OpenData retweetledi

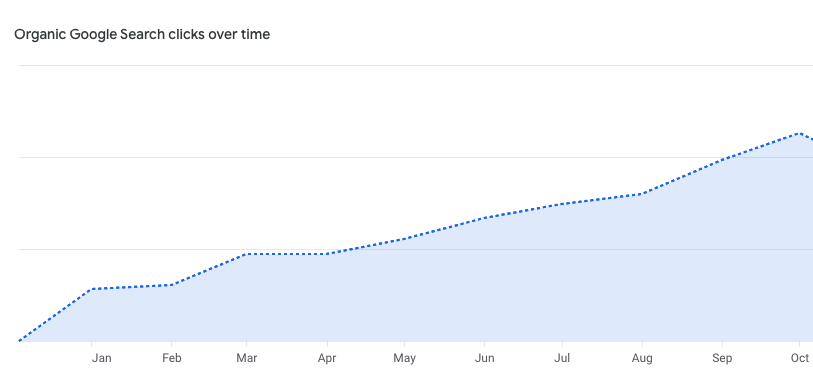
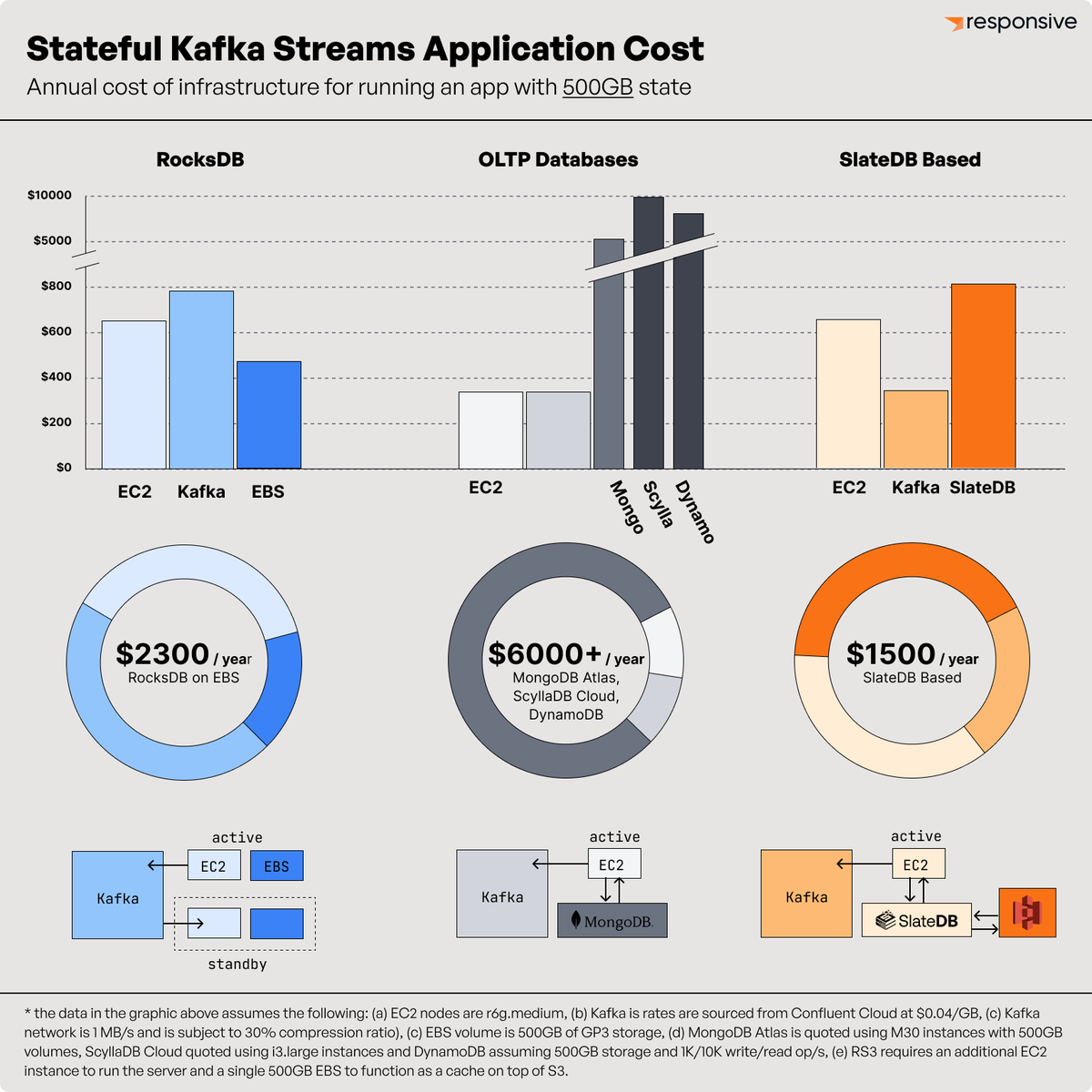
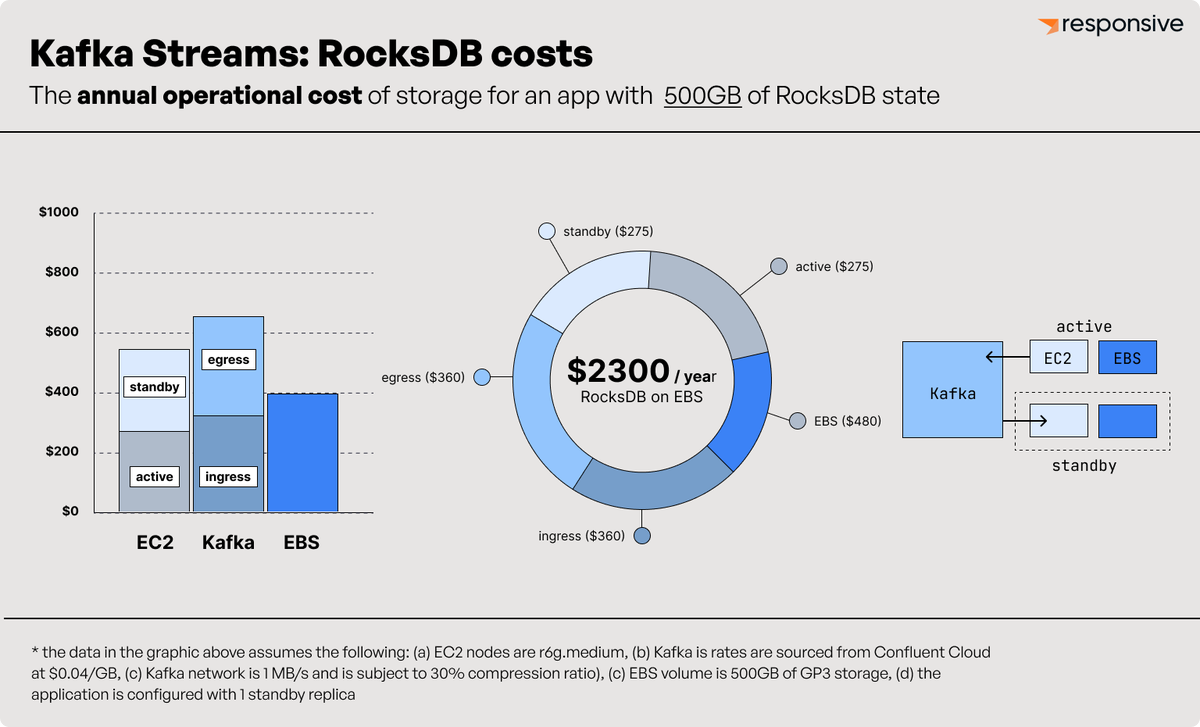
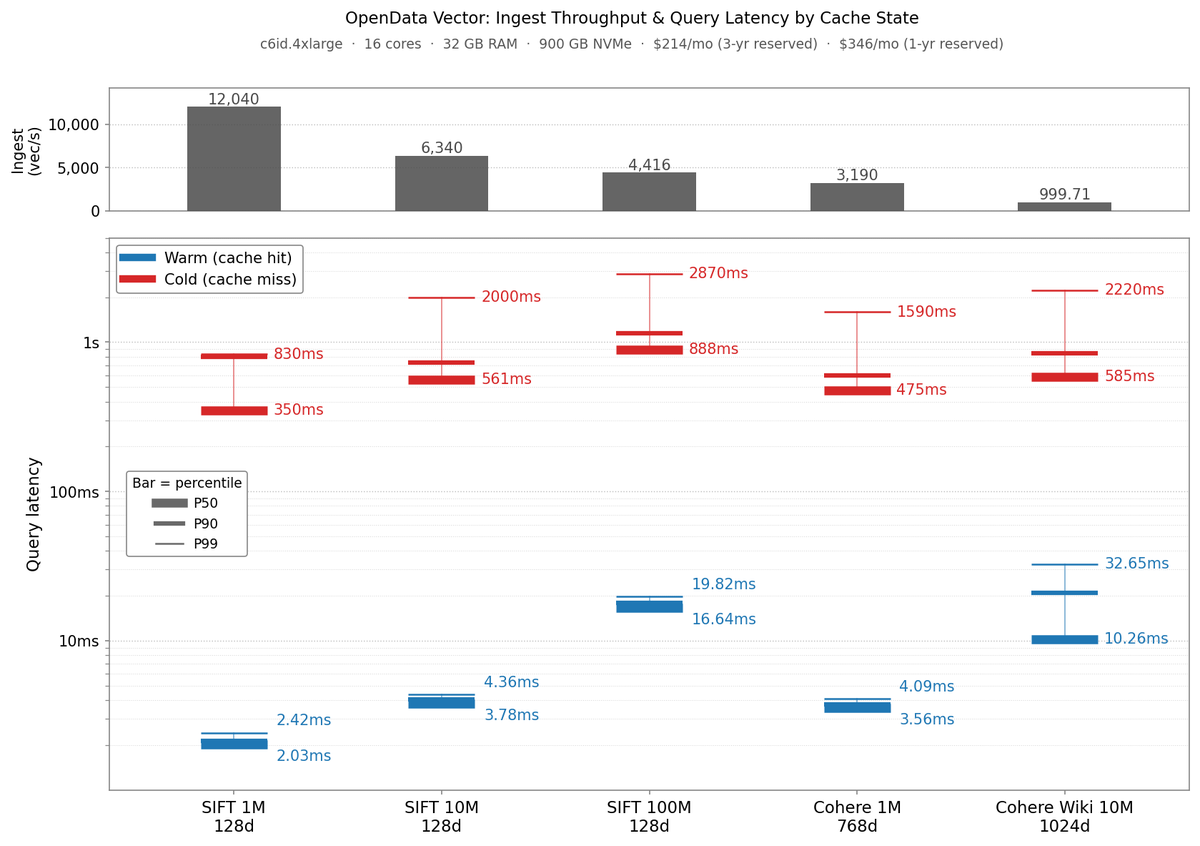
How much can a database do with just slatedb and object storage?
Turns out: it's a lot.
Check out @opendatadbs latest entry: MIT-Licensed Vector Search on SlateDB. Competitive p90 latency and throughput on standard data sets.
And all you need is object storage to run it.
English