
Prateep Mukherjee
128 posts

a senior engineer at google just dropped a 400-page free book on docs for review: agentic design patterns.
the table of contents looks like everything you need to know about agents + code:
> advanced prompt techniques
> multi-agent patterns
> tool use and MCP
> you name it

English





🚨BREAKING: A new Python library for algorithmic trading.
Introducing TensorTrade: An open-source Python framework for trading using Reinforcement Learning (AI)

English

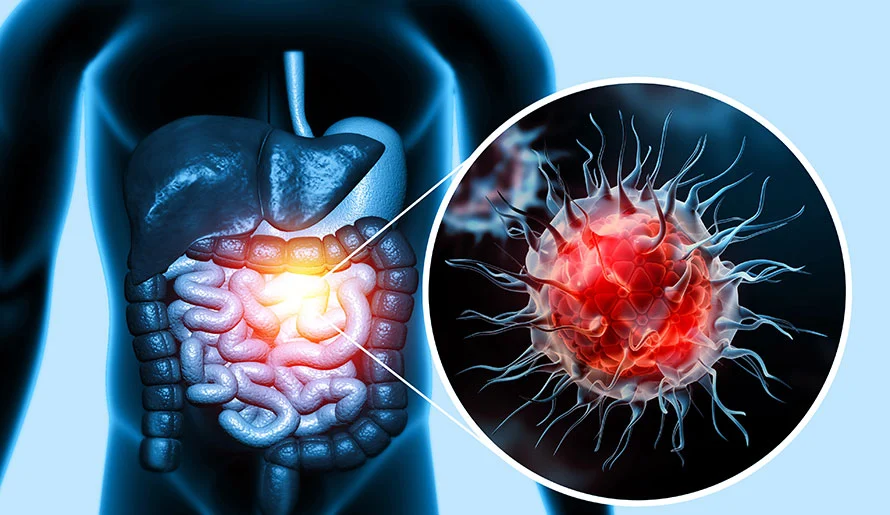
Inflammation is your No.1 enemy.
Why? It increases cancer risk, damages your brain, and leads to obesity.
Here are 9 foods that naturally reduce inflammation in your body (according to science): 🧵
English

Goodbye ChatGPT
It’s only been 5 days since Deepseek R1 dropped, and the World is already blown away by its potential.
13 examples that will blow your mind (Don't miss the 5th one):

English

This paper creates a comprehensive taxonomy of prompting techniques, organizing 58 text-based and 40 multimodal prompting methods into categories for practical use.
-----
🤔 Original Problem:
The field of prompt engineering lacks standardized terminology and structured understanding, making it difficult for practitioners to effectively use and implement various prompting techniques.
-----
🔧 Solution in this Paper:
→ The researchers conducted a systematic review using the PRISMA process to analyze thousands of papers on prompting techniques.
→ They developed a detailed vocabulary of 33 terms to standardize prompting terminology.
→ They created a taxonomy categorizing 58 LLM prompting techniques and 40 techniques for other modalities like images and audio.
→ They provided practical guidelines for prompt engineering, including specific advice for ChatGPT and other state-of-the-art LLMs.
-----
💡 Key Insights:
→ Prompting techniques can be broadly categorized into text-based, multilingual, and multimodal approaches
→ The effectiveness of prompts heavily depends on factors like exemplar quantity, ordering, and format
→ Security and alignment issues are critical concerns in prompt engineering
→ Evaluation frameworks are essential for measuring prompt effectiveness
-----
📊 Results:
→ Analyzed 4,247 research papers and extracted 1,565 relevant records
→ Achieved 92% agreement between human annotators in paper classification
→ Demonstrated 89% precision and 75% recall in automated paper classification using GPT-4

English
MapReduce meets LLMs: Divide-and-conquer approach lets regular LLMs process 100x longer documents than their context limit
Using MapReduce principles, small-context LLMs now handle million-token documents efficiently.
Original Problem 🔍:
LLMs struggle to process extremely long texts exceeding their context window, limiting their application in tasks requiring comprehensive document understanding.
-----
Solution in this Paper 🛠️:
• LLM × MapReduce: A training-free framework for long-sequence processing
• Structured information protocol: Addresses inter-chunk dependency
• In-context confidence calibration: Resolves inter-chunk conflicts
• Three-stage process: Map, collapse, and reduce stages for efficient processing
-----
Key Insights from this Paper 💡:
• Divide-and-conquer approach enables short-context LLMs to handle long texts
• Structured information and confidence calibration improve cross-chunk processing
• Framework is compatible with different LLMs, demonstrating generalization capability
• Efficient design outperforms standard decoding in speed
-----
Results 📊:
• Outperforms closed-source and open-source LLMs on InfiniteBench
• Average score: 68.66 (vs. 57.34 for GPT-4)
• Enables Llama3-70B-Instruct (8K context) to process 1280K tokens
• Faster inference: 2 GPUs for 128K tokens (vs. 4 GPUs for standard decoding)

English


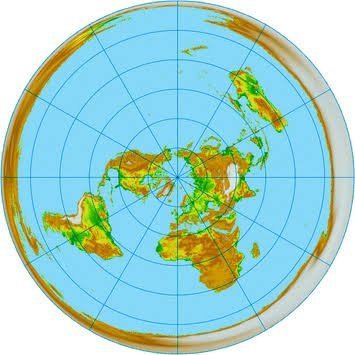

Have you ever wished to view the world from a completely new perspective? This thread on cool maps is here to blow your mind
1. Population Density in China

English

Looking at the world through a microscope 🧵
1. Terrifying photo of an ant's face

English

Your terminal just got smarter! 🧠💻
Introducing gptme: an open-source tool that let's you run AI Agent in your terminal with local tools
Here's why it's a game-changer:
🔓 Free and open-source
💻 Runs code in your local environment
📝 Reads, writes, and edits files
🌐 Browses the web from your terminal
👀 Vision capabilities—interprets images and screenshots
🔄 Self-correcting AI assistant
🤖 Supports multiple LLMs (OpenAI, Anthropic, OpenRouter, local models)
But that's not all:
🎯 Shell Copilot—find shell commands with natural language
🖥️ Development aid—write, test, and run code with AI
📊 Easy data analysis on local files
🚀 Extensible with new tools
💬 Optional Web UI and REST API
🛠️ Developer-friendly—clean codebase, easy contributions
Link to the GitHub repo in next tweet!
Find me → @akshay_pachaar ✔️
For more insights & tutorials on AI and Machine Learning.

English
Thread of cool maps you've (probably) never seen before 🧵
1. All roads lead to Rome

English

Learn programming by playing games:
1. tynker.com
Python, JavaScript, Java
2. cssbattle.dev
CSS
3. javascriptquiz.com
JavaScript
4. codingame.com
25 languages supported
5. ohmygit.org
Git
6. vim-adventures.com
Vim
7. flexboxfroggy.com
Flex
8. codecombat.com
Python, JavaScript, Java, C++
9. cssgridgarden.com
Grid
10. profy.dev/project/github…
Git Workflow
English

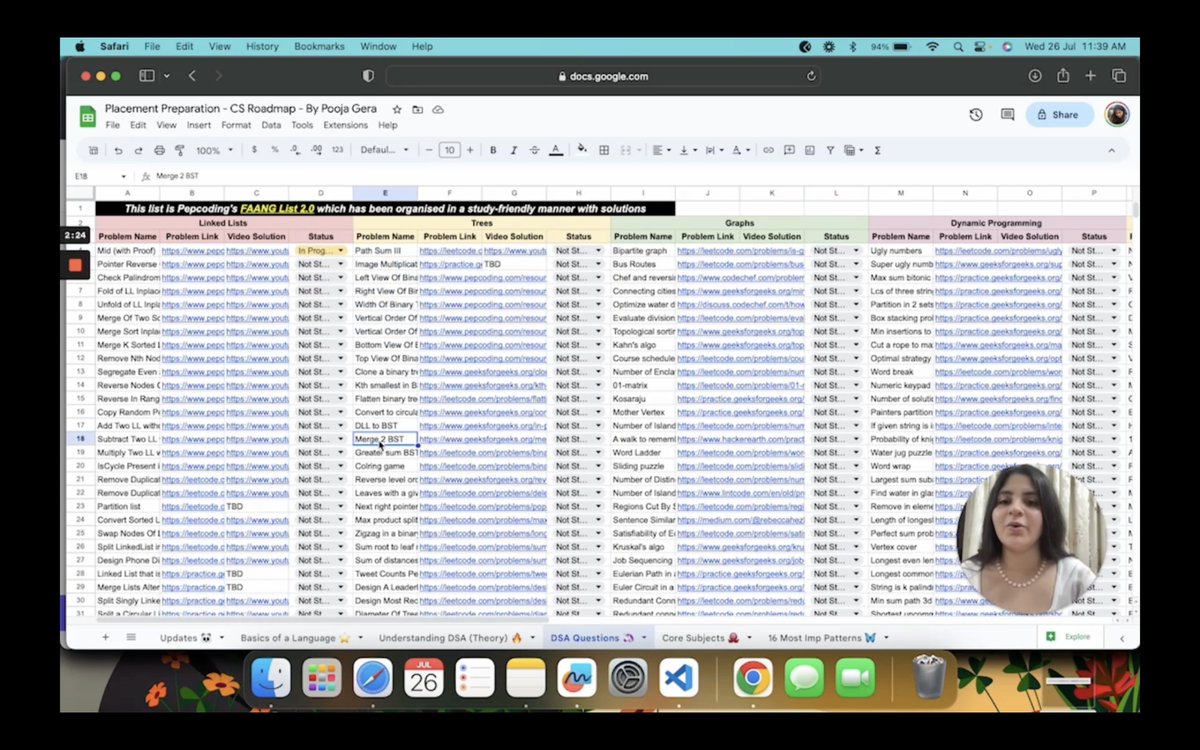
So I did something crazy yesterday - I combined 17,520 hours of grind into one sheet for CS placement preparation - this isn't a roadmap - it's a checklist - color coded and organised with resources, links and timestamps 🔥
Explainer Video + Sheet Here: cutt.ly/twaHx741
English

No. of patterns solved >>> No. of questions solved
Topic wise patterns on Leetcode:
1. Graph
leetcode.com/discuss/genera…
2. Binary Search
leetcode.com/discuss/genera…
3. Greedy
leetcode.com/discuss/genera…
4. Strings
leetcode.com/discuss/study-…
5. DP
leetcode.com/discuss/genera…
English
Do you struggle to communicate well during job interviews?
Try out these FREE tools to improve it:
1/ Poised
poised.com/use-cases/pois…
2/ Interview Warmup by Google
grow.google/certificates/i…
3/ Yoodly
app.yoodli.ai
English

Rejection of your paper or grant has NO relevance to the opinion of #research community. It is nothing but the opinion of one person.
Several examples:
1. The first paper on graphene was rejected from Nature because “it did not constitute a sufficient scientific advance”. Later, it was awarded a Nobel prize.
2. The first manuscript showing the microbiome-brain connection was published after 7 submissions that took 3 years. Today, this field has exploded. I expect it will get a Nobel prize in the future.
3. Theodore Maiman tried to publish a paper describing the first operating laser in Physical Review Letters and… got a rejection!
4. Peter Ratcliffe, who worked on cells’ response to changes in oxygen levels, got his key paper rejected from Nature (see photo). Later, he was awarded a Nobel Prize for this work.
And there are many other examples…
.
And yet I see so many young scientists stressing about rejections. For some reason, they seem to genuinely expect that the editors should know which study is truly worth it.
As a result, many rejections are met with surprise and disbelief:
“How could they reject it? They publish so much trash, and yet they think our detailed 3-year-long study is not interesting to the community! WHY?”
.
Well, the reality is:
- Most editors have very little time to delve into your study. They can easily FAIL to recognize the potential impact of your study. Proper communication in the cover letter and clear writing style can help (although only to a limited degree).
- Many reviewers have little idea about the science in your paper. But they can have a big ego. So, if they have a bad day or were rejected recently, it’s easy for them to find 1000 technical reasons to reject your paper as well.
- Most scientists genuinely don’t know if your discovery can make any impact. If we could predict the course of science, we would be living very differently!
My message is simple:
Forget about objectivity. Academia is a very subjective world. Fight for objectivity but don’t take it for granted.
A great study will be found, cited and recognized. Disregard of where it’s published.
A bad study requires a high-impact journal to be found and cited. But the long-time recognition might be a problem.
High-IF journals are simply billboards. Their rejections do NOT represent the opinion of a scientific community.
You can get rejected but don’t reject yourself!
Believe in your results.
#AcademicTwitter #AcademicChatter

English

Before age 40, you need to read these 10 books
1)

English

RIP online job interviews.
This AI tool enables real-time transcriptions for your microphone input AND speaker output.
It then generates a response for the user to answer questions based on the live conversation:
English