Sabitlenmiş Tweet
nilenso
1.9K posts


nilenso
@nilenso
Employee-owned programmer cooperative in Bangalore.
Katılım Mayıs 2013
476 Takip Edilen1.7K Takipçiler

nilenso retweetledi

So, if you recognize these patterns in your agents, and they don't fit your task at hand, you could steer them accordingly.
Full write-up: blog.nilenso.com/blog/2026/04/2…
Analysis code and data: github.com/nilenso/swe-be….

English
nilenso retweetledi
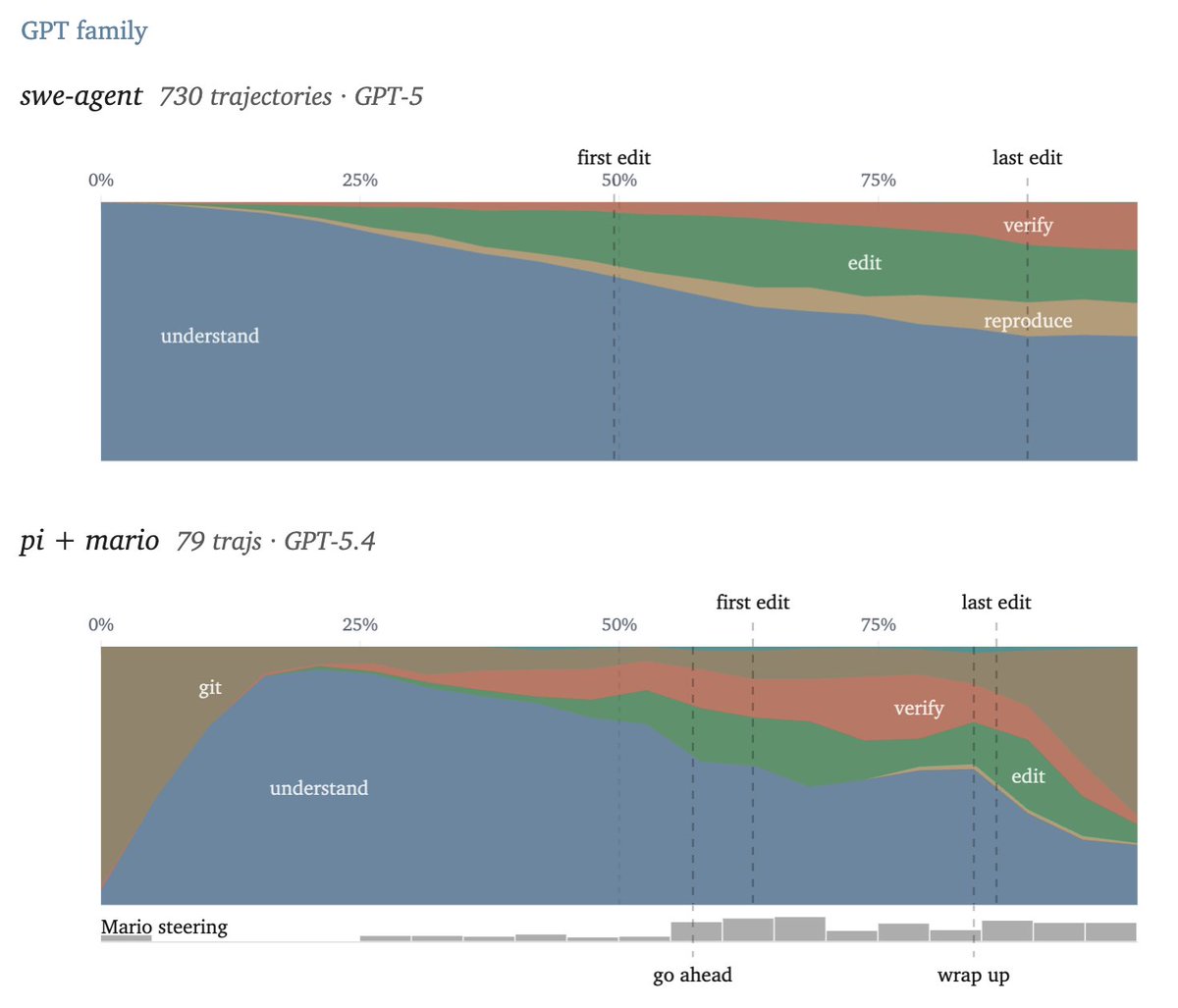
I wanted to check this on newer models, but no SWE-bench Pro trajectories exist for Opus 4.6 / GPT-5.4.
So I pulled @badlogicgames' issue-fixing trajectories and ran the same analysis. Thanks for putting those out in public, they make this kind of analysis possible.
Opus's first edit sits at 47% in your pi sessions, vs 35% for Sonnet 4.5 on SWE-bench. Harness and model differ too, so I can't isolate the prompt's effect, but the shape shifts in the direction you'd expect from the explicit analyze-dont-edit prompt.
I think we can see the effect of the human-steering through explicit analysis / go-ahead / wrap-up cues in this comparison.

English
nilenso retweetledi

super interesting work! glad my open traces on @huggingface allow this!
my workflow is mostly:
- prompt template with injected gh issue url.and instructions on how to annalyze and present results + concise impl plan to me
- i confirm analysis/plan either by knowing or double checking manually. may steer to adjust plan a few times until model knows what to do
- tell model to implement
- check results, steer if necessary
- if all good (type checking, linting, tests, manual code review, manual tests), another prompt template is used to wrap up, i.e. changelog, docs, commit, push, comment on issue, close issue
Srihari Sriraman@SrihariSriraman
I wanted to check this on newer models, but no SWE-bench Pro trajectories exist for Opus 4.6 / GPT-5.4. So I pulled @badlogicgames' issue-fixing trajectories and ran the same analysis. Thanks for putting those out in public, they make this kind of analysis possible. Opus's first edit sits at 47% in your pi sessions, vs 35% for Sonnet 4.5 on SWE-bench. Harness and model differ too, so I can't isolate the prompt's effect, but the shape shifts in the direction you'd expect from the explicit analyze-dont-edit prompt. I think we can see the effect of the human-steering through explicit analysis / go-ahead / wrap-up cues in this comparison.
English
nilenso retweetledi
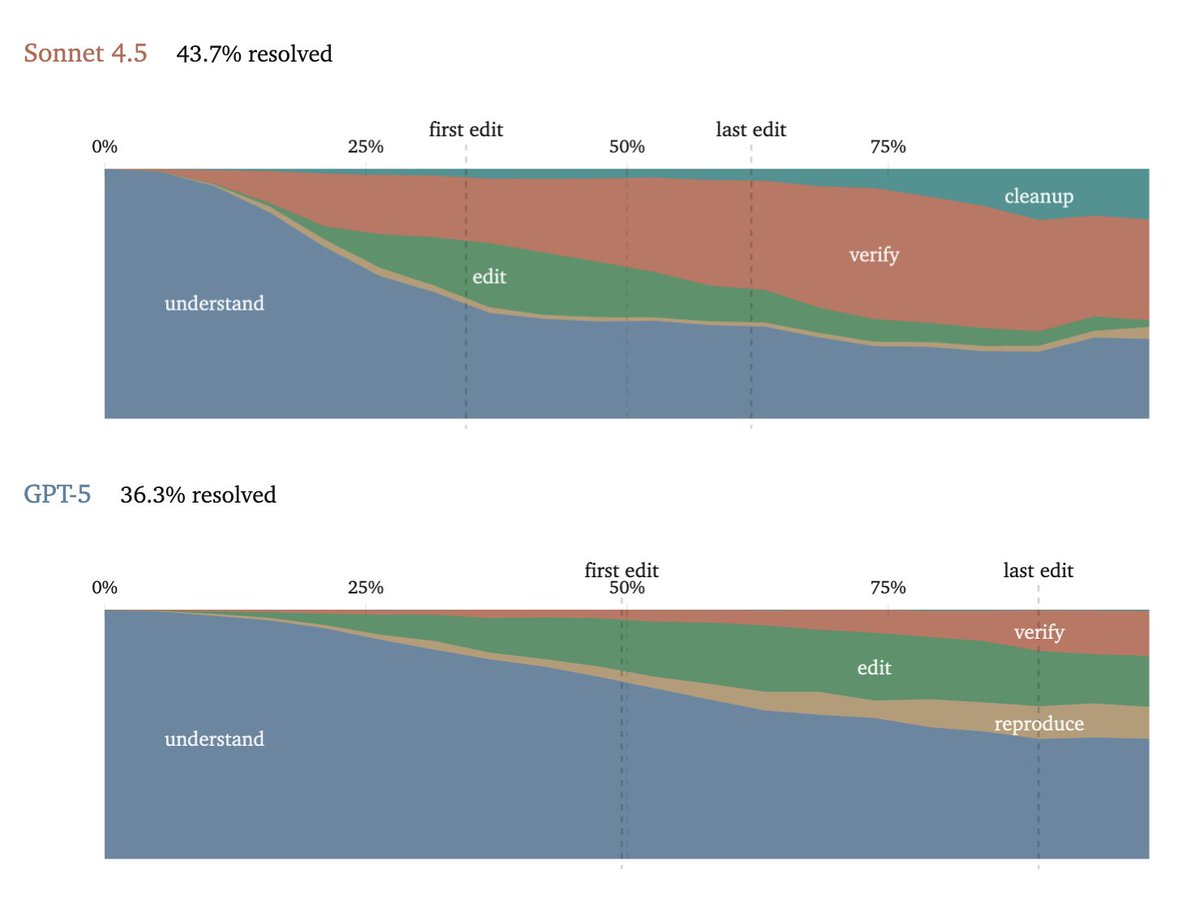
I analyzed 730 SWE-Bench Pro trajectories each for Sonnet 4.5 and GPT-5 and turned them into “trajectory shapes”: when they start editing, when they stop, how much they verify, how many steps they spend understanding vs doing.
They have very different work habits.
English
nilenso retweetledi
This was a great opportunity to bridge our industry work at @nilenso with academic research at CMU, and I am very grateful to the co-authors @heathermiller (CMU), Michael Isaac (CMU), and @AtharvaRaykar (@nilenso).
We will be in the Bay Area for the conference soon. If you are building AI tooling or want to talk shop about context engineering, we would love to connect.
English
nilenso retweetledi
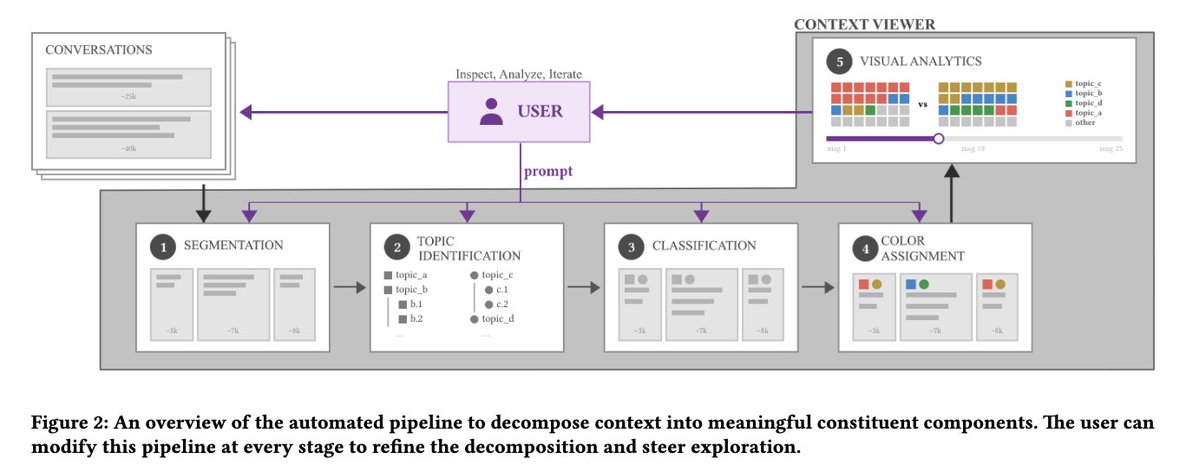
We’ll be presenting context-viewer at ACM @CAISconf!
context-viewer is an observability tool for context engineering. It gives structure to LLM contexts using classification by topics, and allows you to compare runs side-by-side. Useful for things like analyzing agent failures, token spends, and evaluating context compaction.
- github.com/nilenso/contex…
- caisconf.org/program/2026/d…

English
nilenso retweetledi

My takeaways from scanning the Claude Code code for ~45 min this evening:
1️⃣Harness engineering is hard. There's a lot of hard won knowledge in here and plenty of diagnostics to keep the feedback flowing.
2️⃣Harnesses and prompts smooth out model quirks. @SrihariSriraman and I covered this last month, but good to see it verified here. So many conditionals based on model types and specific contexts to deploy to mitigate model weirdness.
3️⃣So much of this is CLI app boilerplate. Fully expect a tool like @badlogicgames's pi to be the foundation for any CLI agent being built today.
I talk about the last point, the opportunity for shared foundations, in a post today: dbreunig.com/2026/03/26/win…
English
nilenso retweetledi
Did you know claude code has "model counterweights"? These are patches in the system prompt that exist to balance model biases.
These weren't visible earlier, but the leaked code has @[MODEL LAUNCH] annotations that call them out explicitly.

English
nilenso retweetledi
I did a compaction analysis on a couple of recent claude code sessions, and thought I'd share here too.
You can use the link to explore further if you're interested.
These are good compaction examples. I wish I could do the same analysis with some bad examples.
nilenso.github.io/context-viewer…
English
nilenso retweetledi
Somehow I didn't fully appreciate how strongly Claude Code's prompt has to fight against the weights to make parallel tool calls. blog.nilenso.com/blog/2026/02/1…

English
nilenso retweetledi

Something I've been thinking for a while, but finally got to writing it down.
The core thesis is that building reliable AI applications requires a harness to be able to tinker, experiment and iterate, without which the project gets stuck in the prototyping phase.
blog.nilenso.com/blog/2026/02/1…
English
nilenso retweetledi
Really excited for this one: @SrihariSriraman and I took a deep dive into coding agent system prompts to understand their structure, similarities, and differences. dbreunig.com/2026/02/10/sys…
English
nilenso retweetledi
I've been studying the effect of system prompts in the model + tools + system-prompts + harness stack.
So, I ran the same SWE-Bench-Pro task with Opus+Claude Code, but with different system prompts. One run used Codex's system prompt, and another run used Claude's system prompt.
The workflows on the runs are different, and mirror these kinds of sentiments. You can see the corresponding differences in the system prompts too.
We maybe mis-attributing some of these behaviours to the model, when they're attributable to the system-prompt.


English
nilenso retweetledi

Atharva Raykar from @nilenso will tell us how you're not a programmer anymore: you're coordinating a complex system. Systems thinking, feedback loops, scientific reasoning. The skills that actually matter when building AI.
Unlearning and relearning the new rules of the game.
English
nilenso retweetledi

nilenso retweetledi

nilenso retweetledi
I just published the next article in the "How to work with Product" series.
This one is called: "Taste and Adjust", and it's about finding ways to "taste" your product at every stage, by consciously building a product development flywheel.
Link: blog.nilenso.com/blog/2025/11/2…

English
nilenso retweetledi
I let Codex CLI rip over the @nilenso website code to optimise performance. It scripted a benchmark, applied some changes and reran the bench to confirm that its changes sped things up by ~5x. Our website sends ~10x less data as well.
We had been putting off the website optimisation work due to other priorities, but these days the friction to take up this kind of work is really low.
English
nilenso retweetledi
another win for bitter lesson driven development:
specialised tool interfaces -> code execution
blog.nilenso.com/blog/2025/10/1…

Anthropic@AnthropicAI
New on the Anthropic Engineering blog: tips on how to build more efficient agents that handle more tools while using fewer tokens. Code execution with the Model Context Protocol (MCP): anthropic.com/engineering/co…
English
nilenso retweetledi
Sometimes I just want to give a github url, and a prompt to semantically search. Similar to web search tools, but for Github / Gitlab.
I made a tool that does this, following @thorstenball 's "How to Build an Agent", and @nickbaumann_ 's "What Makes a Coding Agent?" blog posts. I just use Github/Gitlab's APIs instead of using the filesystem.
I use this now in storymachine because product managers or business folks don't have a repo cloned or an agentic-cli running on their machines.

English