Weekends are made for coding. Form pc, phone, in the bathroom, 💻
500,000 lines of code in just 2 days! And we’re still counting! 🚀🔥 #buildinpublic #devcommunity #coding #developer #AI #Vibecoding
English
Phyrexia AKA GG
21.3K posts

@phyrexia
Geek, Gamer, Maker, Friend, Dad. Former Rioter IBMer ~ Trabajando para ser feliz día a día, N∂maste ~ Mis opiniones son mias y de nadie más.


The latest CodexBar update renders API costs wayyyy nicer. codex.bar


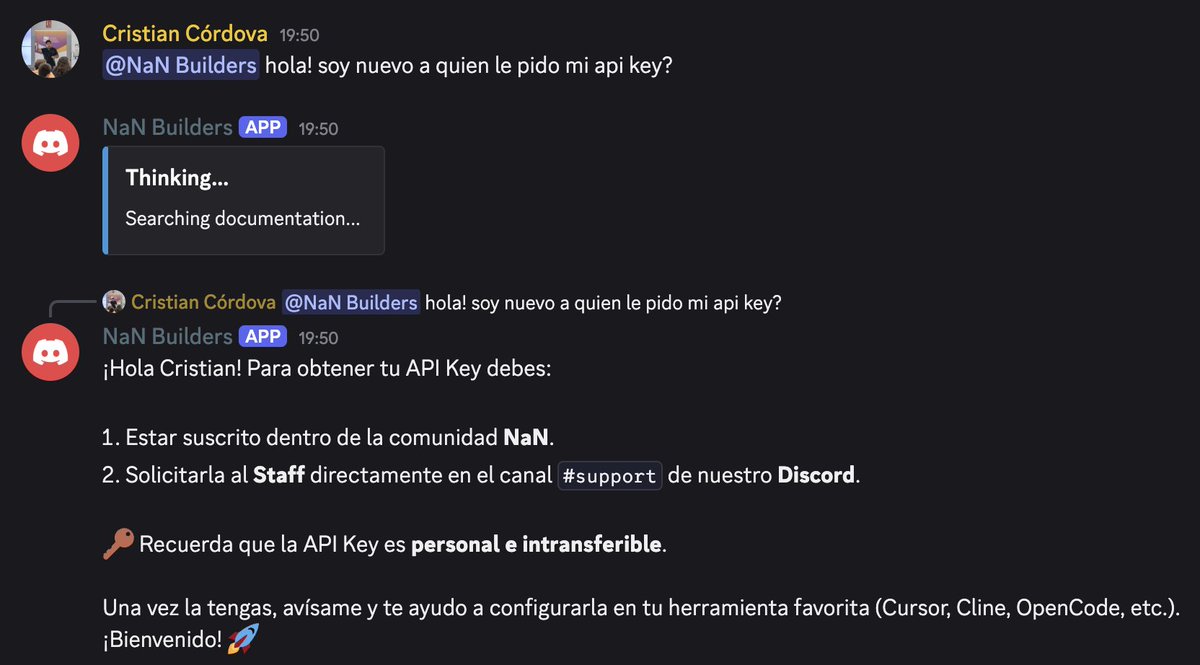
Pues oficialmente echó a andar el primer server de la comunidad de NaN. ~30 personas construyendo con modelos OS de diferentes características y finalidades. Ahora si a quemas tokens y poner esas GPUs al rojo vivo 🔥 Podeis uniros aún a la waitlist: nan.builders


Ya me lo han habilitado! 🔥 Vamos a quemar esta RTX 6000 con 96GB de vRAM como si no hubiera un mañana. Tengo ahora que hacer aún todo el setup (instalarle el SO, el stack para servir modelos, etc) pero bueno, queda nada. Seguramente haga un post de todo el setup que haga aquí
1. Opus 4.7 es otro modelo. No es 4.6 2. Opus 4.6 no ha sido nerfeado en forma alguna. Funciona igual de bien que al principio (si sabes usarlo, claro). 3. El nuevo tokenizador de Opus 4.7 es parte de la capacidad de mejora del modelo. 4. Si no te gusta, ahí tienes GLM u otros. Esto no está copiado y pegado de otros: esto es trabajo real, lectura de papers, estudio y compresión.
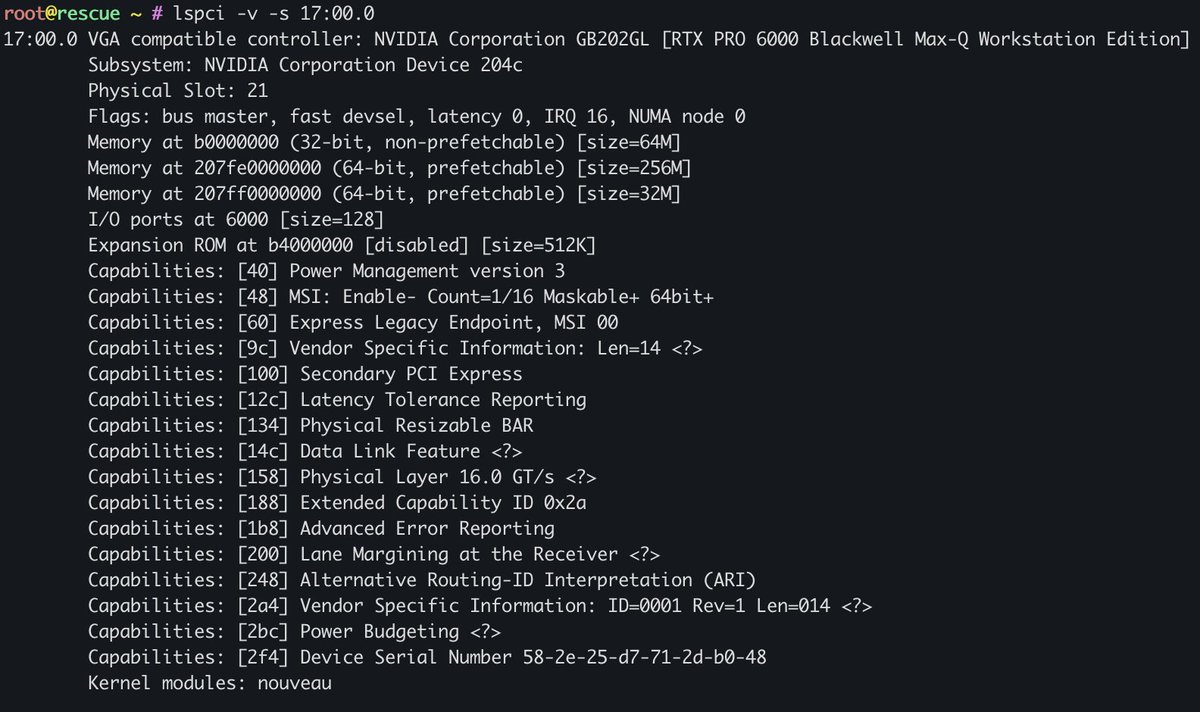
Ya he solicitado el primer server para la comunidad de NaN. Lo montaré en EU con todos los juguetes para poder empezar a quemar tokens como locos sin limites. Nos quedan pocas plazas para empezar a levantar el server de LATAM/USA también. ¡Apúntate! nan.builders


le nouveau bébé

Introducing 𝐆𝐞𝐦𝐦𝐚 𝟒 𝟑𝟏𝐁 𝐓𝐮𝐫𝐛𝐨 ⚡️ It runs on a 𝘴𝘪𝘯𝘨𝘭𝘦 RTX 5090, at 51 tok/s (single) and 1244 tok/s (batched). And prefills up to 15359 tok/s. It's 𝟔𝟖% 𝐬𝐦𝐚𝐥𝐥𝐞𝐫 in GPU memory and ~𝟐.𝟓𝐱 𝐟𝐚𝐬𝐭𝐞𝐫 than the base model, and retains nearly 𝐢𝐝𝐞𝐧𝐭𝐢𝐜𝐚𝐥 𝐪𝐮𝐚𝐥𝐢𝐭𝐲 on benchmarks (1-3% loss). Turbo is a derivative of the NVFP4 quant that NVIDIA released a few days ago. It fully leverages NVIDIA Blackwell FP4 tensor cores for ~𝟐× 𝐡𝐢𝐠𝐡𝐞𝐫 𝐜𝐨𝐧𝐜𝐮𝐫𝐫𝐞𝐧𝐭 𝐭𝐡𝐫𝐨𝐮𝐠𝐡𝐩𝐮𝐭 𝐭𝐡𝐚𝐧 𝐨𝐭𝐡𝐞𝐫 𝐪𝐮𝐚𝐧𝐭𝐬. I'm using it for hard classification tasks — on internal benchmarks it showed 𝐒𝐨𝐧𝐧𝐞𝐭-𝟒.𝟓-𝐥𝐞𝐯𝐞𝐥 𝐢𝐧𝐭𝐞𝐥𝐥𝐢𝐠𝐞𝐧𝐜𝐞 (scored well above Haiku 4.5), at a 600𝘵𝘩 of the cost. A single RTX 5090 scales up to 18 req/s at 1000in/20out 🥵. Model card and benchmark in comments 👇 I'd love to hear your use cases.