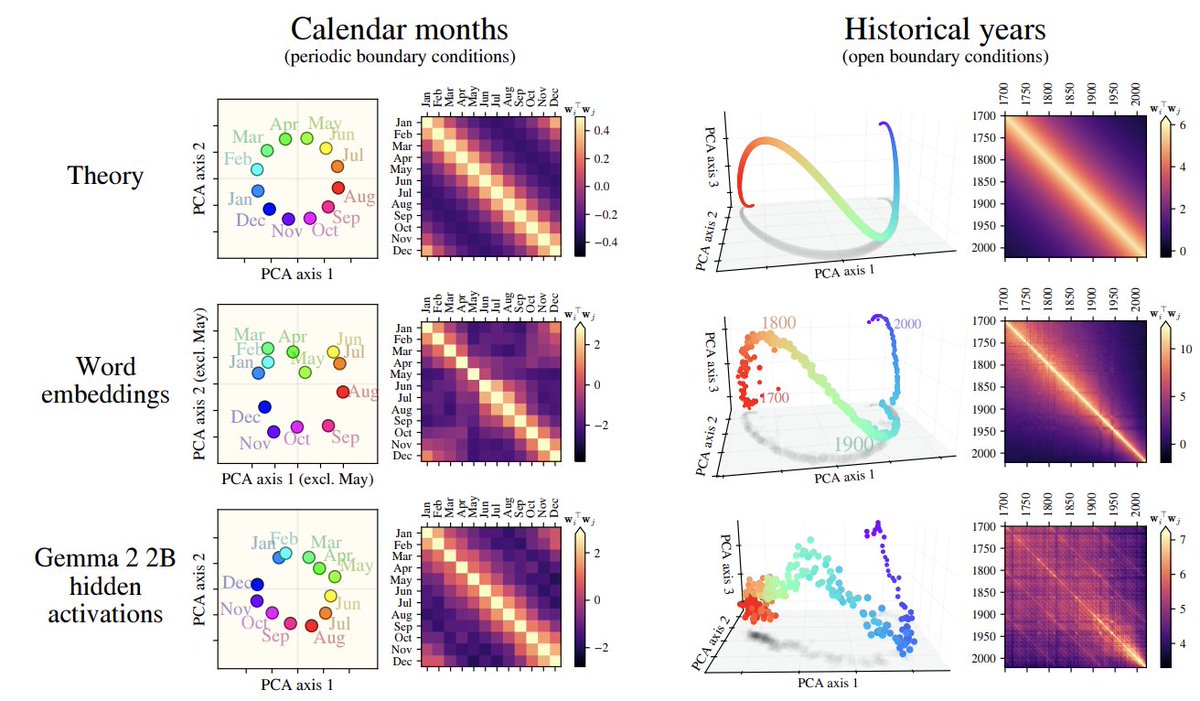
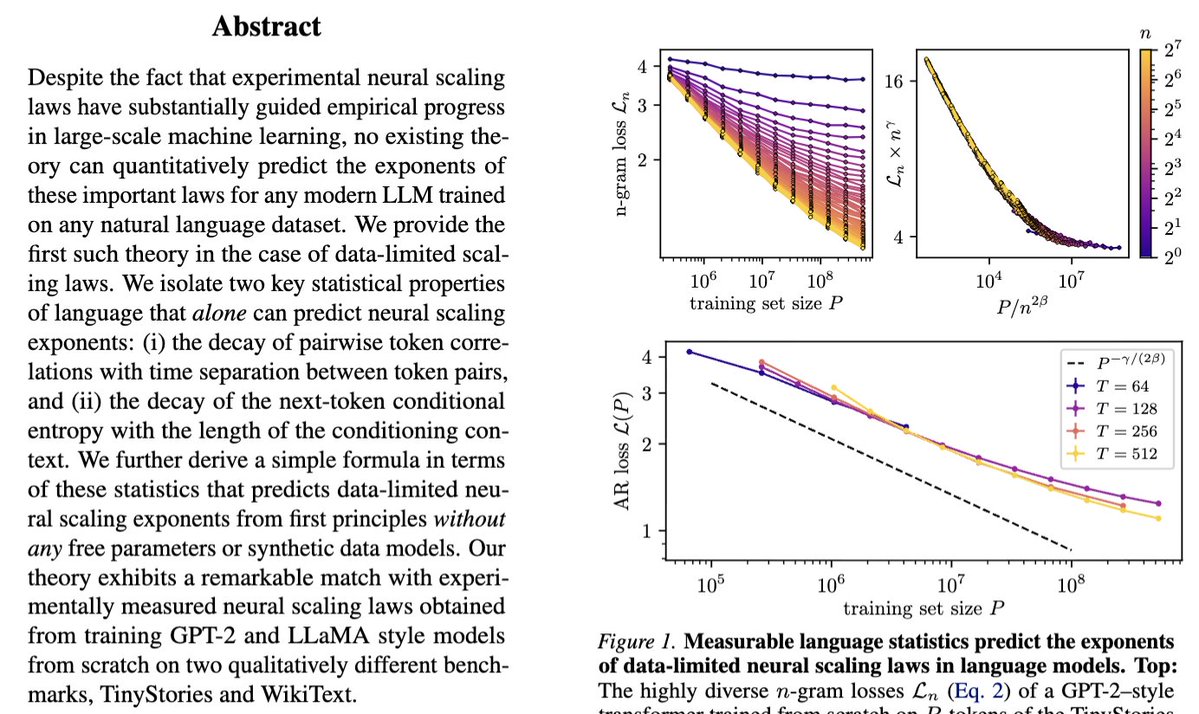
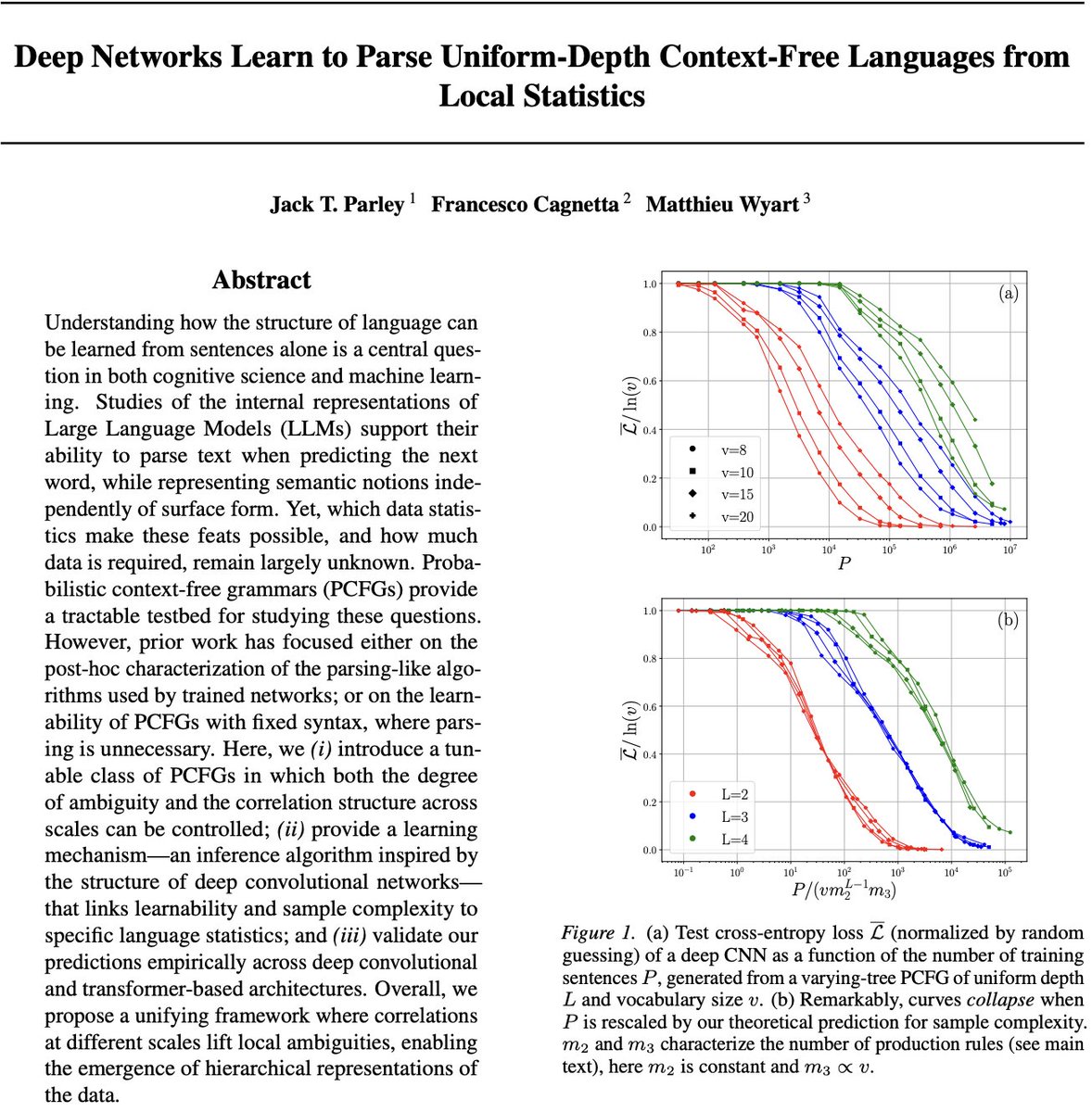
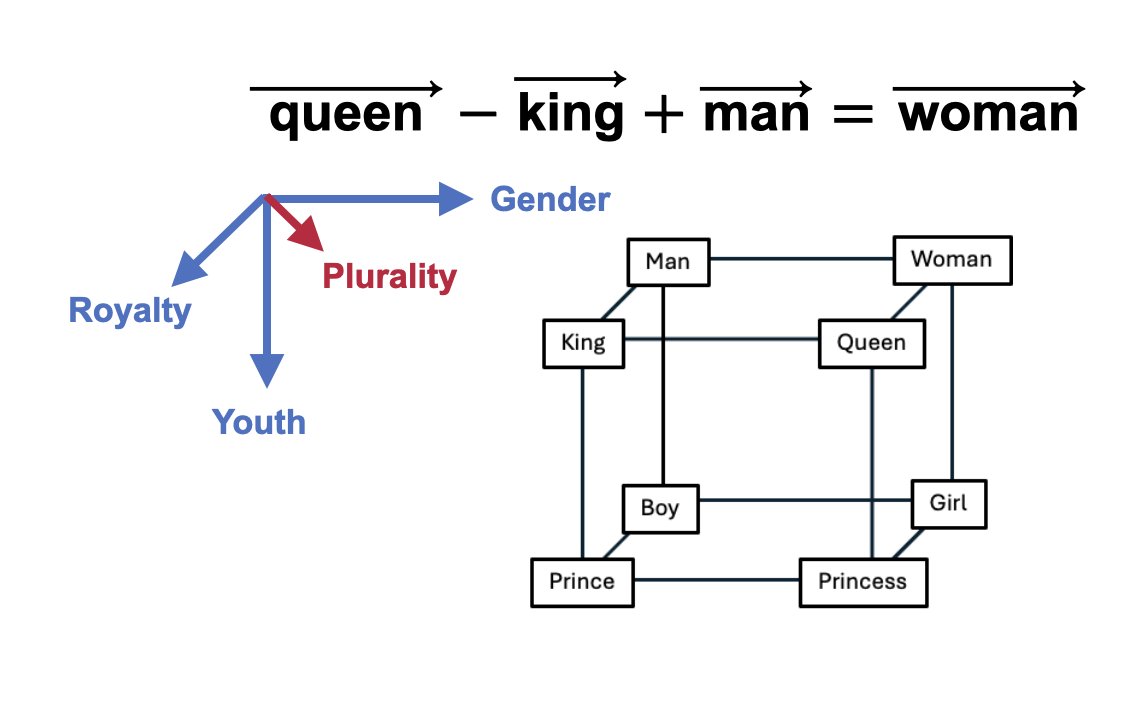
Sabitlenmiş Tweet

Amazed by language diffusion models like Mercury? So are we 🤯
But how do they actually learn to generate coherent (and creative!) text from scratch?
We dig into it using simple formal grammars and statistical physics.
Just accepted @icmlconf 2025 🎉

English