
核桃壳(观星者) | hetaodao.eth
1.5K posts



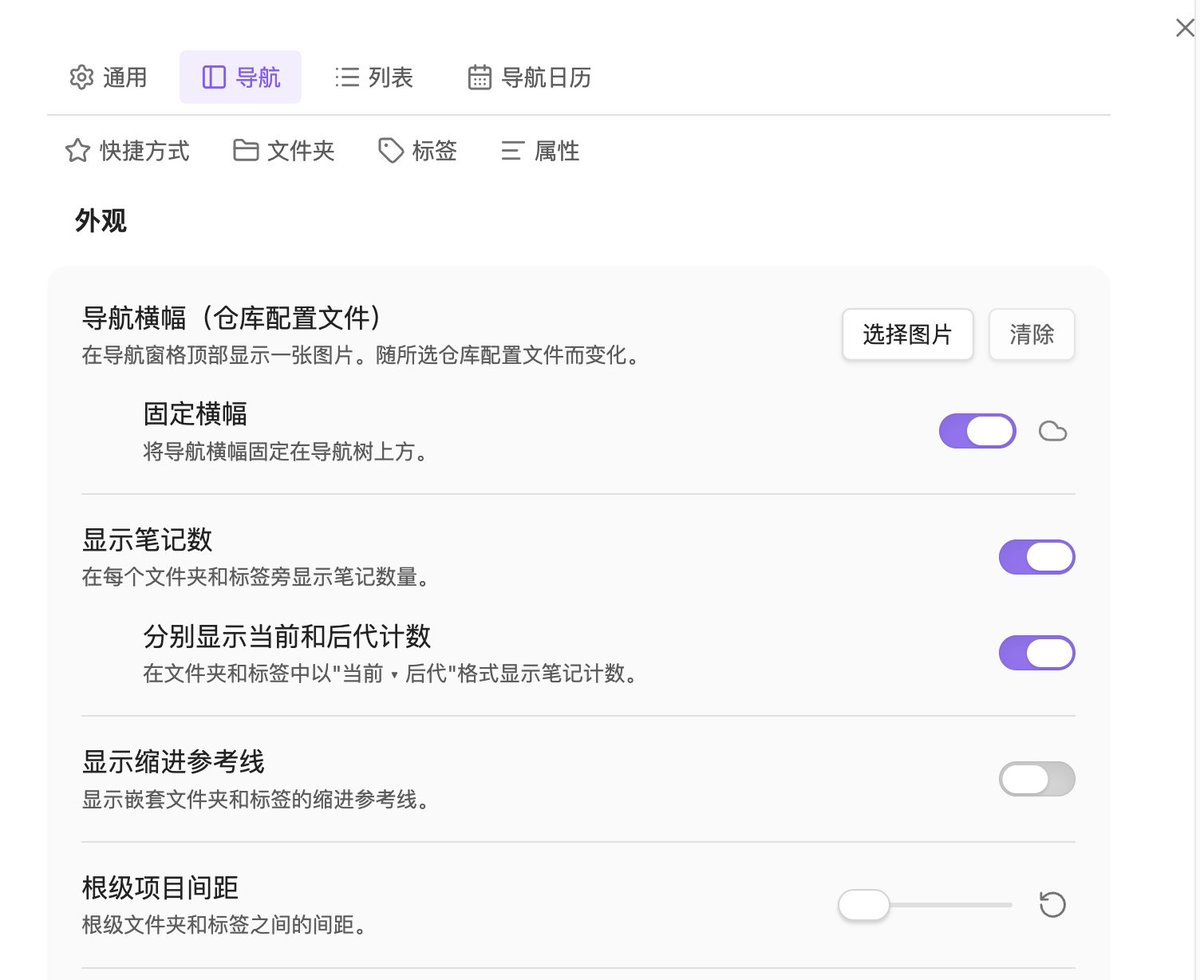



@st7evechou 这是你的嘛?还是只是在腾讯那里暂存一下?还是所有权是腾讯的,你只是拥有使用权,是否收回,是否合规还是在腾讯手里?
中文




截至2026年5月2日,央视尚未正式宣布放弃2026美加墨世界杯转播权,但谈判已陷入僵局,大概率不会签约。
核心分歧:价格天差地别
国际足联要价:2.5-3亿美元(约18-21亿人民币),比上届卡塔尔世界杯(1.5亿美元)大涨约60%。央视出价底线:6000-8000万美元,双方差距超过2亿美元。涨价理由:本届扩军至48队、场次从64场增至104场、赛期39天。
央视拒绝的关键原因
市场价值不匹配。国足缺席:连续6届无缘世界杯,全民关注度断崖式下跌。时差致命:北美与中国时差12-15小时,70%比赛在凌晨2-6点,非黄金档,广告价值低。
公共媒体理性决策。国有资金需精打细算,不能为天价泡沫买单。2022卡塔尔世界杯央视广告收入约50亿人民币,扣除成本后利润有限,本届成本翻倍,风险极高。
定价不公,对比悬殊。印度两届世界杯打包仅500万美元,中国报价是其50倍以上。国际足联将中国划为与美英同级的顶级市场,定价脱离中国实际。
央视态度坚决:不接受不合理天价,宁可不播,也不当冤大头。
中文

Codex 的新增的“goal”太好用了!
已经连续干了 7 小时活、消耗了 3 亿 Token 了,是我目前最高的连续不中断让 AI 干活的记录。
不停地完成任务、审计任务这样循环下去,非常仔细。不用再看到「需要我为你做下一步吗?」真的太好了。
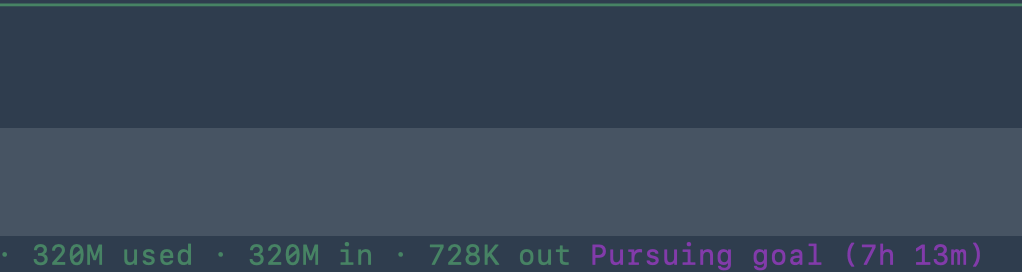
图拉鼎@tualatrix
iPad mini 才是最好的监控面板。让 Mac 上的 Codex 在终端执行 /goal 跑长任务,然后投屏到 iPad mini 监控,已经“Pursuing goal”31分钟了!
中文

/goal also lands in Codex CLI 0.128.0.
Our take on the Ralph loop: keep a goal alive across turns. Don't stop until it's achieved.
Built by my co-worker and OpenAI mentor Eric Traut, aka the Pyright guy. One of the GOATs I get to work with daily.
English
@Meta8Mate 人的欲望是有极限的 上次是第一次用黄网的AI聊天 几天就聊尽了 现在是coding 最多几周就把需求做完了😂
中文

OpenClaw/Vibe Coding用的有点到瓶颈了。
之前买的4个MAX账号,基本上每周都能打满2个100%,
最近几周都是平均用个20%~40%就顶天了。
大家用了AI之后,有没有感觉人脑更累了,
仿佛吃了伟哥揠苗助长,身体被掏空。

中文
@deepseek_ai Take my data and give me a bigger discount.
English

The DeepSeek-V4-Pro discount has been extended until May 31, 2026, 15:59 UTC!
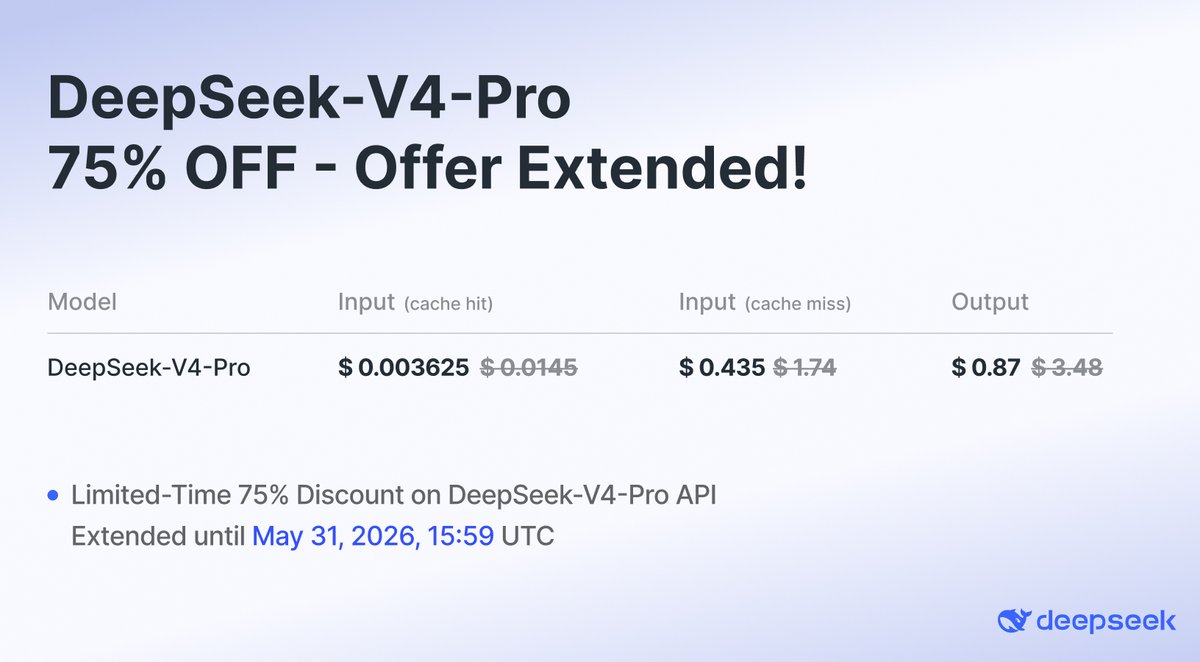
DeepSeek@deepseek_ai
🔥DeepSeek-V4-Pro API is 75% OFF until May 5th, 2026, 15:59 (UTC Time)! Don't miss out on this massive discount. 🛠️Integration Updates: 🔹Claude Code: Set model to deepseek-v4-pro[1m] to unlock 1M context! 🔹OpenCode: Update to v1.14.24+ 🔹OpenClaw: Update to v2026.4.24+ Check the latest official API docs for full details: api-docs.deepseek.com/quick_start/pr…
English

不得不佩服国内的云服务商,自己折腾一天没把 Openclaw 恢复,心想着试试 Hermes ?
一看配置教程好麻烦,于是直接用腾讯云现成的,发现居然还可以用微信联系,全程只用了10分钟搞定,这两天测试一下,模型给配了 Gemini 3.1 Pro……

Crypto_Painter@CryptoPainter
刚才一不小心更新了Openclaw,结果... Gateway打不开,进程秒断,搞了半天发现无法修复后,忍痛宰了这只养了3个月的龙虾... 清蒸的,还加了蒜蓉...
中文
@manateelazycat 1. 付费的用户才能带来高质量的输入。
2. 最初的定价参考了国外的定价,但发现用户太少,所以直接降价吸引。
3. 但免费的话,垃圾用户太多,养龙虾的人也多是垃圾数据,所以一定得收费
中文

不是,DeepSeek 你怎么回事,降价的基础上还能降价???
百万 Token 的缓存命中价格从0.25元直接降到 0.025元。
太狠了🥲
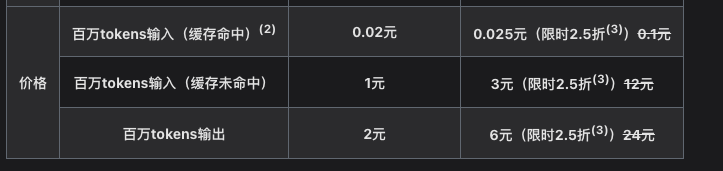
Andy Stewart@manateelazycat
还是 DeepSeek 凶猛啊,你们不是嫌我贵? DeepSeek V4 Pro 2.5折活动启动!🤣 真铁血硬汉子!
中文





🔥DeepSeek Input Cache Price Drop!
Effective immediately, the price for input cache hits across the ENTIRE DeepSeek API series is reduced to just 1/10th of the original price! Build more efficiently for less.
📌Reminder: The DeepSeek-V4-Pro 75% OFF promotion is still active until May 5th, 2026, 15:59 (UTC Time).

English
DeepSeek V4 发布且降价后(还有Kimi2.6),GLM 5.1 倒是不用抢了。之前这个时间点应该就已经售磬了

中文

几十分钟,完成百万字长篇小说!!!
最近发现了一个长篇写作助手,叫autonovel!
基于Ling-2.6-flash 极限速度,可覆盖世界观设定、角色构建、大纲生成到正文创作的全流程,200+ tokens/s的生成速度!
实测几十分钟就写完百万字长篇小说!!
沐阳@yyyole
自从马云重新现身后, 蚂蚁集团一直猛冲AI,大动作不断! 像是卯足劲在追赶阿里QWEN! 最近更是连发两款实用拉满的模型!!! 先是百B级的 Ling 2.6 Flash, 盲测阶段就冲上 OpenRouter 趋势榜第一, 直接火到了海外!! 还不算完,@AntLingAGI 今天又甩出一张底牌: Ling 2.6 1T ! 名字就能看得出来,这个模型能力会更强!! 但有一个误区:能力强的不一定是思考模型! Ling 2.6 1T 不靠拉长推理链条来显得"很聪明", 而是把 token 更多花在理解、规划和输出上。 换句话来说: 它的核心定位,是面向复杂任务,是精准指令下的执行模型!! 1M 超长上下文,能把会议纪要、群聊记录、项目文档、零散资料一次性扔进去统一处理。 强工具调用能力,可以接进 OpenClaw、Hermes、LangGraph、Dify 等跑工作流。 真实问题处理,不只生成漂亮 demo,而是能够读懂已有代码,按照你的要求去干活。 Token 效率更高,不默认展开超长思考,成本控制到最低。 最近一段时间都是免费用,不用白不用, 我拿了几个真实任务跑了一遍,感受超级明显—— 如果是模糊的指令,它可能不太适合。 但如果是比较详细的指令,给它一个工作流, 就完全起飞了!! 没有了推理过程,感觉非常丝滑, 这一点,就挺重要的!! 减少了很多“AI自作聪明”的麻烦!! 说回蚂蚁这两款模型, 完全是冲着落地应用来的,几乎把简单和复杂的应用场景全部包圆。 1T 负责理解复杂目标、拆解任务、整理材料、制定计划。 Flash 负责快速执行、快速改写、快速补全。 这精准切入了现在大多数人用AI的“痒点”: 总想着用一个“最强模型”解决所有的事情。 但我认为真正重要并且正确的是: 让对的模型干对的事。 这样无论是速度、成本、还是结果一致性,都更能符合预期。
中文









“中国发明的美国免费福利”
TikTok上一个博主发了条视频,内容是“中国发明的美国免费福利”——你可以理解为中国人都中了哪些读者意林的毒。
她念道:
“中国人以为每个美国人都有高收入;生活成本又非常低;
美国人有很多福利;美国的教育和医疗都是免费的;税收还非常低;
一个美国人每周只需要工作40小时就能供养一个3、4个小孩的家庭;
如果不想工作也没关系,没关系,政府会完全照顾你;
每个美国人都有半年的假期;
政府极其清廉,没有腐败;”
念到“说免费教育和医疗”和“政府没有腐败,连总统儿子都要去快餐店打工”的时候,该博主笑得像个疯子。
中文


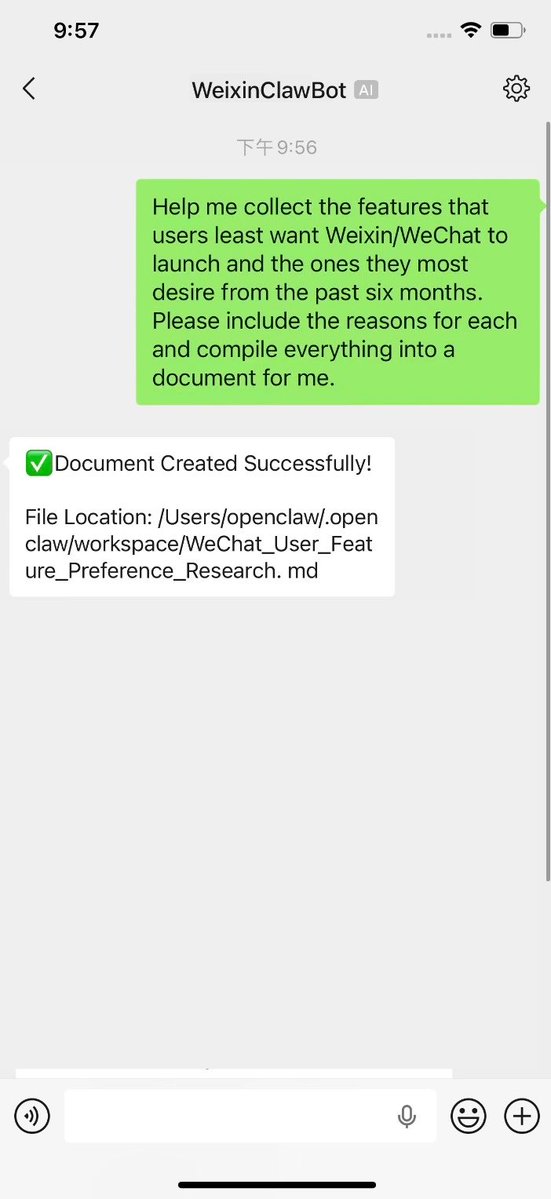
Today, we are officially opening the capability to integrate #OpenClaw into #Weixin.
With the launch of the #WeixinClawBot, users can use Weixin as a dedicated messaging channel for OpenClaw.
Now, you can send and receive messages with OpenClaw just like texting a friend.
#AIAutomation #AI

English