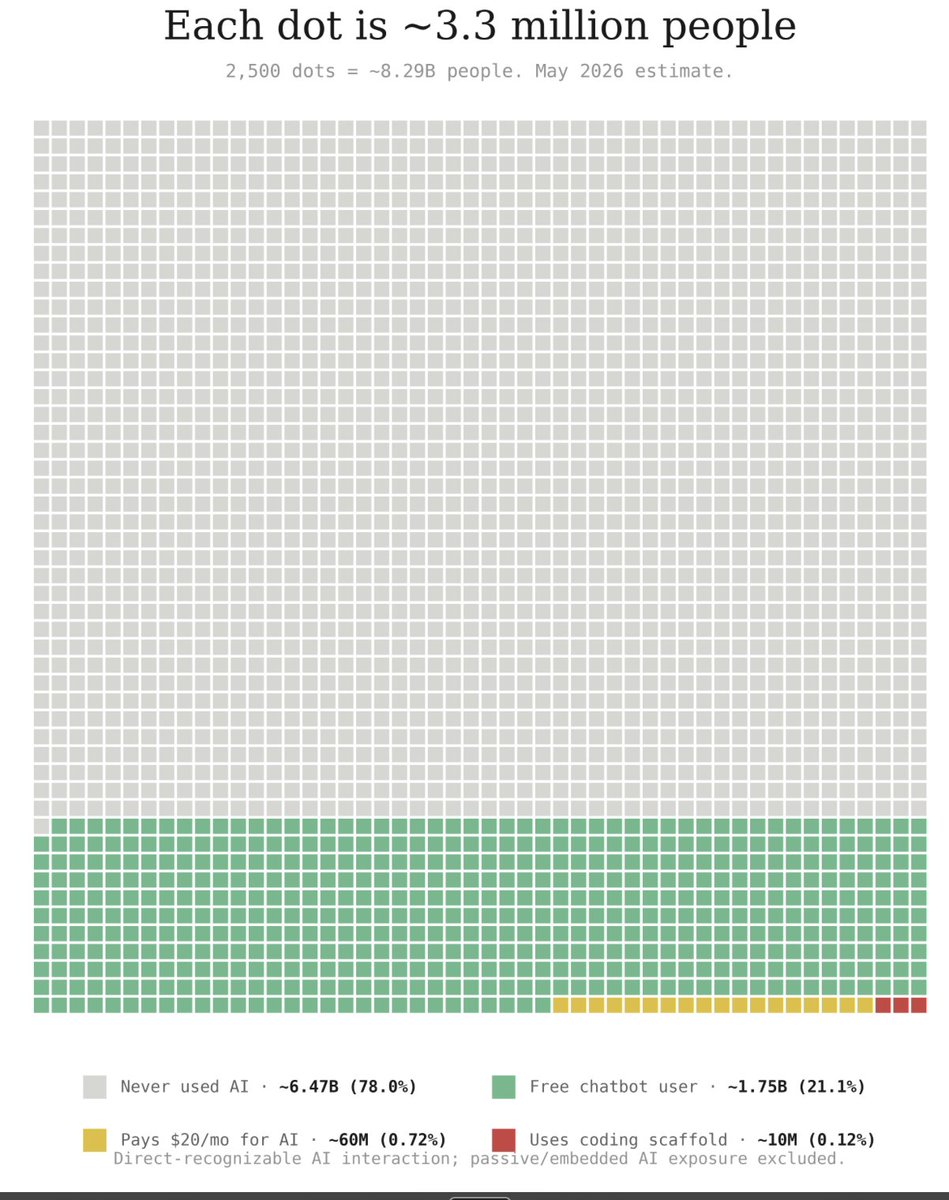
Sabitlenmiş Tweet

Personal update: I am starting my PhD @mbzuai where I look forward to work in multimodal realm (interpretability, modality imbalance, eval & application) to address foundational gaps with @AlhamFikri and co.



English
pat ✈️ CVPR
418 posts

@patrickamadeus_
multimodal, grounding, and embodied ai | PhD @mbzuai





CV has CNNs, NLP has transformers - what inductive bias does RL have? How can policies generalise to regions of the dataset suffering from poor transitions? We motivate hierarchy by enabling distinct state-representations at different levels of the hierarchy @FLAIR_Ox @j_foerst









1/ 🚀 We’re excited to share Tuna-2: Pixel Embeddings Beat Vision Encoders for Multimodal Understanding and Generation! Tuna-2 is a native unified multimodal model that supports visual understanding, text-to-image generation, and image editing directly from pixel embeddings. 🐟✨ 📄 Paper: arxiv.org/abs/2604.24763 🌐 Project: tuna-ai.org/tuna-2 💻 Code: github.com/facebookresear… Most unified multimodal models still rely on pretrained vision encoders, which add architectural complexity and can create representation mismatches between understanding and generation. Tuna-2 asks a simple question: Do we still need vision encoders? 👀 Our answer is No! Tuna-2 has a completely encoder-free architecture, where images are processed directly by a unified transformer together with text tokens. Take a glimpse at what our model can generate ↓ 🎨🖼️
Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.