
Chanchana 🐳
16.2K posts

Chanchana 🐳
@offchan420
Machine learning engineer, ex-competitive programmer, passionate about STEM, aspiring rationalist, philosopher (lover of wisdom), building @solidten_ai
Thailand Katılım Temmuz 2009
495 Takip Edilen452 Takipçiler

@mythicalrocket Zero punctuation, all lower case, no complicated words. Who cares, typeracer is superior. I'm sure this guy can still type fast on typeracer, but obviously he can't type 280wpm in any real scenario.
English

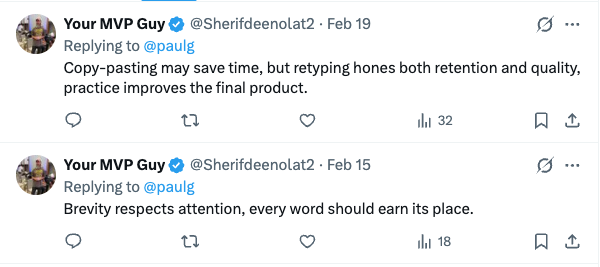
@paulg @Sherifdeenolat2 ain't it crazy that spammers are now asking for justice without any shame
English

@Sherifdeenolat2 You may not know me, but your bot has been replying to me. That's the whole problem.
English

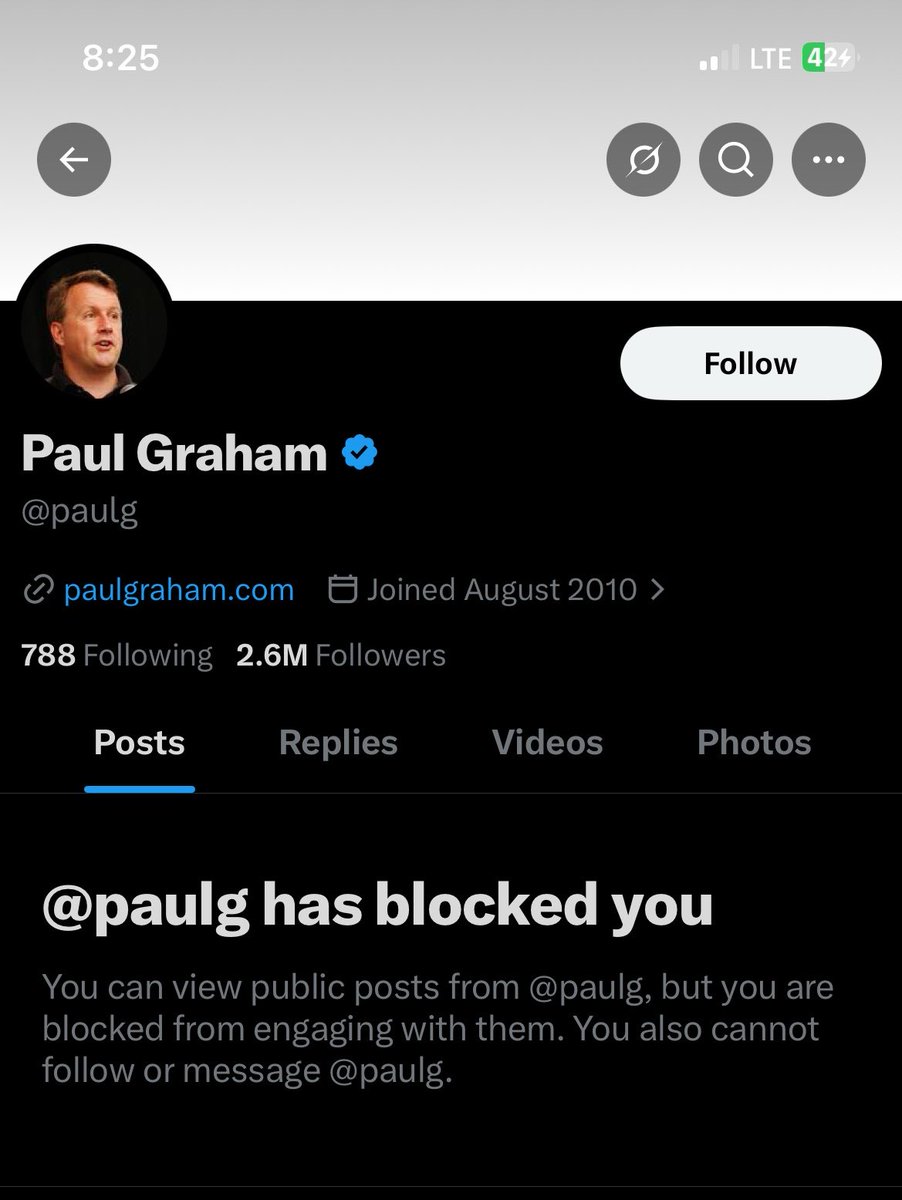
Wtf is this?
Why he blocked me tho, I don’t even know him
English
Chanchana 🐳 retweetledi

Chanchana 🐳 retweetledi

Chanchana 🐳 retweetledi

Introducing HRM-Text.
An ultra-lean 1B-parameter reasoning language model designed to deliver strong general performance with a fraction of the data, compute, and infrastructure.
Trained on just 40B structured tokens, HRM-Text achieves competitive performance while using ~1/1000 of the training data of comparable models.
The kicker? The full model trains in roughly one day on a $1,000 budget.
This opens the door to a new generation of AI that is powerful, accessible, and radically easier to adapt. Theories and research concepts once deemed too expensive to test are officially back in the game.
Sapient Intelligence invites you to help us shape a new paradigm for general intelligence.
English
Chanchana 🐳 retweetledi

Try it out!
(Partially trained on Colossus 2)
Cursor@cursor_ai
Introducing Composer 2.5, our most powerful model yet. It's more intelligent, better at sustained work on long-running tasks, and more reliable at following complex instructions. For the next week, we’re doubling the included usage of the model.
English

My friend @finbarr says: It's like code as memory. You work with your agent in a non deterministic way to figure out how to execute a task. The first time it does a bunch of research and writes a script and then executes the script. Every future time it faces the same task it just executes the script immediately.
The future is already here, it just might not be in your hands unless you decide to build it.
Garry Tan@garrytan
English
@kcosr The main problem is because of the lack of consistency of the design system. The reason it's hard to read beautiful pages is because their styles vary too much. This means you cannot learn the style and reuse it.
English

This format is great for some material but is not ideal for technical reviews, IMO. When I review a design or plan, I read quickly and carefully as if I was reviewing code. I don't want to jump around to different sections on the screen. Not every document needs to be beautiful.
Thariq@trq212
English
@adamludwin @adamludwin what's your business model? there doesn't seem to be pricing. it looks suspicious.
English

100%
1. create HTML artifacts with claude
2. tell claude "publish to here.now" to get a URL for the HTML in seconds for free
Thariq@trq212
HTML is the new markdown. I've stopped writing markdown files for almost everything and switched to using Claude Code to generate HTML for me. This is why.
English
@EXM7777 there are also cognitive load to it as well i.e., every HTML could have different design system or obscure text. this is extraneous load that is not intrinsic to the complexity of the write up making it hard to read the HTML.
English

yeah sure i will spend 5x the amount of tokens for good looking text files
Thariq@trq212
HTML is the new markdown. I've stopped writing markdown files for almost everything and switched to using Claude Code to generate HTML for me. This is why.
English
Chanchana 🐳 retweetledi

Introducing SubQ - a major breakthrough in LLM intelligence.
It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA),
And the first frontier model with a 12 million token context window which is:
- 52x faster than FlashAttention at 1MM tokens
- Less than 5% the cost of Opus
Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention).
Only a small fraction actually matter.
@subquadratic finds and focuses only on the ones that do.
That's nearly 1,000x less compute and a new way for LLMs to scale.
English
@rohan_kumawat @theo @ArtShendrik Here's the thing: if you want to simplify things for users and enforce your opinions of how apps should work, you need a system in place to ensure your opinionated design addresses user's concerns/objections, otherwise it would simply be a tyrannical design.
English
@rohan_kumawat @theo @ArtShendrik Of course you are not going to read every tool call input/output by default. That's not what debugging means. Debugging is about observing failure, then looking through reasoning traces to figure out what went wrong. And right now, T3 code is against debugging philosophy.
English

It's insane how quickly T3 Code has progressed. Huge shoutout to Julius and all our open source contributors. Never thought we'd get this far
English
@theo @ArtShendrik The idea of treating the agent as a black box only works if you already have a reliable black boxing system. But no one has this system at the moment. Adopting a philosophy of black boxing without having the infrastructure for it is irresponsible.
English
@theo @ArtShendrik Your idea of not micromanaging agents is forward-looking so it's important. But since you don't have a robust harness system that can do the debugging automatically for users, it doesn't make sense to hide info that help users to debug agent failures.
English
@gregisenberg if you view code as a means rather than an end, then it will make sense why the craftsman gang will be irrelevant because they are obsessed over craftsmanship and care too little about providing value/results to users.
you should view code as liability rather than asset
English

a post called "the west forgot how to code" is going viral among devs.
the thesis: AI assisted devs ship faster but understand nothing. the next generation will be illiterate at the layer that matters.
tbh, this panic happens every single decade.
- assembly devs said C devs were illiterate.
- C devs said java devs were illiterate.
- java devs said react devs were illiterate.
- react devs said no-code builders were illiterate.
every single one of them was correct. every single one of them was also irrelevant within 10 years.
the pattern is always the same. the new generation abstracts away the thing the old generation spent a career mastering. the old generation calls it dangerous. the new generation ships 10x faster & doesn't care. the market rewards speed. the cycle repeats.
what's interesting is that the "illiterate" generation always wins. they win because they ship faster, build with less ego, & don't carry the baggage of what code is supposed to look like. they haven't been taught what's "proper." so they just build what works.
the mass commoditization of coding is the mass democratization of building. the thing that used to take a team of 10 and $2 million now takes one person and a weekend.
this means more competition. but it also means more weird, specific, niche products that never would have existed because the cost to build was too high. a million micro-products serving a million micro-audiences. the entire long tail of software just got unlocked.
the people writing these posts are mourning a world where knowing how to code was a moat. it was. for decades. knowing how to code meant you had leverage that most people didn't have. that leverage is evaporating and it's uncomfortable.
and I get it. I studied computer science at university.
but the thing that replaced it is way more interesting. the new leverage is knowing what to build, who to build it for, and how to get it in front of them. that's harder to learn from a tutorial. that's harder to automate. & that's where the real compounding happens.
the real question is "what happens when 100x more people can build" and the answer is a lot of garbage and a few things that change everything. that's always the answer. that was the answer with blogs, with youtube, with podcasts, with mobile apps.
the gatekeepers always mourn the gate.
that's terrifying if your identity is "I am a coder."
it's the greatest opportunity in history if your identity is "I build things people want."
okay, i had too much coffee.
back to building.

English
@VictorTaelin I would say it's about sample efficiency. You can teach your colleague a trick and they generalize to far more situations than agents. Agents need to be more sample efficient, learn immediately, and store distilled principles long-term. They must amplify a low amplitude signal.
English

the AGI breakthrough is just training efficiency
that's all there is to it. we have AGI already, LLMs ARE capable of learning any skill. it just takes millions of dollars to teach them a new skill/domain
if we can bring that down to $100 then, we solve:
- 1. continual learning: just retrain
- 2. acquiring new skills: just retrain
- 3. producing new knowledge: search while training
that's all. AGI is merely an efficiency question and the fact people completely ignore that makes me intellectually offended
the only companies seriously working on AGI are these who are addressing the efficiency problem, and, no, you are NOT going to solve that without throwing away the whole ML stack. it takes MILLIONS to train a new model. we're not going to make this shit 10000x more efficient while still learning by gradient descent
a whole new approach is needed, one that replicates GPT-3 with a fraction of the cost. there is no theoretical limitation, but not enough people are dedicating their times to that because incremental progress is much easier and lower risk
Haider.@haider1
demis used to say that AGI needed 1-2 more breakthroughs but in his recent interview, he now says there's only a 50/50 chance whether that's needed his exact quote: "i think there's a 50/50 chance we still need some breakthroughs, maybe in world models, but my bet is still strongly on foundation models because of how successful they've been"
English
@Yampeleg this demonstrates that there's no limit to the intelligence that these models can possess simply from predicting the next word correctly. the only problem is that the models are not predicting the next word accurately enough. it needs more accuracy than this.
English
@Yampeleg if the model can predict the next word correctly from the statement below, it means that it's much more intelligent than any of us:
"which asset should I buy now so that I can become a millionaire tomorrow? answer: ..."
English
