Sabitlenmiş Tweet

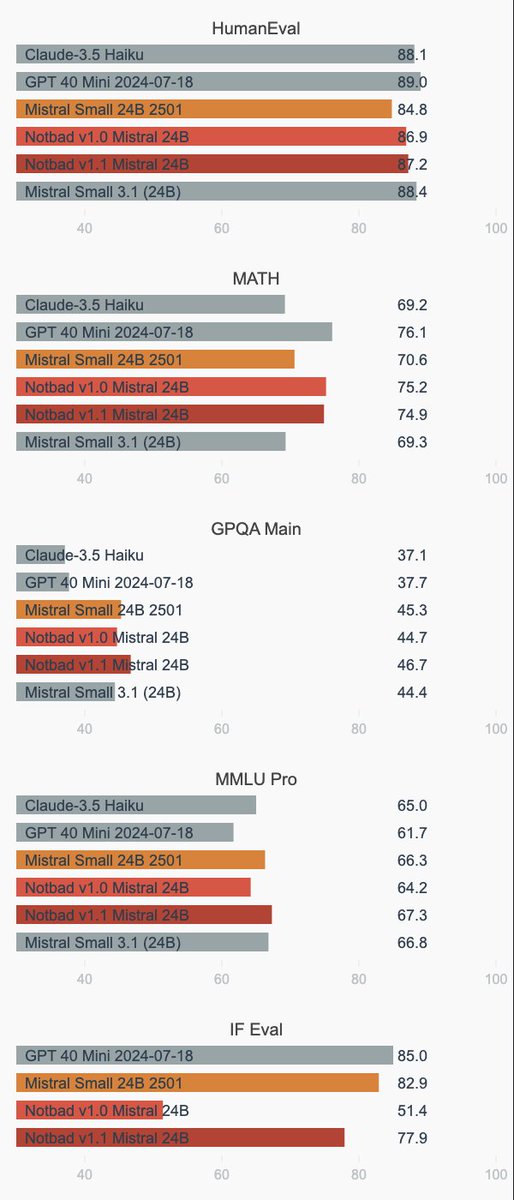
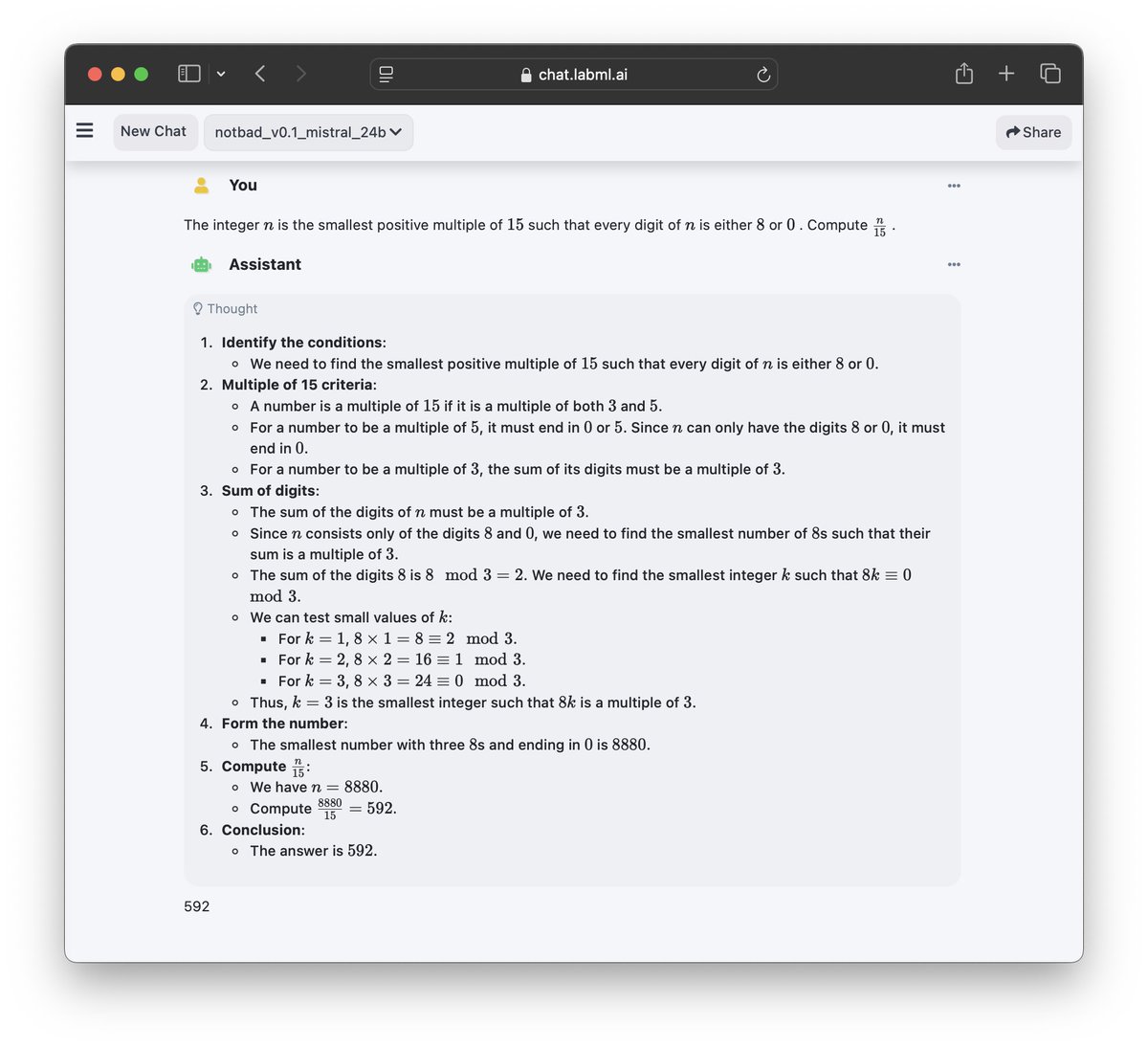
We've open-sourced our internal AI coding IDE.
We built this IDE to help with coding and to experiment with custom AI workflows.
It's based on a flexible extension system, making it easy to develop, test, and tweak new ideas quickly. Each extension is a Python script that runs locally.
(Links in replies)
🧶👇


English