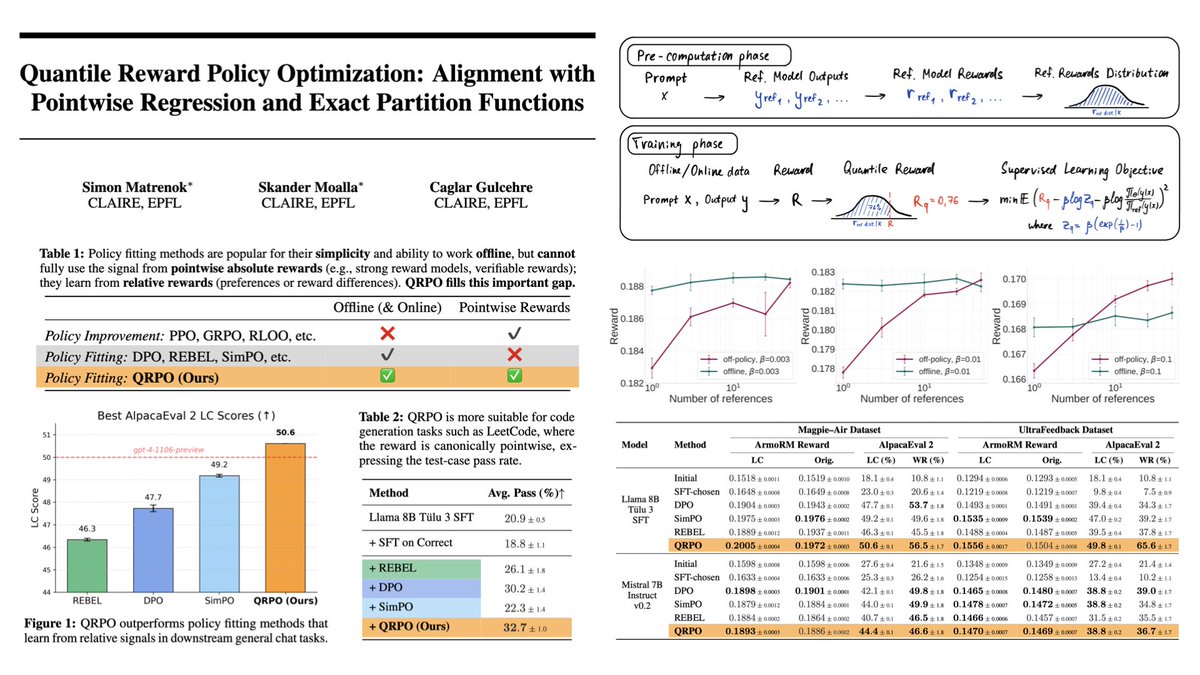
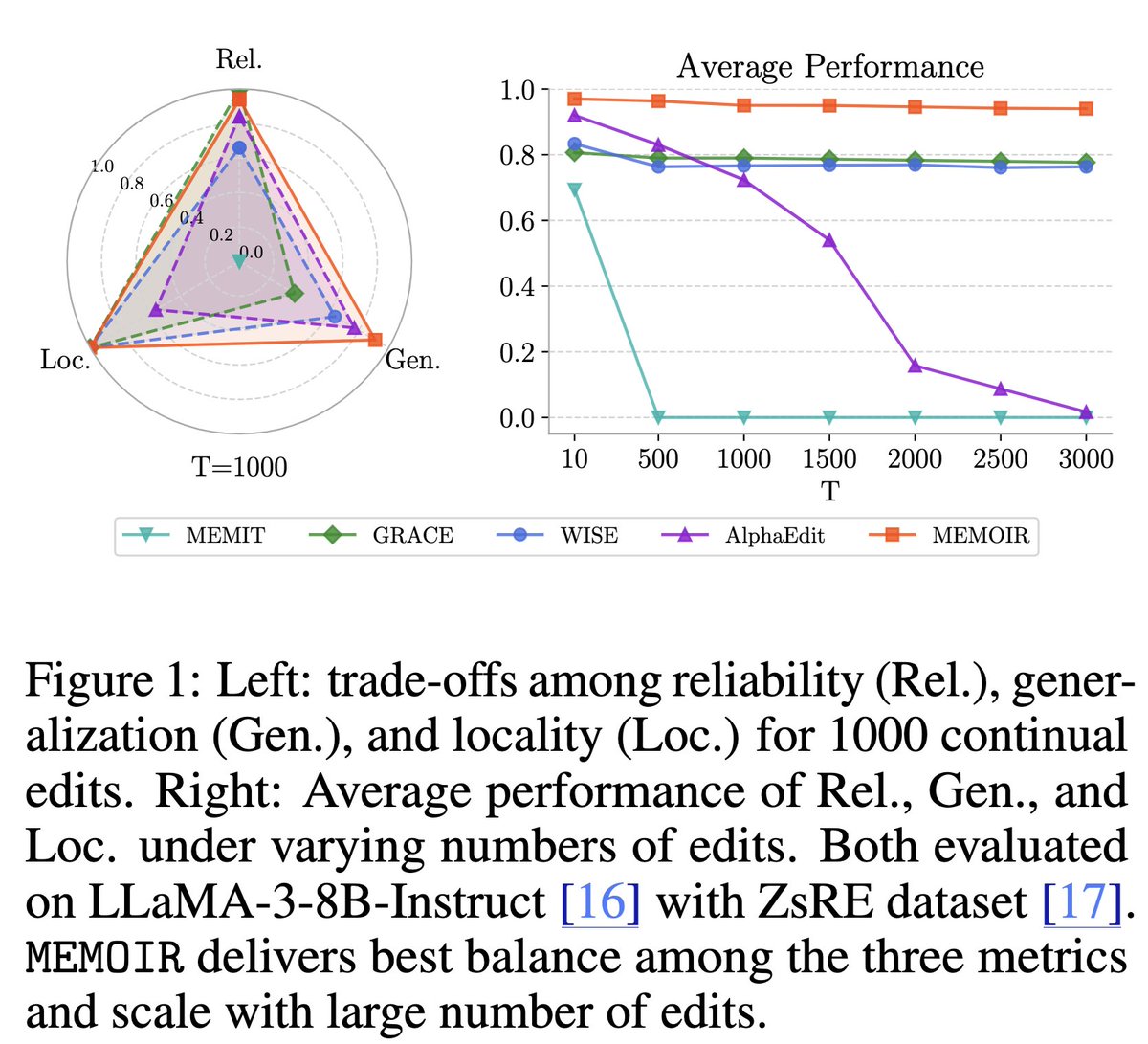
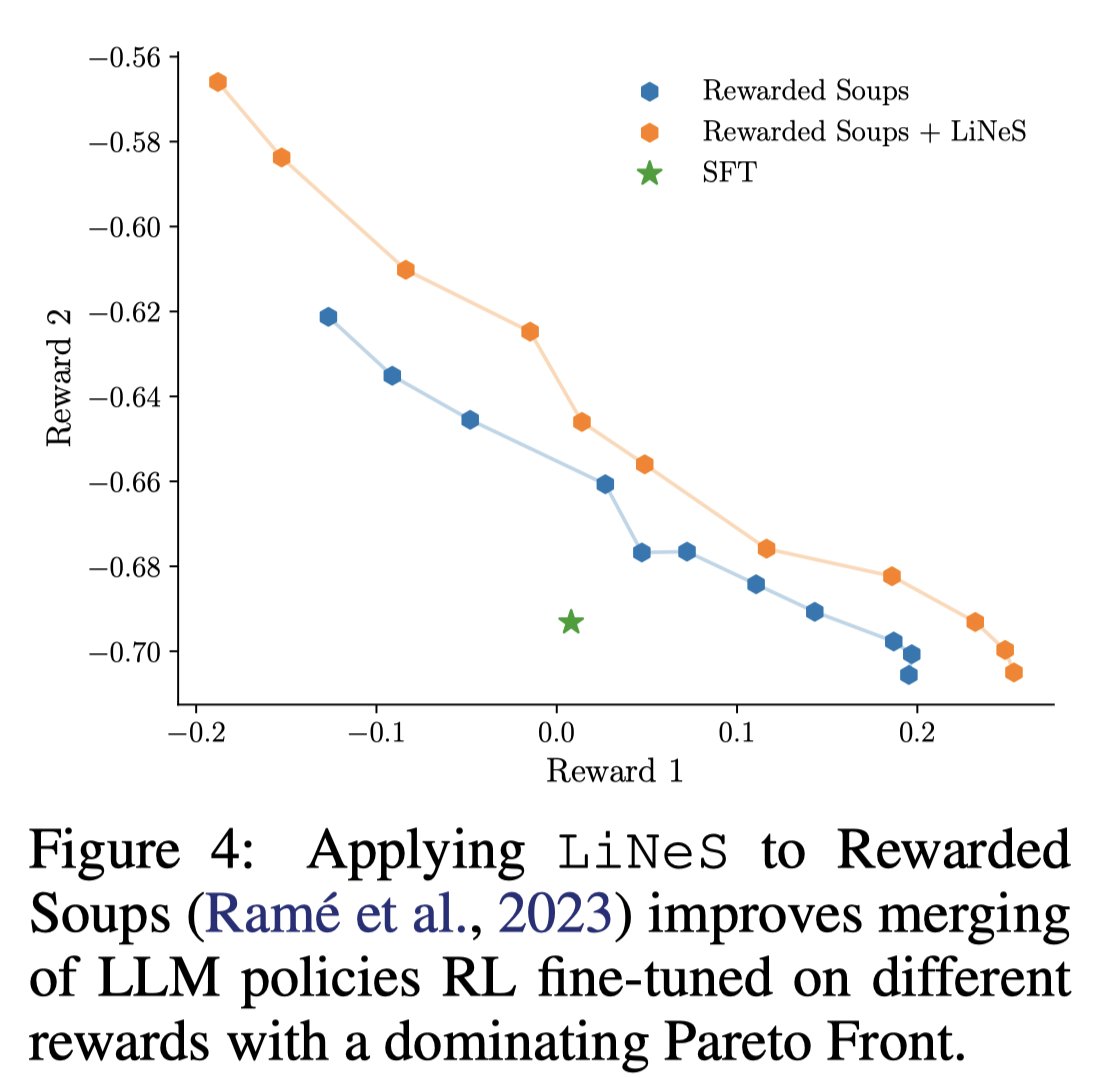
Sabitlenmiş Tweet

Fine-tuning pre-trained models leads to catastrophic forgetting, gains on one task cause losses on others. These issues worsen in multi-task merging scenarios.
Enter LiNeS 📈, a method to solve them with ease. 🔥
🌐: lines-merging.github.io
📜: arxiv.org/abs/2410.17146
🧵 1/11
English