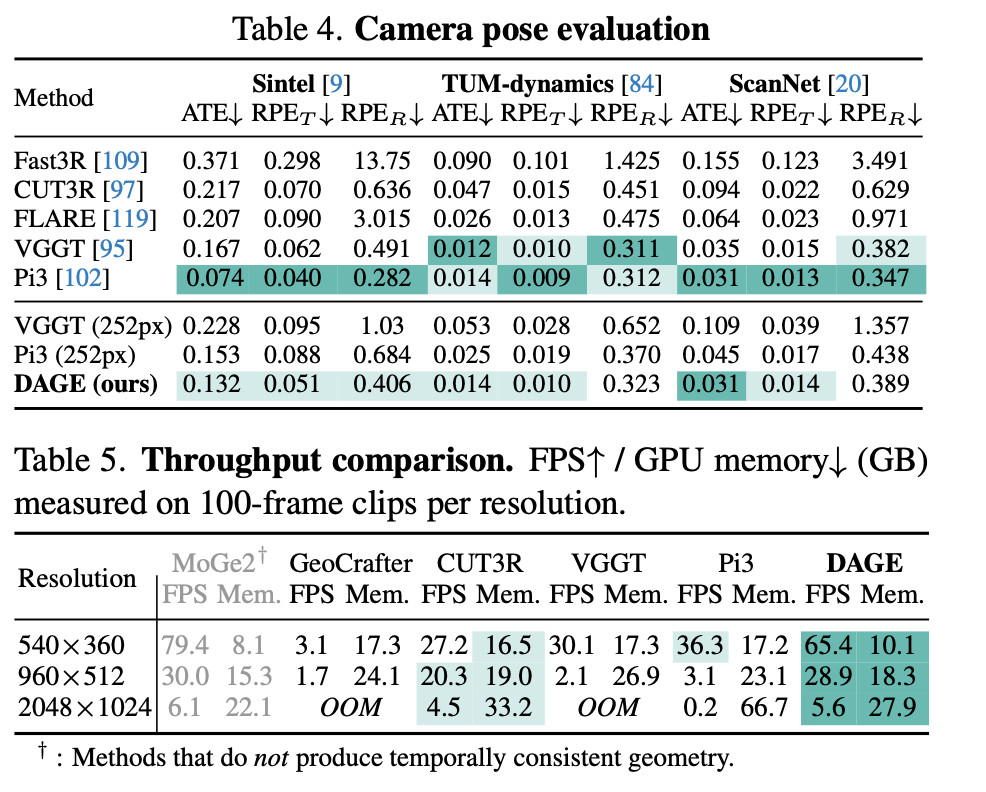
Phuc Nguyen Duc Anh retweetledi

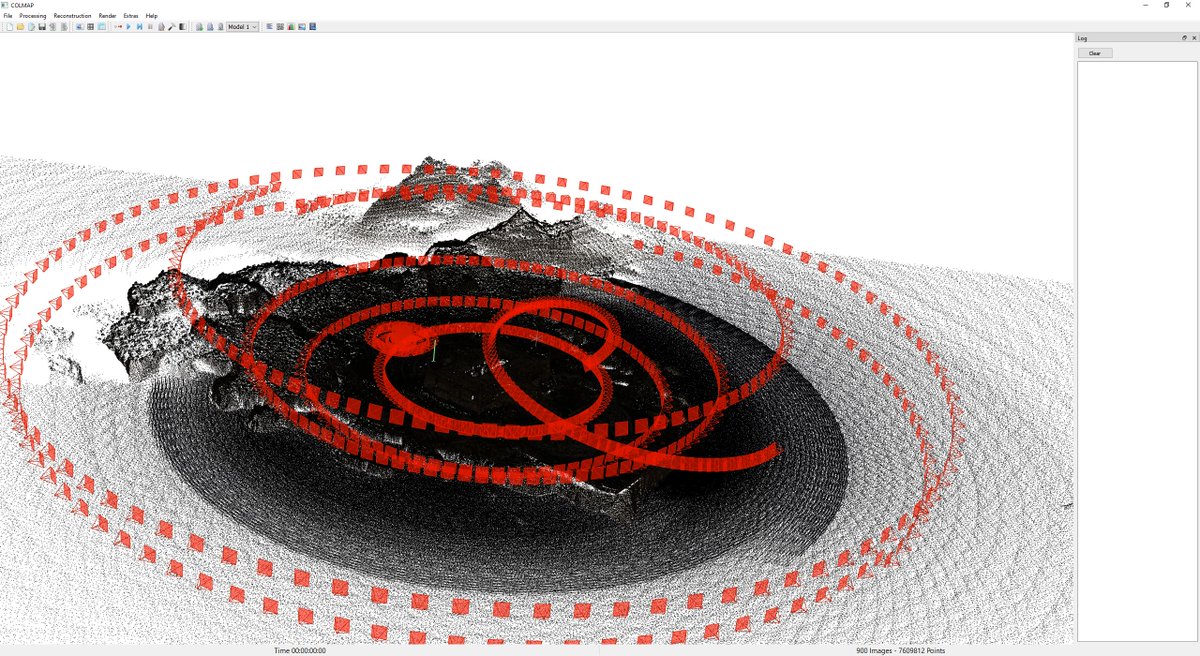
VGGT-SLAM++
Avilasha Mandal, Rajesh Kumar, @sudarshan_s_h, Chetan Arora
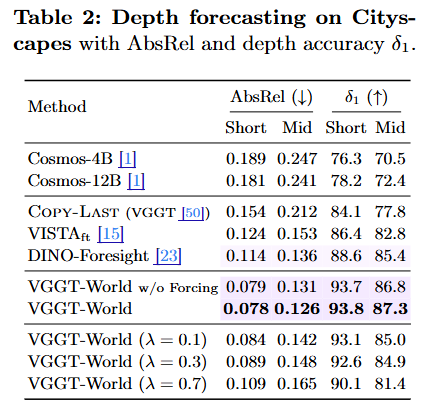
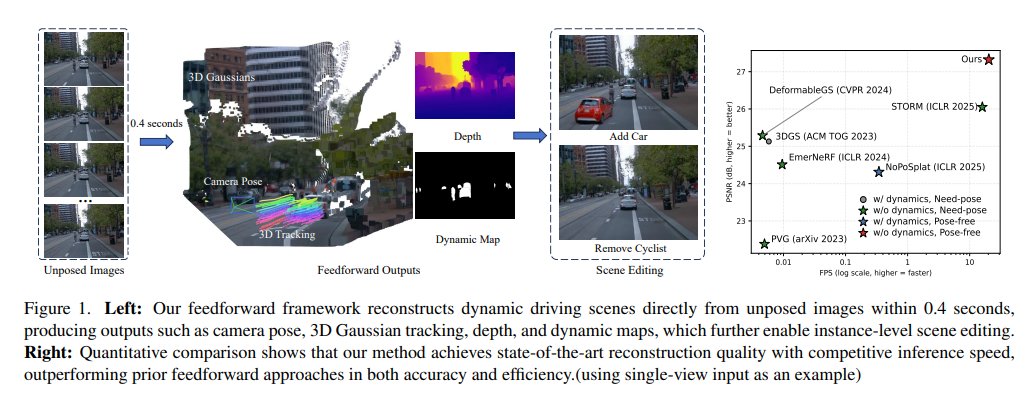
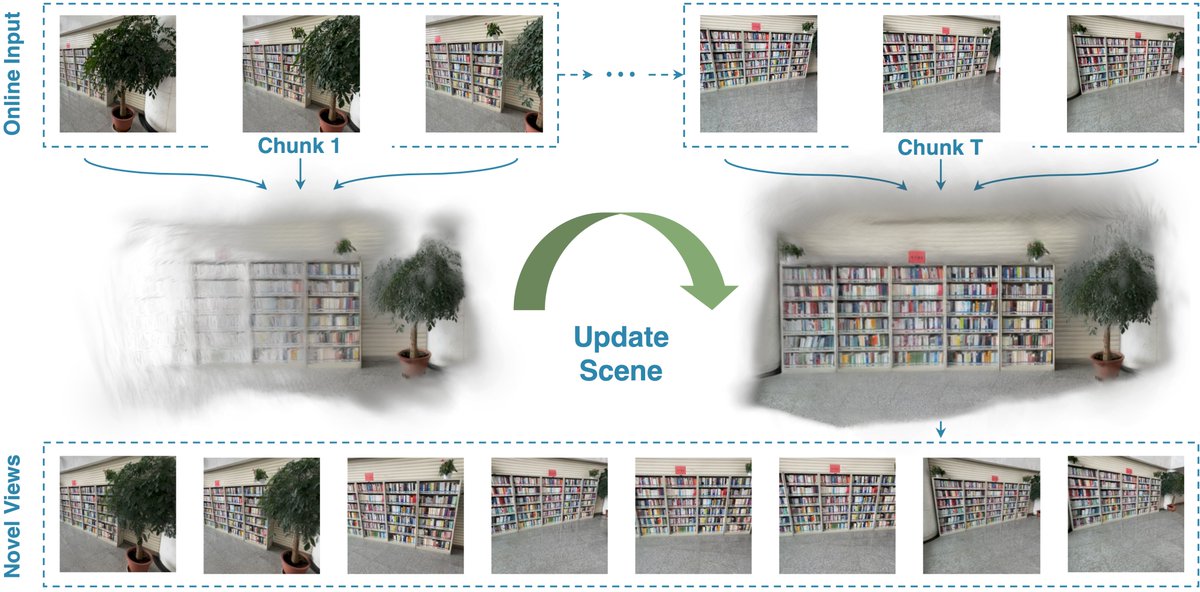
tl;dr: DEM->submap; DINOv2 embeddings->retrieval; covisibility graph synthesis
arxiv.org/abs/2604.06830




Phuc Nguyen Duc Anh
112 posts

@phucnda
Ph.D. @UMDCS | Ex-resident at @VinAI_Research