のぶ retweetlediYahoo!ニュース@YahooNewsTopics·12 Nis【4社中核に国産AI開発会社を設立】 news.yahoo.co.jp/pickup/6575967Çevir 日本語1054271.5K962.5K348
のぶ retweetledi国立情報学研究所(NII)@jouhouken·3 Nis✏️ニュースリリース 約12兆トークンの良質なコーパスで学習した新たな国産LLM「LLM-jp-4 8Bモデル」「LLM-jp-4 32B-A3Bモデル」をオープンソースライセンスで公開 ~一部ベンチマークでGPT-4oやQwen3-8Bを上回る性能を達成~ nii.ac.jp/news/release/2… 大学共同利用機関法人 情報・システム研究機構 国立情報学研究所大規模言語モデル研究開発センター(LLMC)は、同センターが主宰するLLM研究開発コミュニティ「LLM-jp」の活動の中で大規模言語モデル(LLM)のフルスクラッチ学習を実施し、約86億パラメータの「LLM-jp-4 8Bモデル」と約320億パラメータのMoEモデル「LLM-jp-4 32B-A3Bモデル」をオープンソースライセンスで一般公開しました。公開モデルの学習では、オープンソースAIの定義(OSAID)に配慮し、第三者も入手可能な良質な学習コーパスの収集・選別・構築を行い、インターネット上の公開データや政府・国会の文書、合成データなどからなる約12兆トークンの学習コーパスを整備・使用しました。公開モデルは最大で約6万5千トークンの入出力まで処理でき、言語モデルの日本語理解能力を測る「日本語 MT-Bench」、英語理解能力を測る「MT-Bench」において、強力な多言語LLMである「GPT-4o」や「Qwen3-8B」を上回る性能を達成しています。 LLMCでは「LLM-jp-4 8Bモデル」とMoEモデル「LLM-jp-4 32B-A3Bモデル」を活用してLLMの透明性・信頼性の確保に向けた研究開発を進めていきます。また、現在、より大規模なパラメータを備えたモデルの開発を進めており、2026年度に順次公開予定です。Çevir 日本語126082K360.2K
のぶ@nobug5c9·29 Marモロッコの味噌ラーメン、ちゃんと箸が付いていた 現地の人も使うのかと店員に聞いてみると、「あれを使えたのはお前だけだ」と言われてちょっと主人公気分を味わえたÇevir 日本語008246
のぶ retweetlediRyuichiro Higashinaka@RHigashinaka·24 MarLLM-jpの研究紹介動画でモデレータを担当しました.LLM開発の現状や最先端の取り組みだけでなく,研究者たちの想いやこだわりまでたっぷり語っていただいています.👀 LLM開発に関心のある方はぜひご覧ください. youtube.com/watch?v=MceDQP…ÇevirYouTube 日本語010284.9K
のぶ@nobug5c9·9 Mar#NLP2026 で3月10日16:55 から以下の発表があります〜 VLM が扱いやすいように文書をいい感じの粒度で分けてあげる話です ぜひお話ししましょう〜! anlp.jp/proceedings/an…Çevir 日本語09573.3K
のぶ@nobug5c9·27 Şubコツコツ作っていたWikipediaコーパスが完成しました! 日本語約9,000文に、読みを含む形態素、係り受け、述語項構造などが付いています🙌(CC BY-SA 4.0) github.com/ku-nlp/Wikiped…Çevir 日本語06325116.6K
のぶ@nobug5c9·8 Eylお、よく知ってる顔が👀Çeviru++@upura0国際ニュースメディア協会の若手表彰 (30 歳以下 30 人) で、日本から 3 名が選ばれました🎉 特に NLPer の 2 人の受賞理由には「言語処理学会論文賞 / ModernBERT / EMNLP / hallucinations」などがあり、ニュース業界での NLP の存在感と期待の大きさを改めて認識しました。 inma.org/blogs/main/pos… 日本語0061.3K
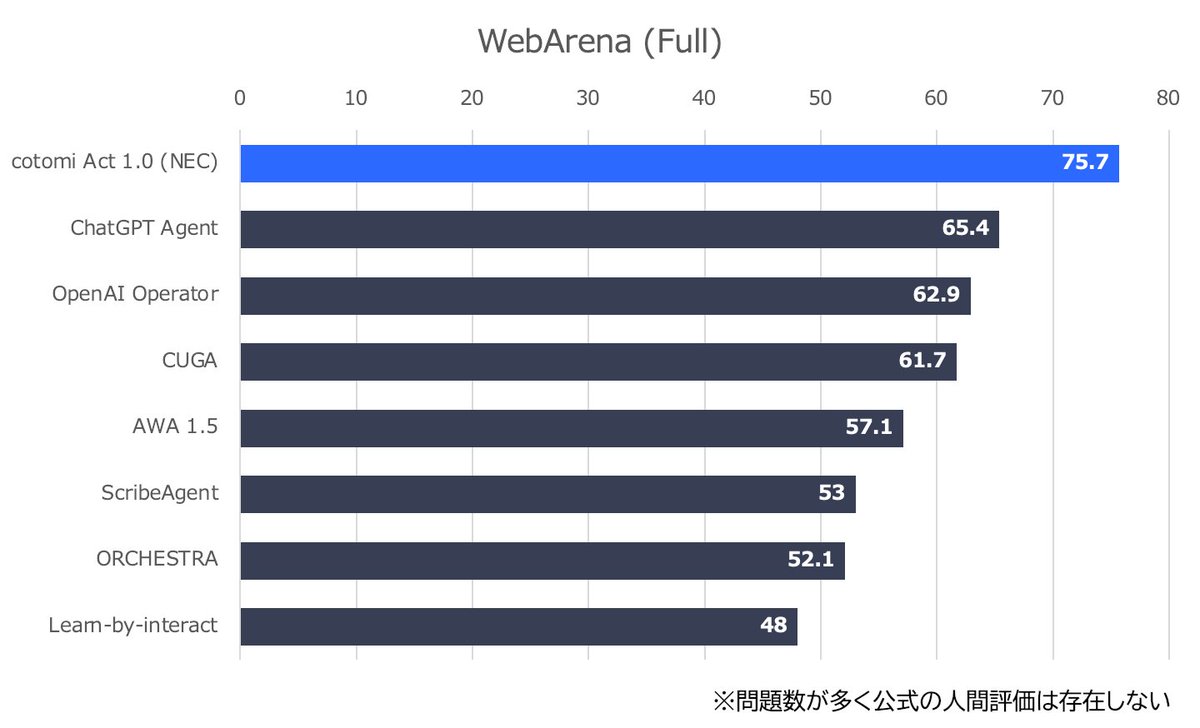
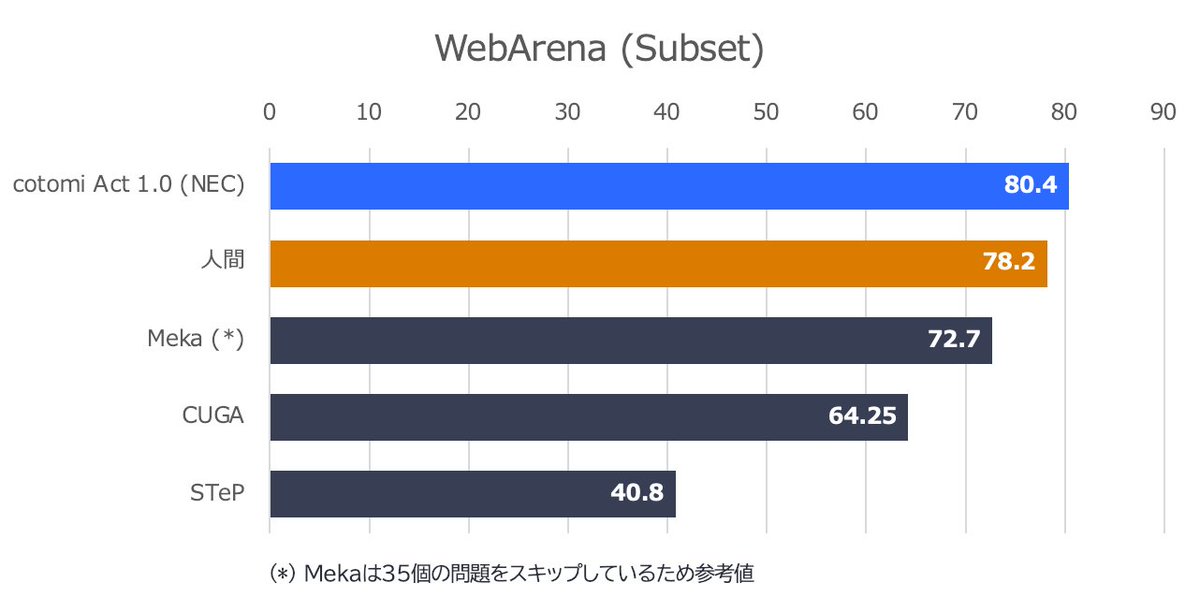
のぶ retweetledimooz@stillpedant·27 AğuWebブラウザを人間よりも高い精度で操作することに(世界で初めて)成功しました! 今回、開発した cotomi Act というエージェント技術はWebArena というWebエージェントのベンチマークで8/27現在、人間も上回って世界トップ性能の実現に成功しています。 jpn.nec.com/press/202508/2… 🧵Çevir 日本語2110764122.4K
のぶ retweetledimooz@stillpedant·21 Ağuチームの仕事が NAACL’25, COLM’25, EMNLP’25 と連続して採択されたので、解説・宣伝してみます(例によってめちゃくちゃ長い)。 我々は cotomi というLLMを楽しくも苦しみながら作っているのですが、特に大変なのは事後学習。 これはベースモデルに対して 「どんなデータをどんな手順で入れるか」 「どんなモデルをマージするか」 みたいな施策を人間が考え、実施し、品質をチェックし、一喜一憂を繰り返すフェーズで、はっきりいえば 労働集約の塊 な営みです。LLMのリリース前は深夜まで無数のモデルの結果を眺めて「うーん」というのを繰り返す、なかなかストレスフルな日々が続きます。 そんな労働集約な「LLM開発自体」を 「LLMやML技法の活用で改善できないか?」 というのが今回の3つの研究に共通するモチベーション。ドッグフーディング的な研究ですね。Çevir 日本語11913025K