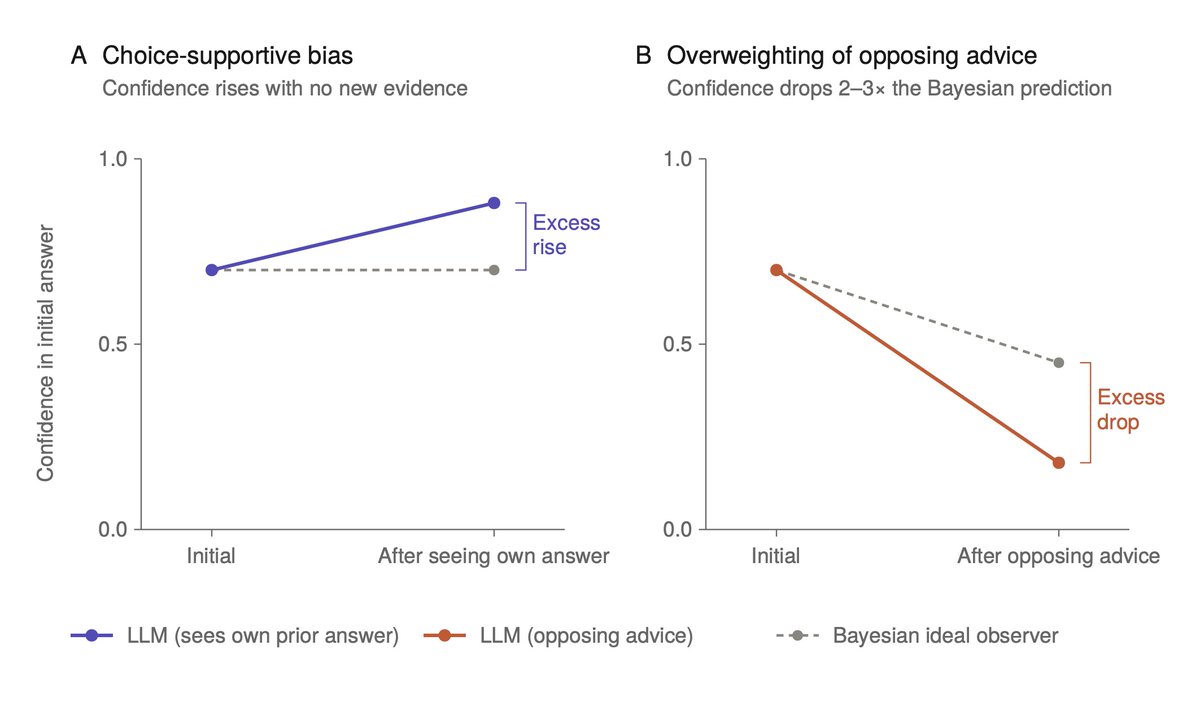
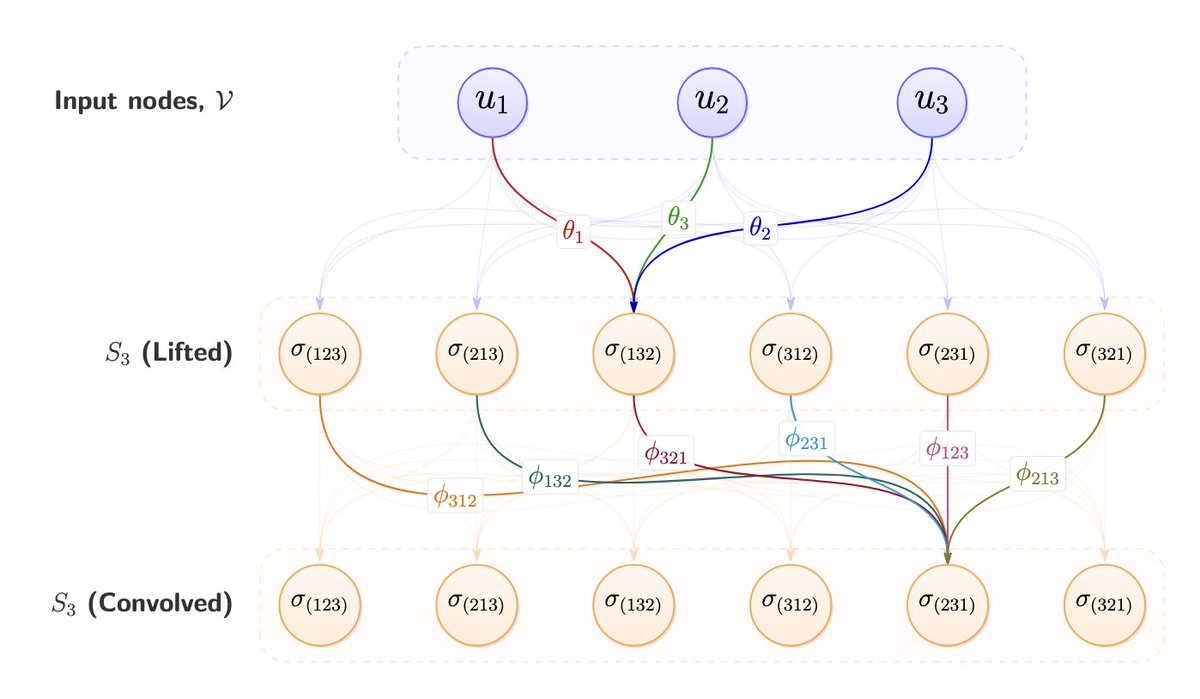
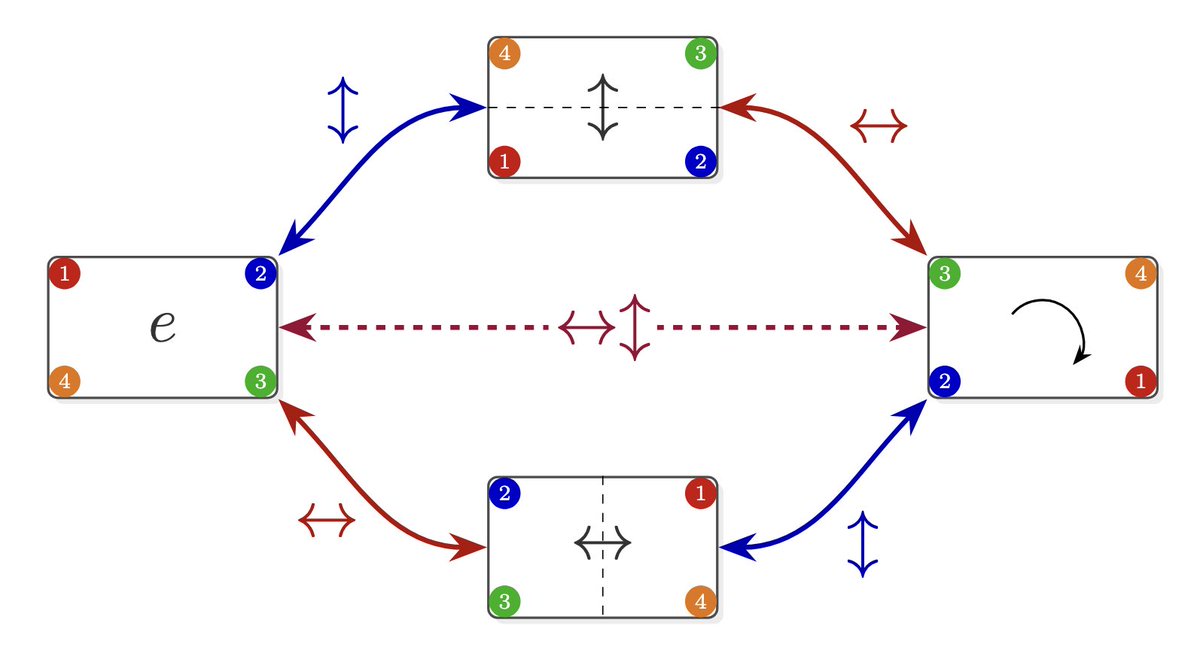
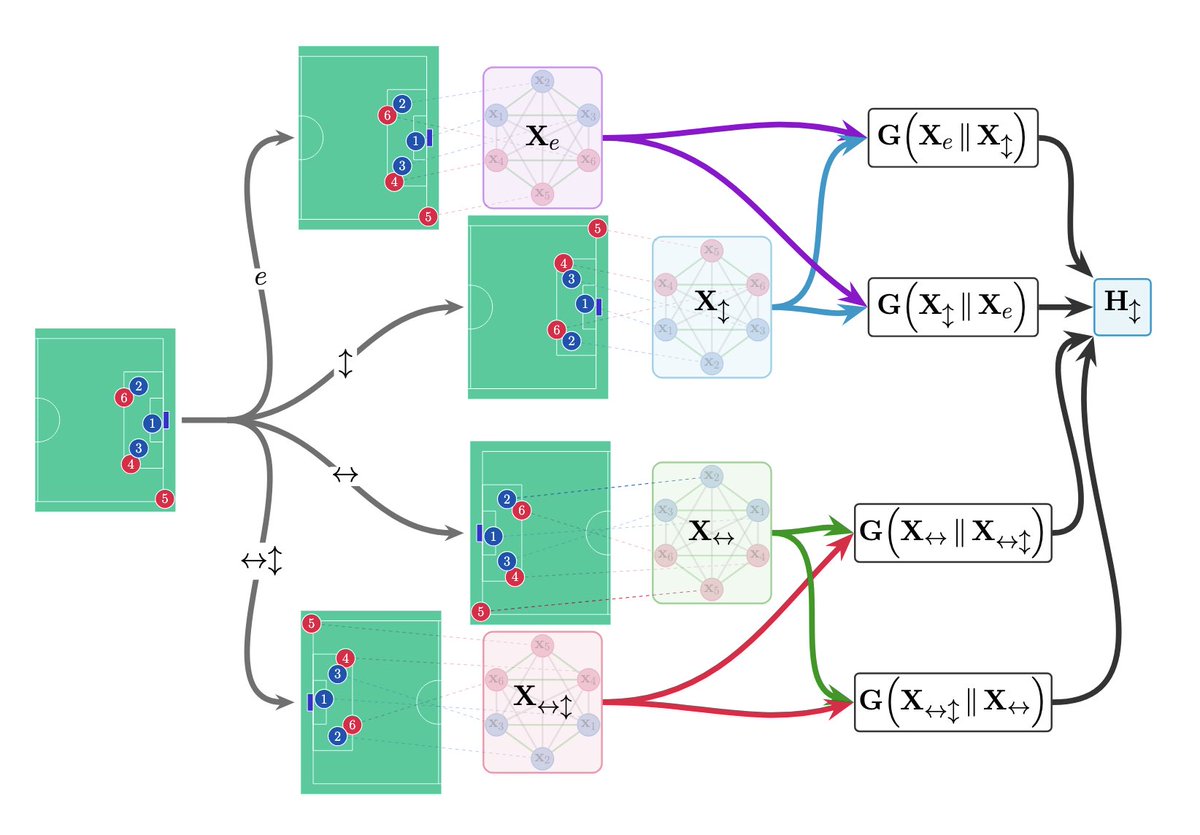
Sabitlenmiş Tweet

These days, I receive a lot of email 📬 and realise my communication could be significantly more effective.
Please see petar-v.com/contact.html for optimal ways to reach out 📨, and FAQ answers❓(including pointers to materials on GNNs / GDL, and research / internship advice!).

English