Peter O'Hearn@PeterOHearn12
LLMs vs the Halting Problem. (Why, what, where going.)
We recently released a paper on this; link to follow. A few comments here for context.
Why? With LLM "reasoning" excitement, we thought: why not try LLMs on the first ever code reasoning task, the halting problem. Turing's proof of undecidability
established fundamental limits. Fun bit: no matter how "superintelligent" AI becomes, this is a problem it can never perfectly solve.
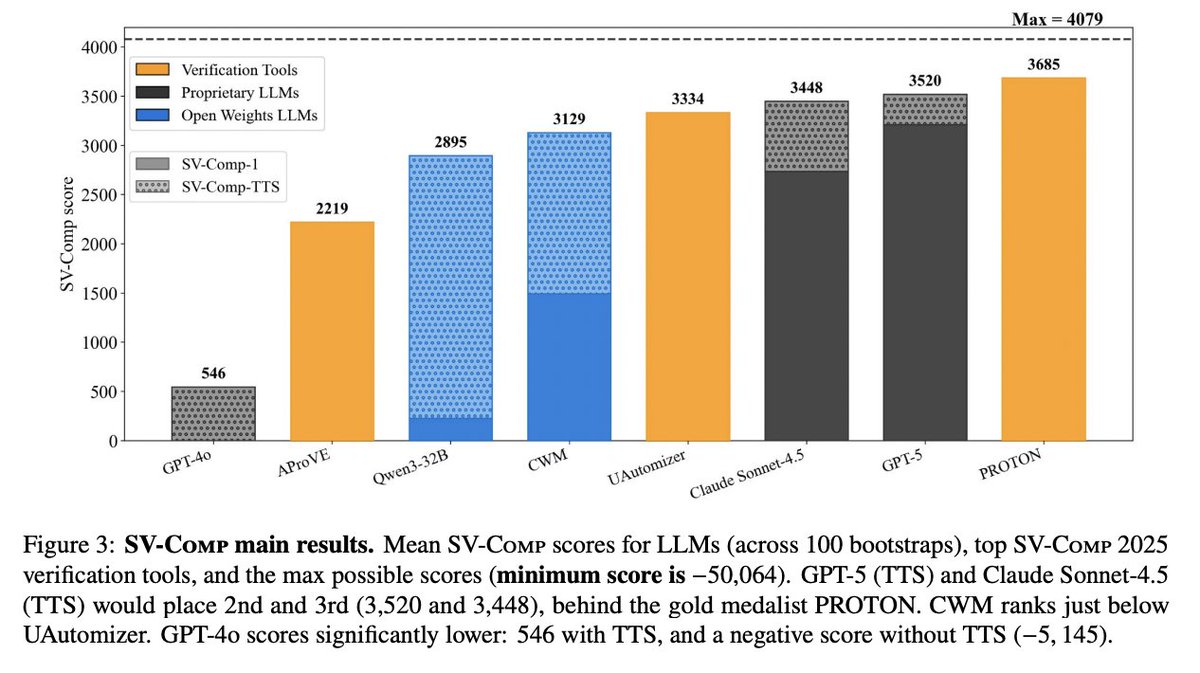
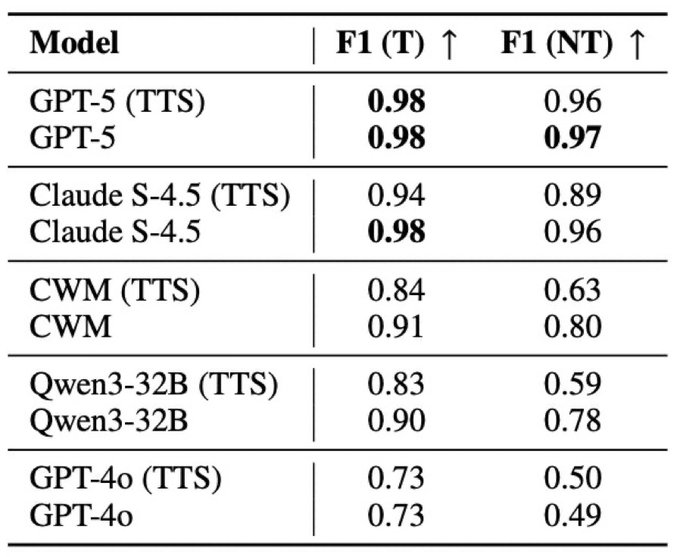
Where to get data to measure? SVCOMP. Verification researchers have through their insight and hard work, curated several thousand example C programs. They run dedicated tools over this dataset in an annual competition. This is in a sense the home turf of symbolic. We didn't know how LLMs would do, and in particular were aware of results of @rao2z , @RishiHazra95 and others showing that LLMs trail symbolic on "easier" decidable problems (SAT, propositional planning).
The surprise: LLMs are competitive on halting—where they often trail on "easier" problems. Why? Hypothesis: LLMs are heuristic approximators; in undecidability, heuristic approximation isn't just a workaround—it's often the only way forward.
Broader context: Penrose claimed undecidability proved AI is impossible (but didn't show humans can solve the undecidable). Turning the tables: undecidability is an ideal target for heuristic LLMs. Instead of using "already crushed" logic problems to show LLM limits, let's look at uncrushed problems where LLMs might actually help.