
@HannaHajishirzi Working with you at Ai2 was a wonderful learning experience. Thank you for your leadership on so many impactful projects!
English
Pradeep Dasigi
479 posts
@pdasigi
Research Scientist @allen_ai; #NLProc, Post-training for OLMo



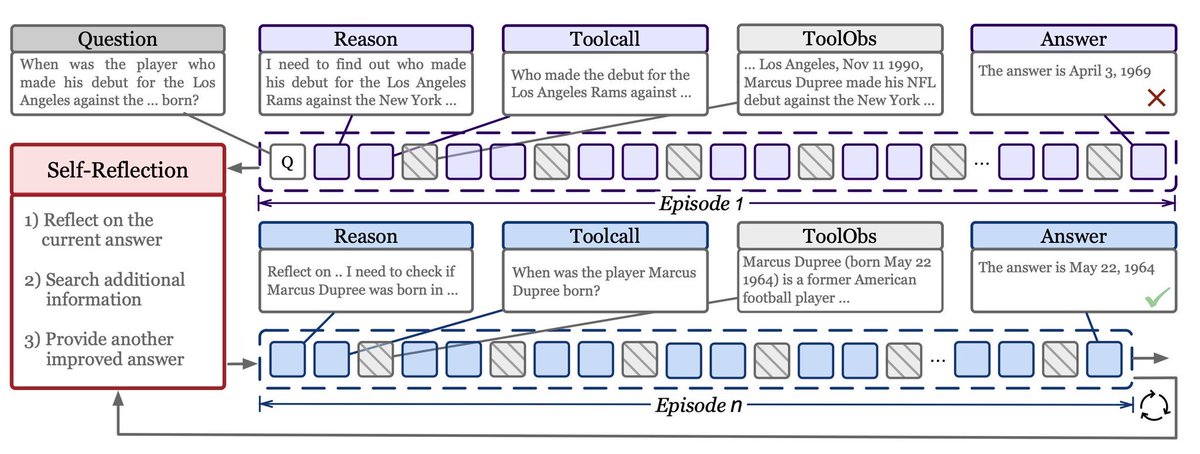
🚀 New work: Meta-Reinforcement Learning with Self-Reflection LLM agents shouldn't just solve problems. They should learn from their own attempts. Most current RL methods optimize single independent trajectories. Each attempt starts from scratch, with no mechanism to improve across attempts. But intelligent systems should get better after trying once. This raises a fundamental question: How do we train models to learn from their own attempts? We believe Meta-Reinforcement Learning may be a key paradigm for training future LLM agents, enabling models to adapt and improve across attempts and environments. In this work we introduce MR-Search, a training paradigm built around: 🧠 In-Context Meta-Reinforcement Learning 🪞 Self-Reflection 🔁 Learning to learn at test time 📄 Paper: arxiv.org/abs/2603.11327 💻 Code: github.com/tengxiao1/MR-S…
🚀 New work: Meta-Reinforcement Learning with Self-Reflection LLM agents shouldn't just solve problems. They should learn from their own attempts. Most current RL methods optimize single independent trajectories. Each attempt starts from scratch, with no mechanism to improve across attempts. But intelligent systems should get better after trying once. This raises a fundamental question: How do we train models to learn from their own attempts? We believe Meta-Reinforcement Learning may be a key paradigm for training future LLM agents, enabling models to adapt and improve across attempts and environments. In this work we introduce MR-Search, a training paradigm built around: 🧠 In-Context Meta-Reinforcement Learning 🪞 Self-Reflection 🔁 Learning to learn at test time 📄 Paper: arxiv.org/abs/2603.11327 💻 Code: github.com/tengxiao1/MR-S…



Congrats to the 126 early-career scholars awarded a 2026 Sloan Research Fellowship, whose creativity and innovation set them apart as the next generation of scientific leaders! Our Fellows represent 7 fields and 44 institutions across the US and Canada. sloan.org/fellowships/20…
Super excited to share our open interactive demo for DR Tulu-8B! It supports web and literature search with full transparency — you can see the model's thinking traces and tool outputs as it reasons through your query. 🔗 dr-tulu.org 📝 arxiv.org/abs/2511.19399





Today we introduce humans&, a human-centric frontier AI lab. We believe AI can be reimagined, centering around people and their relationships with each other. At its best, AI should serve as a deeper connective tissue that strengthens organizations and communities
For AI to be truly inclusive, it must understand more than just grammar—it must understand context. @AI4Bharat at @iitmadras had launched the Indic LLM Arena. This isn't just another leaderboard; it’s a public utility for: ✅ Developers: Test your models against real-world Indian use cases. ✅ Enterprises: Find out which LLM actually resonates with your customers in rural India. ✅ Sovereignty: Building AI that respects our social fabric and safety norms. Be a part of this movement. Try the Arena today and help us rank the models that will power India's digital future. 👉 ai4bharat.iitm.ac.in/blog/indic-llm… #GenerativeAI #DigitalIndia #IITMadras #IndicLLM #indiaaiimpactsummit2026 @MiteshKhapra @anoopk @prajdabre @ravi_iitm @partha_p_t @ManishGuptaMG1 @meghtweets @dineshteewari1 @abapna @WSAI_IITM @OfficialINDIAai @EkStep_Org @PeoplePlusAI


For AI to be truly inclusive, it must understand more than just grammar—it must understand context. @AI4Bharat at @iitmadras had launched the Indic LLM Arena. This isn't just another leaderboard; it’s a public utility for: ✅ Developers: Test your models against real-world Indian use cases. ✅ Enterprises: Find out which LLM actually resonates with your customers in rural India. ✅ Sovereignty: Building AI that respects our social fabric and safety norms. Be a part of this movement. Try the Arena today and help us rank the models that will power India's digital future. 👉 ai4bharat.iitm.ac.in/blog/indic-llm… #GenerativeAI #DigitalIndia #IITMadras #IndicLLM #indiaaiimpactsummit2026 @MiteshKhapra @anoopk @prajdabre @ravi_iitm @partha_p_t @ManishGuptaMG1 @meghtweets @dineshteewari1 @abapna @WSAI_IITM @OfficialINDIAai @EkStep_Org @PeoplePlusAI





Olmo 3.1 is here. We extended our strongest RL run and scaled our instruct recipe to 32B—releasing Olmo 3.1 Think 32B & Olmo 3.1 Instruct 32B, our most capable models yet. 🧵

Olmo 3.1 is here. We extended our strongest RL run and scaled our instruct recipe to 32B—releasing Olmo 3.1 Think 32B & Olmo 3.1 Instruct 32B, our most capable models yet. 🧵


