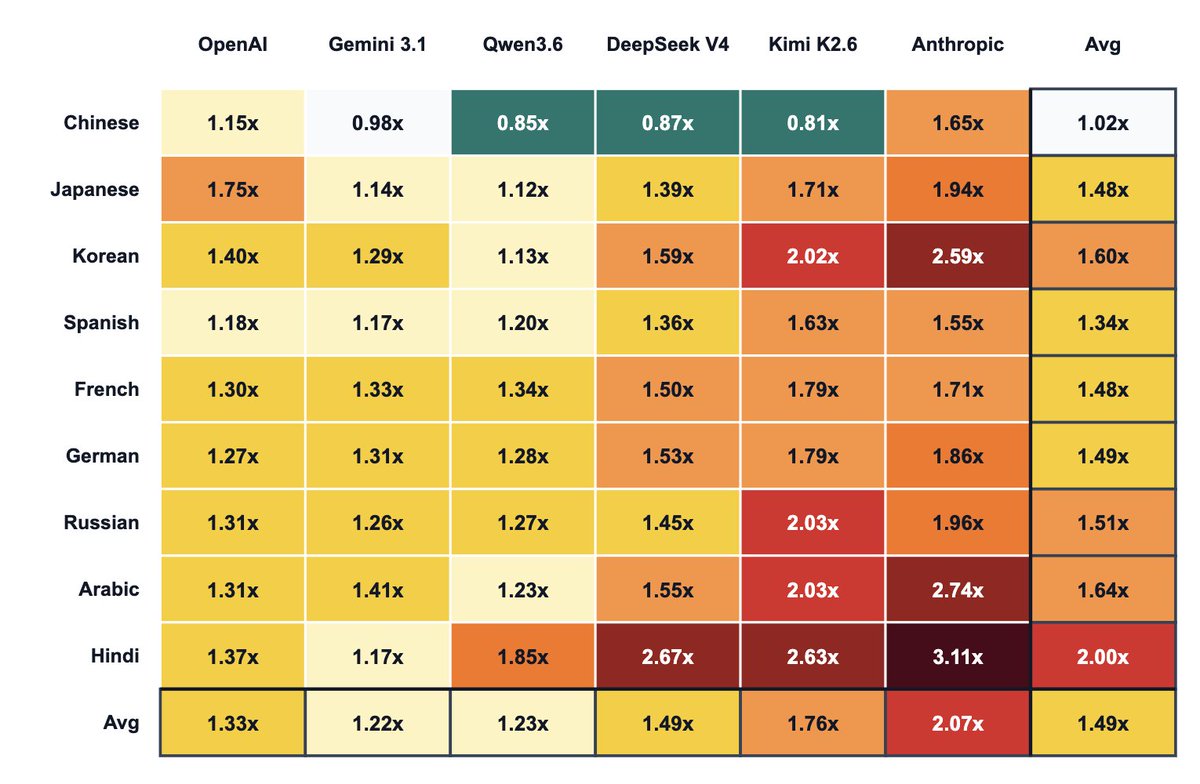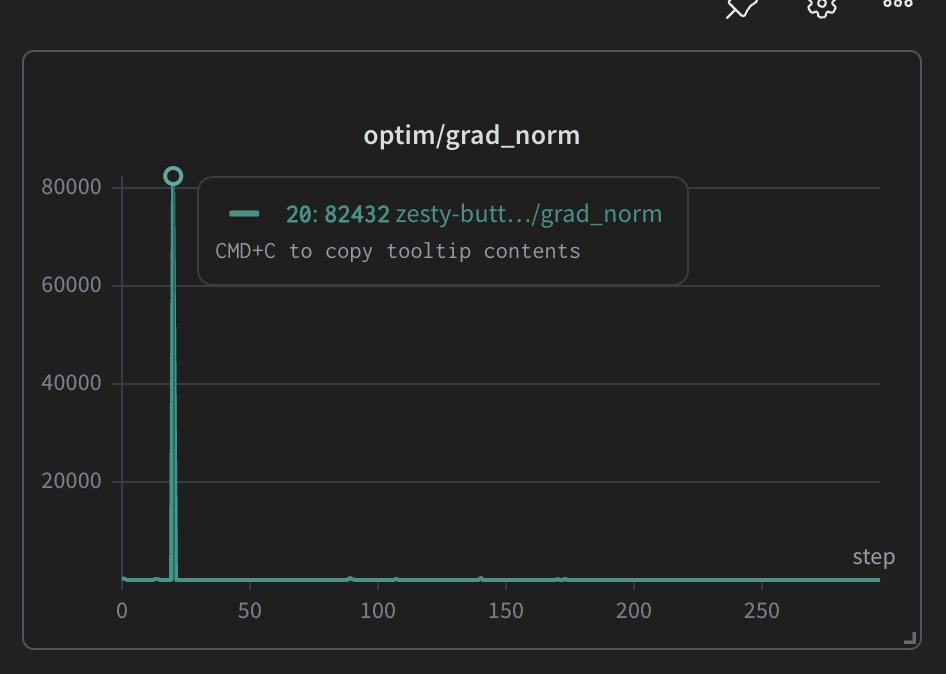

Also, the training node could be busy with someone else's run I just ask Claude code to poll and monitor in an interval, as soon as it's free Claude just starts the training without me knowing. Quite obvious usage but super fun to see when it happens.
English