Sabitlenmiş Tweet

Graduated with a PhD in Computer Science @MIT!
Grateful to my advisors and teachers who helped me learn and grow in this journey! Thanks to all my friends and family members for their support.

English
Prafull Sharma
357 posts

@prafull7
PostDoc @MIT with Josh Tenenbaum and Phillip Isola PhD @MIT with Bill Freeman and Fredo Durand Undergrad @Stanford






Introducing Digital Red Queen (DRQ): Adversarial Program Evolution in Core War with LLMs Blog: sakana.ai/drq Core War is a programming game where self-replicating assembly programs, called warriors, compete for control of a virtual machine. In this dynamic environment, where there is no distinction between code and data, warriors must crash opponents while defending themselves to survive. In this work, we explore how LLMs can drive open-ended adversarial evolution of these programs within Core War. Our approach is inspired by the Red Queen Hypothesis from evolutionary biology: the principle that species must continually adapt and evolve simply to survive against ever-changing competitors. We found that running our DRQ algorithm for longer durations produces warriors that become more generally robust. Most notably, we observed an emergent pressure towards convergent evolution. Independent runs, starting from completely different initial conditions, evolved toward similar general-purpose behaviors—mirroring how distinct species in nature often evolve similar traits to solve the same problems. Simulating these adversarial dynamics in an isolated sandbox offers a glimpse into the future, where deployed LLM systems might eventually compete against one another for computational or physical resources in the real world. This project is a collaboration between MIT and Sakana AI led by @akarshkumar0101 Full Paper (Website): pub.sakana.ai/drq/ Full Paper (arxiv): arxiv.org/abs/2601.03335 Code: github.com/SakanaAI/drq/




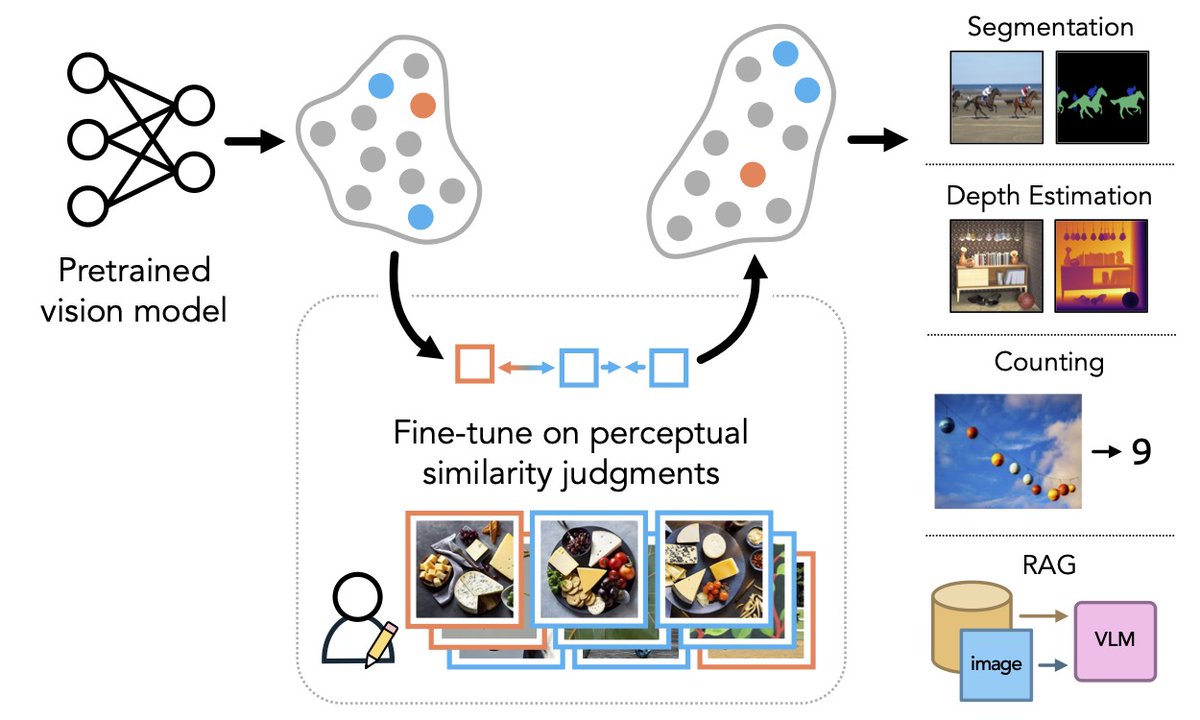
Could a major opportunity to improve representation in deep learning be hiding in plain sight? Check out our new position paper: Questioning Representational Optimism in Deep Learning: The Fractured Entangled Representation Hypothesis. The idea stems from a little-known observation about networks trained to output a single image: when they are discovered through an unconventional open-ended search process, their representations are incredibly elegant and exhibit astonishing modular decomposition. In contrast, when SGD (successfully) learns to output the same image its underlying representation is fractured, entangled - an absolute mess! This stark difference in the underlying representation of the same "good" output behavior carries deep lessons for deep learning. It shows you cannot judge a book by its cover - an LLM with all the right responses could similarly be a mess under the hood. But also, surprisingly, it shows us that it doesn't have to be this way! Without the unique examples in this paper that were discovered through open-ended search, we might assume neural representation has to be a mess. These results show that is clearly untrue. We can now imagine something better because we can actually see it is possible. We give several reasons why this matters: generalization, creativity, and learning are all potentially impacted. The paper shows examples to back up these concerns, but in brief, there is a key insight: Representation is not only important for what you're able to do now, but for where you can go from there. The ability to imagine something new (and where your next step in weight space can bring you) depends entirely upon how you represent the world. Generalization, creativity, and learning itself depend upon this critical relationship. Notice the difference in appearance between the nearby images to the skull in weight space shown in the top-left and top-right image strips of the attached graphic. The difference in semantics is stark. The insight that representation could be better opens up a lot of new paths and opportunities for investigation. It raises new urgency to understand the representation underlying foundation models and LLMs while exposing all kinds of novel avenues for potentially improving them, from making learning processes more open-ended to manipulating architectures and algorithms. Don't mistake this paper as providing comfort for AI pessimists. By exposing a novel set of stark and explicit differences between conventional learning and something different, it can act as an accelerator of progress as opposed to a tool of pessimism. At the least, the discussion it provokes should be quite illuminating.




Announcing Diffusion Forcing Transformer (DFoT), our new video diffusion algorithm that generates ultra-long videos of 800+ frames. DFoT enables History Guidance, a simple add-on to any existing video diffusion models for a quality boost. Website: boyuan.space/history-guidan… (1/7)

Introducing ASAL: Automating the Search for Artificial Life with Foundation Models sakana.ai/asal/ Artificial Life (ALife) research holds key insights that can transform and accelerate progress in AI. By speeding up ALife discovery with AI, we accelerate our understanding of emergence, evolution, and intelligence–core principles that can inspire the next generation of AI systems! We proudly collaborated with MIT, OpenAI, Swiss AI Lab IDSIA, and Ken Stanley on this exciting project. Full Paper (Website): pub.sakana.ai/asal/ Full Paper (arxiv): asal.sakana.ai/paper/ Code: github.com/SakanaAI/asal/ In this work, we propose a new algorithm called Automated Search for Artificial Life (“ASAL”) to automate the discovery of artificial life using vision-language foundation models. Instead of tediously hand-designing every tiny rule of an Alife simulation, simply describe the space of simulations to search over, and ASAL will automatically discover the most interesting and open-ended artificial lifeforms! Because of the generality of foundation models, ASAL can discover new lifeforms across a diverse range of seminal ALife simulations, including Boids, Particle Life, Game of Life, Lenia, and Neural Cellular Automata. ASAL even discovered novel cellular automata rules that are more open-ended and expressive than the original Conway’s Game of Life. We believe this new paradigm may reignite ALife research by overcoming the bottleneck of manually designed simulations, thus advancing beyond the limits of human ingenuity.

We just wrote a primer on how the physics of sound constrains auditory perception: authors.elsevier.com/a/1jzSR3QW8S6E… Covers sound propagation and object interactions, and touches on their relevance to music and film. I enjoyed working on this with @vin_agarwal and James Traer.