Sabitlenmiş Tweet

everyone’s cramming AIs with more tokens, bigger context, and longer prompts thinking it’ll make them smarter
reality? it usually backfires. hard.
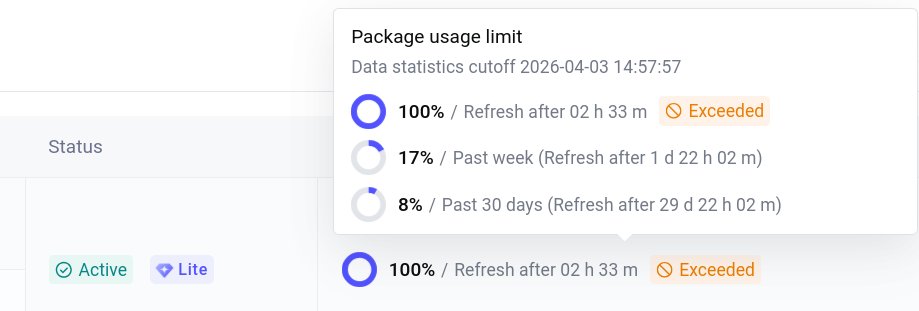
121 experiments: Kimi found 4 bugs at 16k tokens… and zero at 48k.
ntorga.com/overfed-overth…
English