Sabitlenmiş Tweet

Note更新、「2025のまとめ雑感と2026(妄想)展望について」
ちょっと長いと雑ですか、参考になれば幸せです。 note.com/jason_chan/n/n…
日本語
JASON CHAN
49.6K posts

@phantom2008012
日本語が下手の香港人。趣味は株、ゲーム、アニメどか。










SK hynix 相親王者:老婆找到了,員工真的幹活不累了 昨天還在講 SK hynix 是不是快被三星、Micron 追上,結果今天直接丟 ICE 出來。 不是嘴砲,是物理。 ICE(Integrated Cooling Elements)就是把「散熱磚」直接塞進 HBM package 裡,在最燙的 D2D PHY 熱點旁邊,多開一條專用散熱路。thermal resistance 直接砍 30% 以上。以前熱卡在 stack 中間像便當店爐口悶燒,現在等於直接在炒鍋旁邊開排風管。 員工突然不累了。 這東西最狠的是,它不是什麼科幻黑科技,而是接在 SK hynix 已經練很久的 MR-MUF 上。 MR-MUF 白話就是: 以前 TC-NCF 像蓋樓每一層都慢慢貼膠壓合,蓋到後面樓歪掉、熱也散不掉。 MR-MUF 是整棟樓先焊好,再一次灌高導熱水泥。熱路更多、warpage 更少、良率更穩,還能塞更多 thermal dummy bumps。 現在再加 ICE,等於: 以前 HBM 是一個很會賺錢但容易爆汗的工程師,現在終於娶到老婆了。 老婆不會寫 code。 但老婆會散熱。 所以老公可以繼續加班。 這波不是什麼 AI 願景,是很純的工程勝利: 「不要再叫員工忍耐了,我直接幫他開冷氣。」




Synspectiveは、明日から開催される「SPEXA(宇宙ビジネス展)」に出展します🛰️ 会場:東京ビッグサイト 南ホール 小間番号:【S12-24】 また、明日12:00からは当社ビジネス部マネージャーの小澤がステージに登壇します! カンファレンスの聴講に事前予約は不要ですので、ぜひお気軽にお立ち寄りください。 テーマ:「宇宙から挑む国土強靭化:SAR衛星が変える『被災把握』と『インフラ保全』」 登壇者:小澤 剛(ビジネス部マネージャー) 開催日時:5月27日(水)12:00-12:30 ステージ:Mars Stage 詳細: #01" target="_blank" rel="nofollow noopener">spexa.jp/tokyo/ja-jp/co…
#SPEXA #SAR衛星 #宇宙ビジネス #イベント【📢いよいよ明日から開催】 宇宙ビジネスの“今”と“これから”が分かるSPEXA、いよいよ明日開幕! 日本の宇宙産業戦略、宇宙データセンター、衛星データ利活用に加え、 ✔ 申込不要、【宇宙ビジネスの今がわかる】40セッション以上のカンファレンス ✔ 「宇宙戦略基金事業」採択・出展企業特集、スタンプラリーも💮 ✔ 相談コーナー:CubeSatサロンin SPEXA~超小型人工衛星 相談コーナー~ ✔ 世界の宇宙機関・団体パビリオンー宇宙ビジネスの最前線を担う国際機関が終結ー など、現場に役立つ情報が一堂に集まります。 明日からの3日間、ぜひご来場ください! 🎫 来場登録はこちらから 🎫 入場無料・来場登録はこちら:spkl.io/601976yRt 📍 東京ビッグサイト 🗓️ 2026年5月27日(水)〜29日(金)|10:00〜17:00 #SPEXA #SPEXAJapan #SPEXAJP #SPEXA2026 #スペクサ #SPEXAJapan2026 #SPEXAJP2026 #宇宙ビジネス #宇宙産業 #宇宙開発 #宇宙探査 #東京ビッグサイト #RXGlobal

The Taiwan Stock Exchange (TWSE) will host a high-profile media briefing on June 4 during COMPUTEX, inviting 7 leading listed companies to share exclusive insights on two massive themes: Semiconductors and AI Infrastructure. Featured companies: • Alchip (3661) • Msscorps / 汎銓 (6830) • Nanya Technology (2408) • Unimicron (3037) • AVC 奇鋐 (3017) • Delta Electronics (2308) • Wistron (3231) #COMPUTEX2026 #AI
例の銘柄、技術路線で少し持ってたけど、もう需給が主役だなこれ。ショート踏み上げの祭り状態。ここから追い打ちでファンドの買いが入るとか…ショート勢、マジでご愁傷様

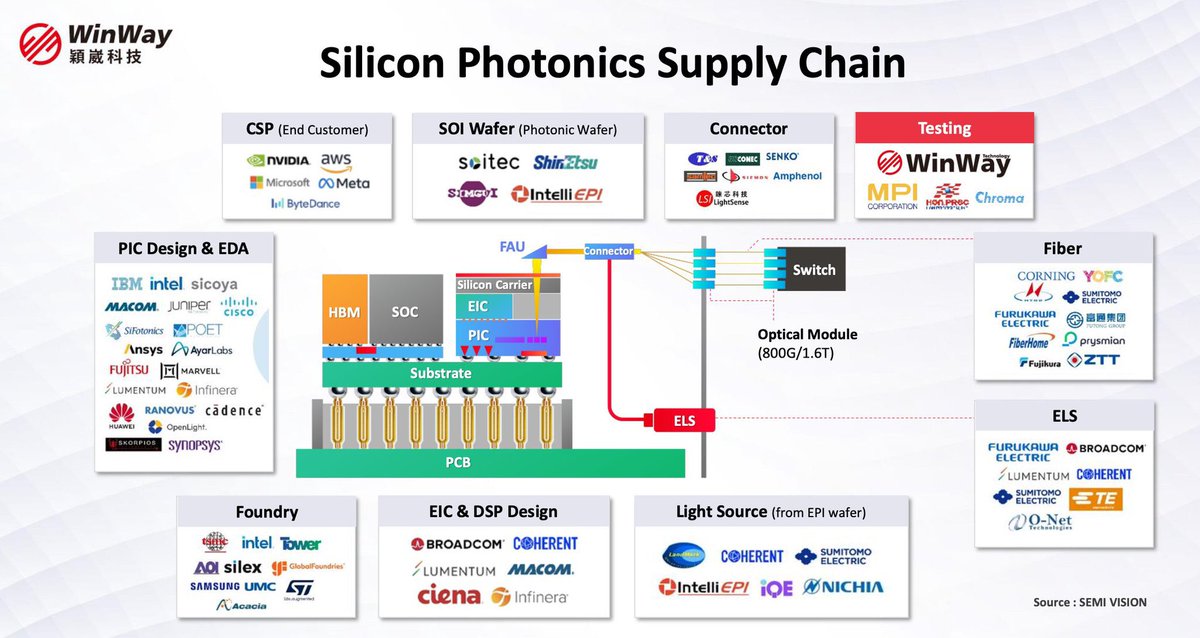
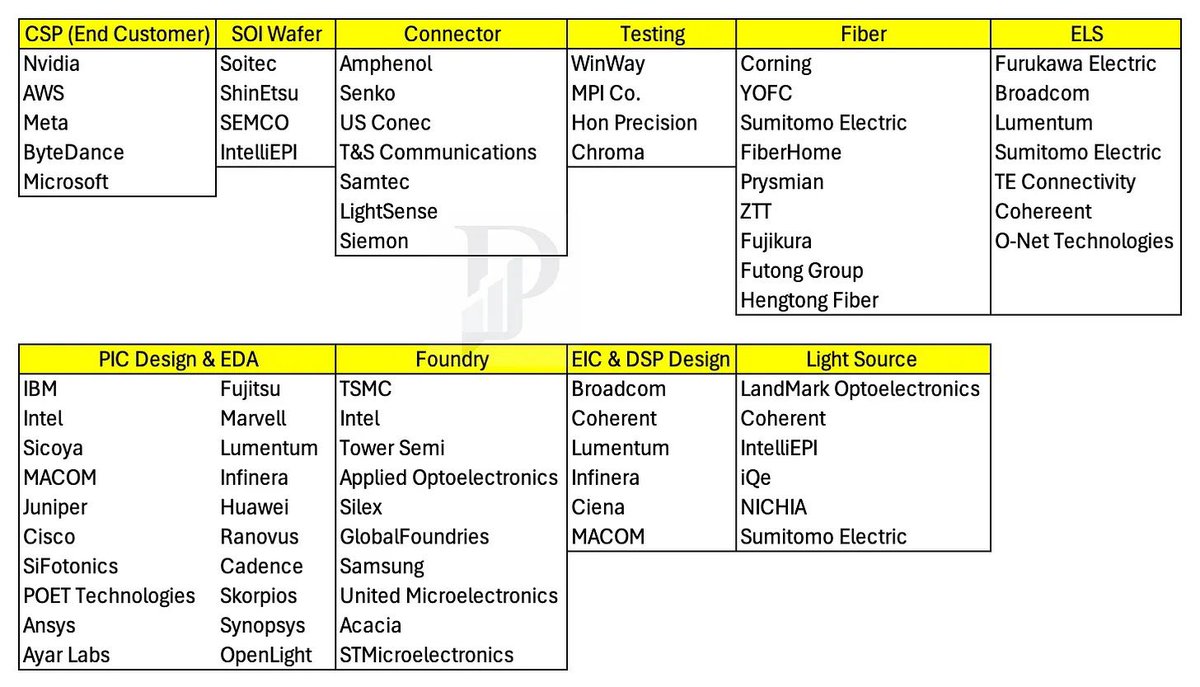

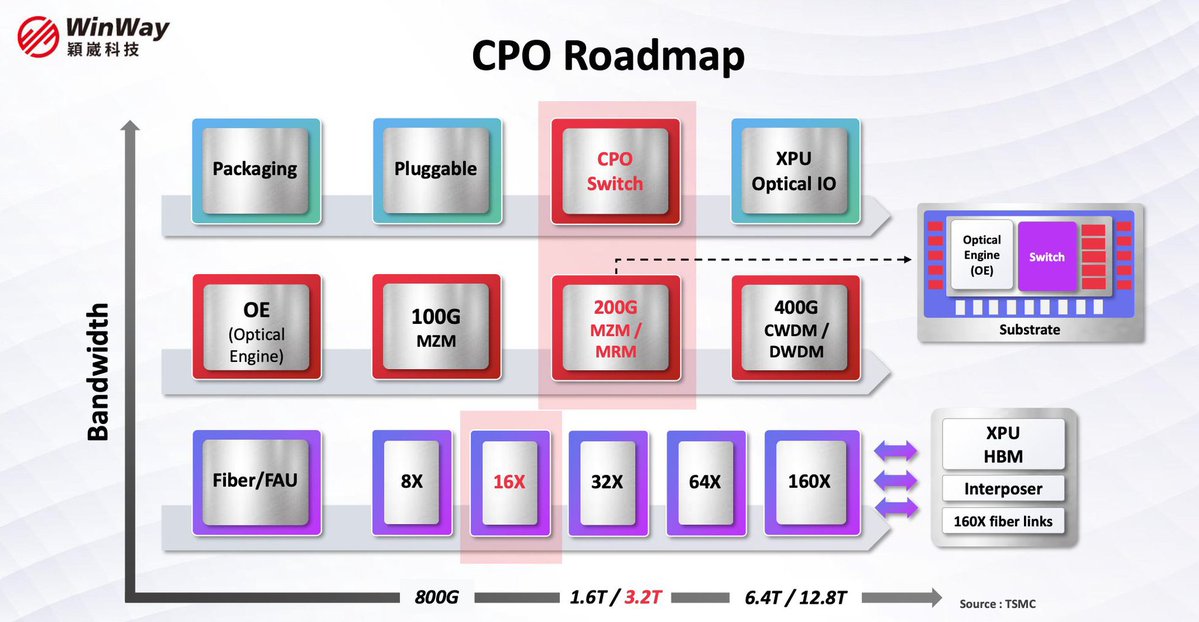
This is an amazing video recommendation from Jukan about CPO. _______________________________________________________ NPO is still 50% copper, 50% optics. The real CPO ramp is unlikely to begin until 2027 when 2.5D CPO will have 20% copper and 80% optics. In 2030, the split will be 100% optics in 3D CPO (COUPE XPU) The true hurdle is in maintenance for CPO in 2027 and 2030. Pluggable/OBO/NPO (Green/Yellow): If an optical laser or engine fails, field technicians can easily hot-swap a pluggable module at the faceplate, or replace an NPO module on the board without tossing the expensive ASIC. 2.5D & 3D CPO (Red): Once the PIC and laser/optical components are physically bound inside the package or stacked directly under the ASIC, they can no longer be individually serviced. If a single optical component fails, the entire high-value compute engine (the XPU/Switch) is essentially bricked. _______________________________________________________ CPO supply chain, per @semivision_tw: 1. CSP Nvidia $NVDA AWS $AMZN Meta $META ByteDance Microsoft $MSFT 2. SOI Wafer Soitec ShinEtsu SEMCO IntelliEPI 3. Connector Amphenol Senko US Conec T&S Communications Samtec LightSense Siemon 4. Testing WinWay MPI Co. Hon Precision Chroma 5. Fiber Corning $GLW YOFC Sumitomo Electric FiberHome Prysmian ZTT Fujikura Futong Group Hengtong Fiber 6. ELS Furukawa Electric Broadcom Lumentum Sumitomo Electric TE Connectivity Coherent O-Net Technologies 7. PIC Design & EDA IBM $IBM Intel $INTC Sicoya MACOM $MTSI Juniper Cisco $CSCO SiFotonics POET Technologies $POET Ansys - part of Synopsys Ayar Labs Fujitsu Marvell $MRVL Lumentum $LITE Infinera Huawei Ranovus Cadence $CDNS Skorpios Synopsys $SNPS OpenLight 8. Foundry TSMC $TSM Intel $INTC Tower Semi $TSEM Applied Optoelectronics $AOI Silex GlobalFoundries $GFS Samsung United Microelectronics $UMC Acacia STMicroelectronics $STM 9. EIC & DSP Design Broadcom $AVGO Coherent $COHR Lumentum $LITE Infinera Ciena $CIEN MACOM $MTSI 10. Light Source LandMark Optoelectronics Coherent $COHR IntelliEPI iQe NICHIA Sumitomo Electric