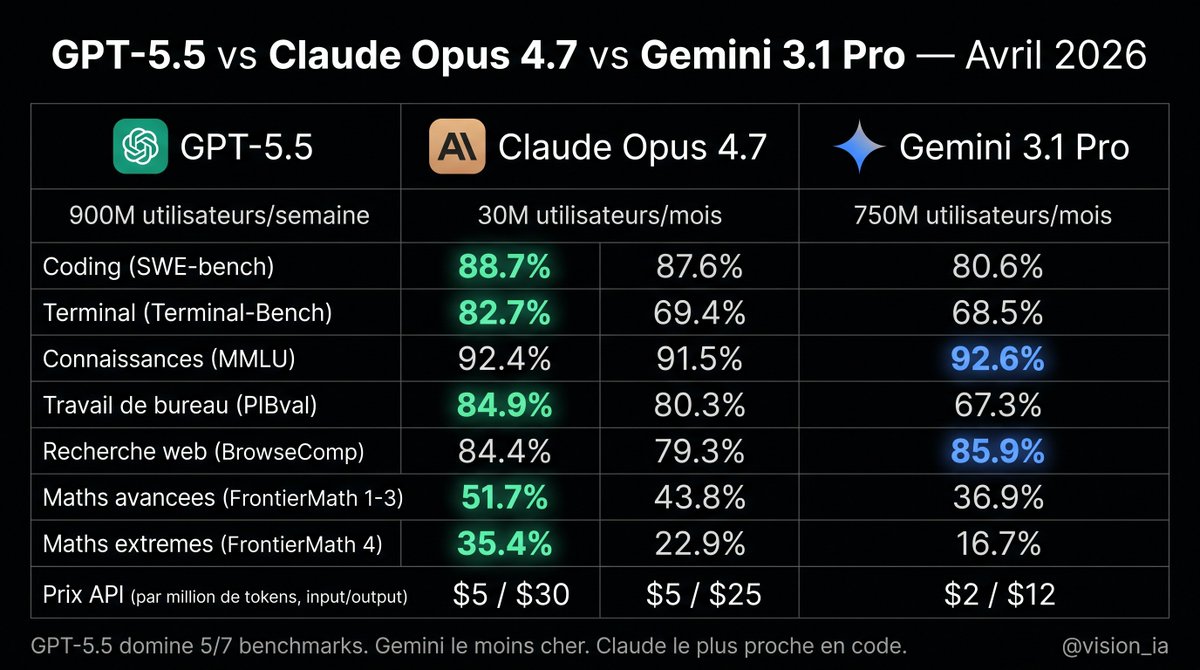
@jenzhuscott Je suis d'accord, DeepSeek-V4-Pro est le meilleur modèle pour les sous-agents, car il suit les instructions à la lettre. Mon workflow : GLM-5.1 joue le rôle d'agent orchestrateur, il délègue des tâches précises aux sous-agents, et tout est parfaitement exécuté par DeepSeek-V4-Pro
Français