Ivan Oseledets retweetledi
Ivan Oseledets
615 posts

Ivan Oseledets
@oseledetsivan
Professor at Skolkovo Institute of Science and Technology; Working on linear algebra, tensors and deep learning.
Moscow Katılım Ekim 2010
407 Takip Edilen614 Takipçiler

@KirkMSoodhalter Just making sure, you know who actually Krylov was? A tough man indeed.
English

Nothing stands in the way of Krylov or his methods. He will project you down into the two-dimensional subspace of the ground.

English
Ivan Oseledets retweetledi

“Tensor networks in machine learning” (intro/tutorial).
Will appear in
@euromathsoc
With Sengupta, Adhikary and
@oseledetsivan
arxiv.org/abs/2207.02851
English
The results of sanctions are absolutely the opposite. Now we have 90% of Putin support instead of 60% before, and they will blame not the Russian government. And this is a pure nationalism (to reject people based on their nationality or citizenship).
English
Ivan Oseledets retweetledi

Here are three ingredients for metric learning SOTA: hyperbolic embeddings, vision transformer & contrastive loss. Pretraining is also important, this is a moment to shine for self-supervision. #CVPR2022 paper w/ Leyla, @vforvalya1, Nicu and @oseledetsivan arxiv.org/abs/2203.10833
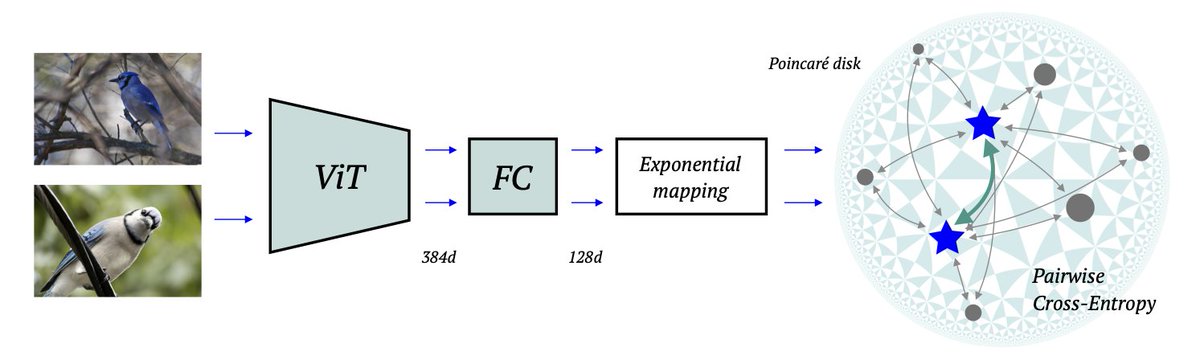
English
@eeevgen @wellingmax I will! Very difficult to find the right words.
English

@oseledetsivan @wellingmax Please write the same in Russian, in Facebook. Otherwise it looks like we have two different Ivan. One gets likes from Russian propagandists. My opinion is nothing. But your anti-war opinion is important.
English
Some time ago @wellingmax posted about the Russia attacking Ukraine. For me, it was absolutely unimaginable. I was horribly wrong, and this whole situation is completely heartbreaking. It will have consequences inside Russia, I am pretty sure.
English
Yes, it was me, and it is exactly about what I wrote in this twitter post. Thanks for copying.
Michael Bronstein@mmbronstein
@oseledetsivan @wellingmax @oseledetsivan wasn’t it you who wrote that you were “sympathetic with the Russian leadership” “understanding the arguments of Putin” in the recognition of DNR/LNR?
English
@s_scardapane @atilimgunes @BAPearlmutter In fact, the parameters are updated as p_{k+1} = p_k - c_k v, where v is random, and c_k is directional derivative (can be approx. as f(p + eps*v) - f(p)). Thus, it is more or less a random search method (move in a random direction).
English

Backprop computes gradients with a technique called reverse-mode autodiff, which is heavy memory-wise.
The alternative (forward-mode autodiff) requires less memory, but it's infeasible in practice.
See the seminal survey by @atilimgunes @BAPearlmutter:
arxiv.org/abs/1502.05767
English
*Gradients without Backpropagation*
by @atilimgunes @BAPearlmutter et al.
Since everyone in my small bubble is talking about this paper, let me do a quick dive. 👀
🧵
arxiv.org/abs/2202.08587
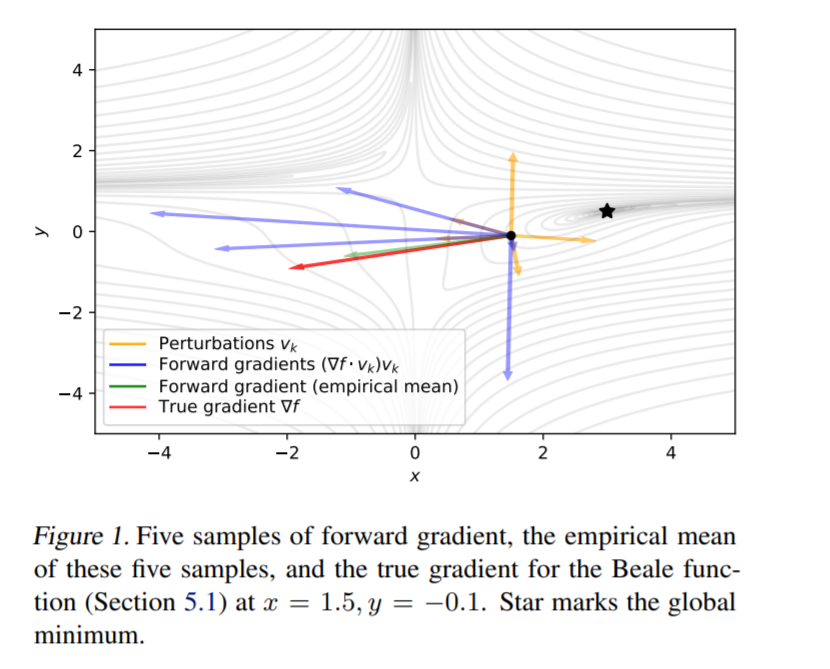
English
Ivan Oseledets retweetledi

Check our latest ICLR'22 paper "When, Why, and Which Pretrained GANs Are Useful?" by Timofey Grigoryev, Artem Babenko, and myself. TL;DR: GAN initialisation is all about recall and Imagenet pretraining rocks.
arxiv.org/abs/2202.08937
github.com/yandex-researc…
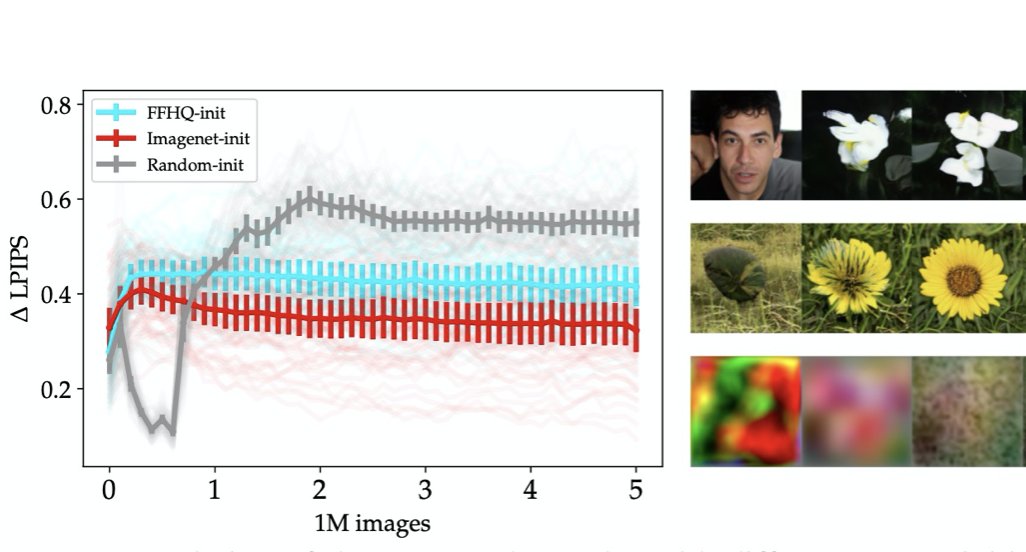
English
@tomgoldsteincs Strictly speaking, there are two citations in the paper.
English

There's been a lot of inflation since the 80s. Nesterov's 1983 paper on accelerated gradient methods is 4.5 pages long. The bibliography contains exactly 1 citation.
mathnet.ru/links/991e7105…
English
@arankomatsuzaki @CSProfKGD Well, this is exactly a random search method - you move in a random direction with a step size (and sign) determined by direction gradient. Surprising that it is competitive with stochastic gradient descent.
English

Gradients without Backpropagation
Presents a method to compute gradients based solely on the directional derivative that one can compute exactly and efficiently via the forward mode, entirely eliminating the need for backpropagation in gradient descent.
arxiv.org/abs/2202.08587

English
arxiv.org/abs/2202.07477 - joint work with @vforvalya1 We formulate a surprising hypothesis about connection between optimal transport and DDPM models!
English
Ivan Oseledets retweetledi

Application for visa-free entry to ICM is now available in personal accounts!
Participants of the ICM can now pay the registration fee and apply for visa-free entry to the Russian Federation – check out the steps:
icm2022.org/blog/applicati…
English
We present the new approximate backward functions which reduce the memory for activations. Interesting math behind!
Paper about activation functions:
arxiv.org/pdf/2202.00441…
About linear layers:
arxiv.org/abs/2201.13195
Сode:
github.com/SkoltechAI/few…
English
Ivan Oseledets retweetledi

The world is perched on the edge of an abyss.
We may soon see the worst combat in Europe since WW2 – killing thousands of people, and raising the likelihood of nuclear war.
It didn't have to be this way. A thread. 1/N

English
@RWerpachowski @jatentaki @wellingmax Very democratic - if the opinion is different, call them trolls. In the same thread there is Victor Lempitsky who works in the same university as me and has a different view, which I do not agree but so what? It is his position.
English

Nobody seems to be talking in my bubble about that war that’s coming within a week or so in Ukraine. Is it just me that’s worried?
English
@jatentaki @wellingmax Every day in Donbass there are military clashes and people die. OSCE mission reports: osce.org/special-monito… This can blow up at any time.
English

@oseledetsivan @wellingmax What "the" provocation in Donbass? I can't think of any singular provocation more famous than the Russian anti aircraft battery shooting down a civilian airplane there...
English