
Sesem_ Ag
249 posts

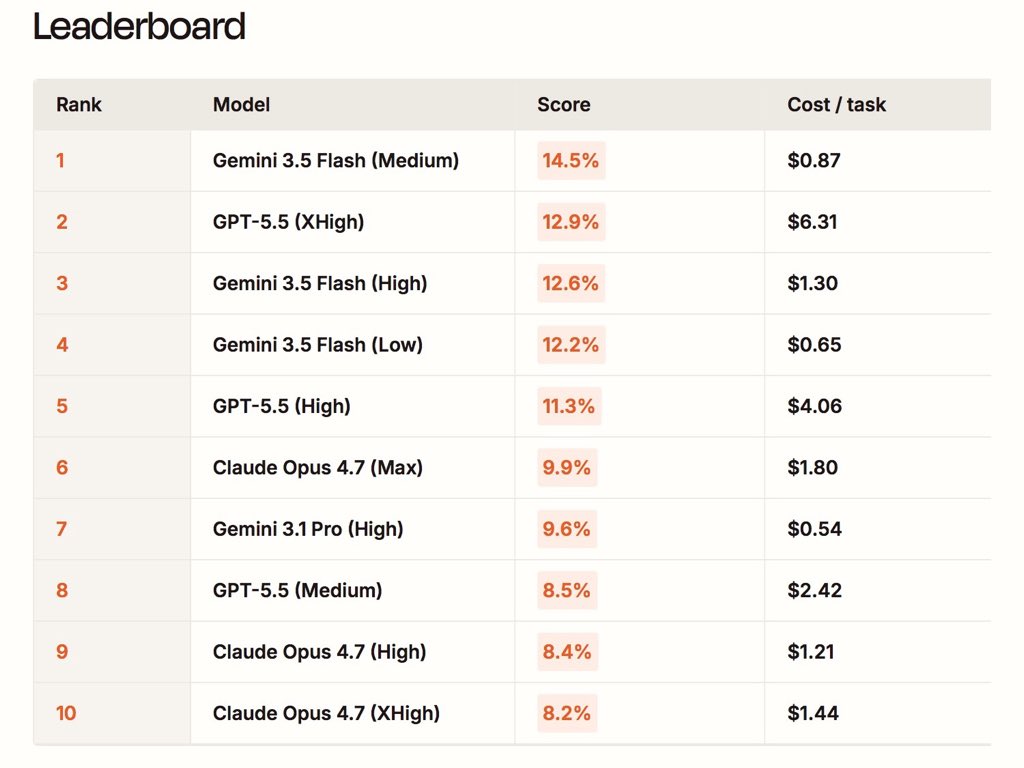
Gemini 3.5 Flash ranks #1 on Automation Bench (from Zapier), beating every other frontier model at a much lower cost
English

We're testing Terminal War internally.
We believe early feedback is valuable but there is much to improve already.
Would you be interested in a playtest this simple?
English

I’ve been invited by Google to attend its annual I/O conference as part of the Builders Program, and I’m incredibly excited.
It’s my first time at Google, and this time I brought a camera with me to capture the experience and create a recap video afterward.
During the event, I’ll be conducting two fascinating interviews with Google employees, focusing on AI. These will be published at a later date.
I’ve already met some amazing people from the community.
Here’s to two unforgettable days!

English
@synthwavedd i can feel "vibecoded" shi just by look. Whats wrong with you, leo?
English

I've been testing Gemini 3.5 Flash for a little while now, and I'm excited to be able to share one of the outputs that most impressed me!
This was 0-shot, no harness, with a single sentence prompt. It outperformed all Claude models, Gemini models (by far), and arguably GPT-5.5 🔥
The issue of laziness that has plagued Gemini models forever has mostly been consigned to history.
English
@acasualnpc @OfficialLoganK You judging model's quality by a single very short video... bro, the model is not even out yet
English

@OfficialLoganK Holy shit, SOTA Gemini video model. Seedance is thing of the past. This changes everything 💀
English


YES WE WILL GET 3.5
(cuz gem is half of gemini)
Anshul Ramachandran@_anshulr
Gemini Gemini Gemini Gem
English
@Fabiobuilds @synthwavedd @arena man be real, nobody using flash models or even gemma if they have access to at least 3.1 pro. Not even talking about other models like claude or gpt
English

@synthwavedd @arena Google is already doing excellent work with small and local models, I think they are not prioritizing right now pro models.
Theu seem to have left the game all to OpenAI and Anthropic for that (which are doing quite bad in small / local models)
English
so apparently gemini 3.2 pro is being tested under "gemini-3.1-pro" on @arena's Code Arena (they have done this kind of stealth testing before)
...and if this is really 3.2 pro, it's not looking good. somehow they gpt-ified frontend? hopefully this is an arena-specific quirk
English
@Tate_Dollar @Hesamation it's unusable for now, it's just architecture, not a ready project
English

@Hesamation Why wait for them to release when somebody already coded it themselves? github.com/Jaravus/opensu…
English

> 12M context window (read it again)
> 52x faster than FlashAttention
> beats Opus 4.6 on SWE-Bench
> 5% the cost of Opus
BUT WAIT A MINUTE:
> technical blog not technical
> access coming soon
> paper coming soon
> ““Built by researchers from Meta, Google, Oxford, Cambridge, BYU” doesn’t name a single one of them
if this is not a scam, or the numbers aren’t dishonest, it’s disgustingly promotional.

Alexander Whedon@alex_whedon
Introducing SubQ - a major breakthrough in LLM intelligence. It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA), And the first frontier model with a 12 million token context window which is: - 52x faster than FlashAttention at 1MM tokens - Less than 5% the cost of Opus Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention). Only a small fraction actually matter. @subquadratic finds and focuses only on the ones that do. That's nearly 1,000x less compute and a new way for LLMs to scale.
English
@PolymerCan @walkingtoncity @tarkovarena why? Do you have any arguments or you just don't have your own opinion?
English


Gladiators, we invite you to test your knowledge of weapon mods in #TarkovArena.
Can you identify all the attachments? Share your answers in the comments!


English
@chetaslua @tehnlulz acting like it's something amazing and innovative
English

🚨 GPT 5.5 FIRST OUTPUT FROM CODEX
I am super hyped for this launch , btw have you guys heard news about Mythos controversy ( that some forums members had access to it )
credit - @tehnlulz


Chetaslua@chetaslua
🚨 GPT 5.5 spotted in codex cli and app thursday launch > btw gpt 5.5 will be 3-4 times the usual gpt 5.4 > image v2 will help in better webdev
English


@kimmonismus eh, still no real benefits except for benchshits. Yet another flash level model that loops as fuck
English
A 12-month time difference between Gemma 3 27b and Gemma 4 31b.
The jump is absolutely enormous. Just look at the evaluations between the two models.
GPQA doubled, AIME 2026 went from ~20% to ~90%, and so on. Crazy.

ollama@ollama
Learn more: ollama.com/library/gemma4
English


I still don’t get this casting lmao
Wild Videos@FightStorage
Show me a worse casting. I’ll wait…
English
English

@EmpireFaIls @MaD_MrL It’s funny that you’re responding as if I actually care about your opinion lmao.
English

🚨We all thought Apple was leaving behind in the AI race, turned out they had already crossed the finish line, waiting for the world to catch up.
entire world is running behind the concept of
bigger model -> better
but apple took edge compute seriously and started working on it much earlier, even before openclaw became a thing.
We all know how apple is so much obsessed with privacy, it’s no wonder they didn’t want an LLM to get access to your private data.
so what’s apple’s plan?
Apple’s plan is edge ai.
it aims to provide small and efficient and cheap models directly installed on your phone which you can access privately, securely, without uploading your data on any LLM for a fraction of regular cost.
won’t small models be stupid?
quite the opposite actually.
Alibaba launched 4 small models and all of them beat opus 4.5 on many benchmarks.
the goal here is targeted use of models, not to make them general purpose. regardless, we will soon see something very cool in the space of AI that will completely redefine how we work with it.
this time, it will come from apple.
Ejaaz@cryptopunk7213
English

@Chief_Kewatan @RespectfulMemes bro made a movie once in a whole century, he deserves a rest
English

@RespectfulMemes This guy made a whole ass movie on top of the usual YouTube stuff and other business ventures. Mf deserves a rest
This post is cringe
English