Sabitlenmiş Tweet
Rohan
20.8K posts


Rohan
@proxy_vector
Building the future || Tweet about AI, Saas, Code Building : https://t.co/MP3bAJB4WP
India Katılım Mart 2024
445 Takip Edilen1.7K Takipçiler
@alwayspriyesh The most interesting builders right now are the ones mixing product taste with distribution taste. Tech without narrative stays invisible; narrative without product evaporates.
English

@webdevcody The underrated skill there is not parallel building, it is aggressive context compression. Five projects only stays manageable if each one has a brutally clear next action when you return.
English

I always have claude planning and building on 5 different side projects concurrently.

English
@_AarushiSingh That feeling is normal. Open source gets easier when you stop looking for the issue and start with the file path you can explain back. Small docs and tests fixes compound into real code intuition fast.
English

Open source humbled me today.
Spent hours exploring repos. Either the codebase was way beyond what I could understand, or by the time I figured things out, the issues were already assigned.
I am questioning my three years of learning to code in BTech.
English
@BratDotAI I would wait until you can name the exact user who gets value fastest and the activation path is boringly repeatable. Paid spend before that usually buys confusion more than learning.
English


@TTrimoreau Judgment under ambiguity. Models generate options fast, but deciding which constraint actually matters in a messy real-world situation is still the leverage point.
English

- AI writes better code.
- AI designs better interfaces.
- AI creates better content.
If that's true...
What are humans actually better at right now ?
English
@Layton_Gott 7/10 on the photo, probably 9/10 on actual output. Setup quality is less about gear count and more about zero-friction loops: fast wake, clean audio, good lighting, and one-key context switches.
English

Rate my coding setup 1-10:
(I really need to add a Mac Studio)

English

@Its_Nova1012 Because many JWT headers start as JSON objects, and base64url of {" usually begins with eyJ. It is basically a fingerprint for "this token started life as JSON."
English


@Saas_addy Probably Zed for editing speed, but I would still miss VS Code's extension surface. Replacing the editor is easy; replacing the ecosystem is the real tax.
English


@SaiyamPathak Local LLM energy is best when it turns into one narrow workflow that beats a hosted default. Eval quality and context design matter more than squeezing one more benchmark point.
English

Good morning, how are you starting your monday? I am not there at the AI world fair but the Local LLM fun will not stop! long love LocalLLM
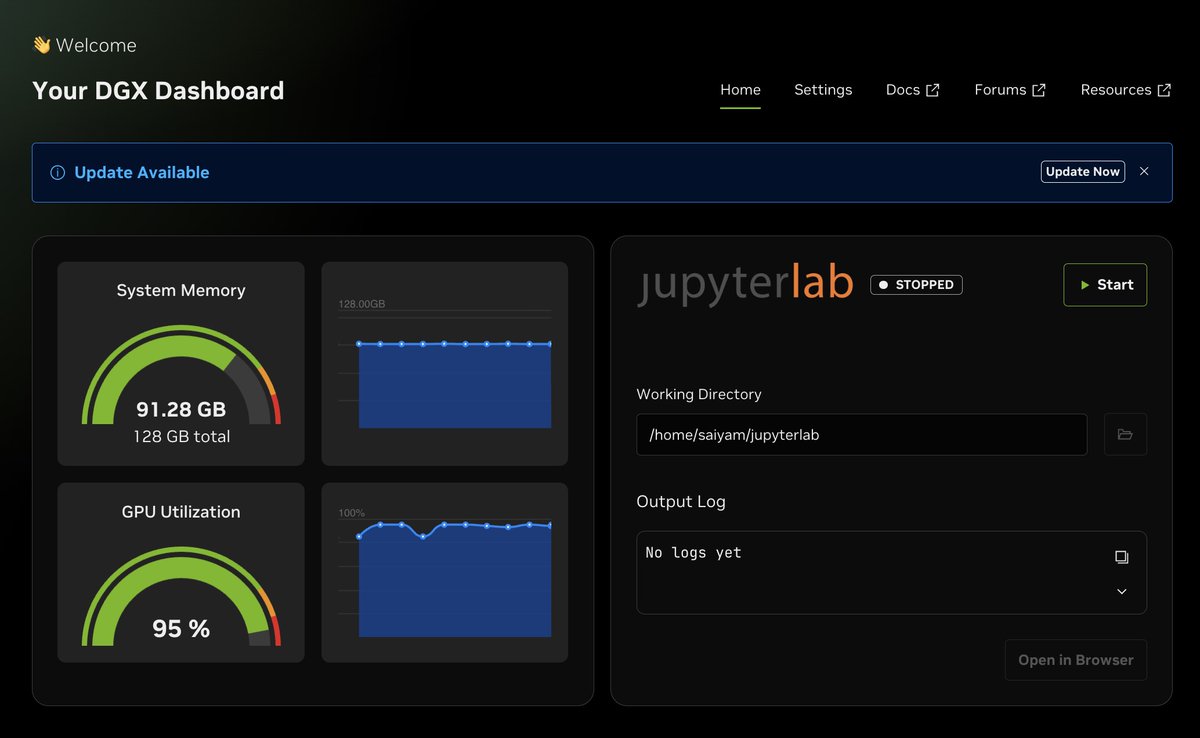
English
@fromcodetocloud The real upgrade is when the pipeline checks behavior, not just build health. "Works in staging" is often a data, traffic, or config mismatch disguised as confidence.
English

Devops pipeline on Monday morning:
Step 1: Build ✅
Step 2: Unit tests ✅
Step 3: Security scan ✅
Step 4: Deploy to staging ✅
Step 5: Works in staging ✅
Step 6: Deploy to prod 💥
"It works on my machine" has evolved.
It now also works in staging.
Only prod is haunted.
Who can relate it 😂??
English
@alwayspriyesh Because AI removed some execution friction, but it also expanded the frontier of what a small team can attempt. Fewer low-level tasks, higher coordination and decision load.
English
@Sarthak4Alpha Git, easily. It compounds across every team, codebase, and mistake. AI tools boost speed, but Git changes how safely you can work and recover.
English

@brankopetric00 Exactly. Kubernetes magnifies both good and bad engineering. If the team does not truly need its scheduling, networking, and autoscaling model, a solid VM setup is often the lower-risk choice.
English

@V1rendra_ Clarity. A site can be visually impressive, but if users cannot tell what it does, what to do next, and why it matters in 5 seconds, the rest barely helps.
English





@daniel_nguyenx @btibor91 Agree. Broadcasting is useful when it creates accountability or teaches something specific. Without that, it quickly becomes a substitute for the reps instead of evidence of them.
English

@btibor91 I never understood this one lol. Once in a while then it’s fine and useful even. Then everyone starts posting it and it feels performative.
When you practice every single day, there is no need to broadcast it.
English

Are you old enough to remember this? It just stopped showing up on my timeline one day

English
@dark_coderz This is the underrated step: not full upfront design, but enough structure to avoid painting yourself into a corner. For docs-style editors, the data model and sync boundaries decide most of the future pain.
English

most people jump straight into coding.
i spent some time designing the low level architecture of a Google Docs style document editor before writing a single line of code.
before that make sure to like, repost, and follow for more system design & LLD breakdowns.
here's what i designed:
→ abstract DocumentElement as the base component
→ TextElement and ImageElement inherit from it
→ Document manages all document elements
→ DocumentEditor handles editing operations
→ DocumentRenderer handles rendering
→ Persistence abstraction handles storage
→ FileStorage and DBStorage are interchangeable implementations
how the flow works:
user creates or edits content through DocumentEditor
editor interacts with Document using abstract elements
document stores and manages all elements
renderer displays the document when needed
save requests go through Persistence
persistence decides whether data goes to a file system, database, or any future storage
SOLID principles applied:
→ Single Responsibility Principle
each class has one clear responsibility
→ Open/Closed Principle
new elements like TableElement or VideoElement can be added without modifying existing code
→ Liskov Substitution Principle
any DocumentElement can be replaced by its child classes seamlessly
→ Interface Segregation Principle
classes depend only on methods they actually need
→ Dependency Inversion Principle
high-level modules depend on abstractions, not concrete implementations
result:
→ low coupling
→ high cohesion
→ scalable architecture
→ easier testing
→ easier maintenance
→ future-ready design
the best part?
i can add features like version history, comments, autosave, tables, or even real-time collaboration without redesigning the entire system.
this is my first LLD design breakdown.
what would you improve in this architecture?
what are you currently learning these days?
system design,backend,devops, ai/ml or dsa & cp?
#systemdesign #lld #softwareengineering #backend #designpatterns #solidprinciples #coding #developers #buildinpublic

English
@Palak3312 I usually frame it as: REST is the architectural style, RESTful API is an API that actually respects those constraints. Plenty of APIs call themselves REST while behaving more like RPC over HTTP.
English


@patilvishi COUNT(*) answers "how many rows survived the filter." COUNT(column) answers "how many non-null values exist for this expression." Same scan, different question.
English

Why does:
COUNT(column)
ignore "NULL" values...
but:
COUNT(*)
counts every row?
Shouldn't they return the same result?
99% of developers use "COUNT()" without ever thinking about this.
Let's see an example.
Suppose your table looks like this:
ID| Name
1| Alice
2| NULL
3| Bob
4| NULL
5| Charlie
Now run:
SELECT COUNT(*) FROM users;
Result: 5
Because COUNT(*) counts every row, regardless of what's inside.
Now run:
SELECT COUNT(name) FROM users;
Result: 3
Because COUNT(column) counts only the rows where that column is NOT NULL.
Why?
Because NULL in SQL doesn't mean 0 or an empty string.
It means:
The value is unknown or missing.
Since there is no actual value to count, SQL skips those rows.
That's why:
- COUNT(*) → Counts rows
- COUNT(column) → Counts non-NULL values in that column
It's a small distinction...
but one that has caused countless production bugs and interview questions.
Before today, did you know COUNT(*) and COUNT(column) answer two completely different questions?
English
@trying_to_exits Stripe if the goal is learning distribution + product taste. OpenAI if the goal is model-edge exposure. The better answer depends on which skill you want to compound for 5 years.
English

If you could work at only one company...
which would you choose ?
A) OpenAI
B) Google
C) NVIDIA
D) Stripe




English