Sabitlenmiş Tweet

There is nothing like limit. It's in your brain. Transcend yourself. Don't fucking give up no matter what
English
Punit Vara
1.6K posts

@punitvara
RNN - LSTM - Attention - Transformer - LLM - Increase context window - Quantization for on device - Reasoning LM - Tiny RM Machine Learning Engineer


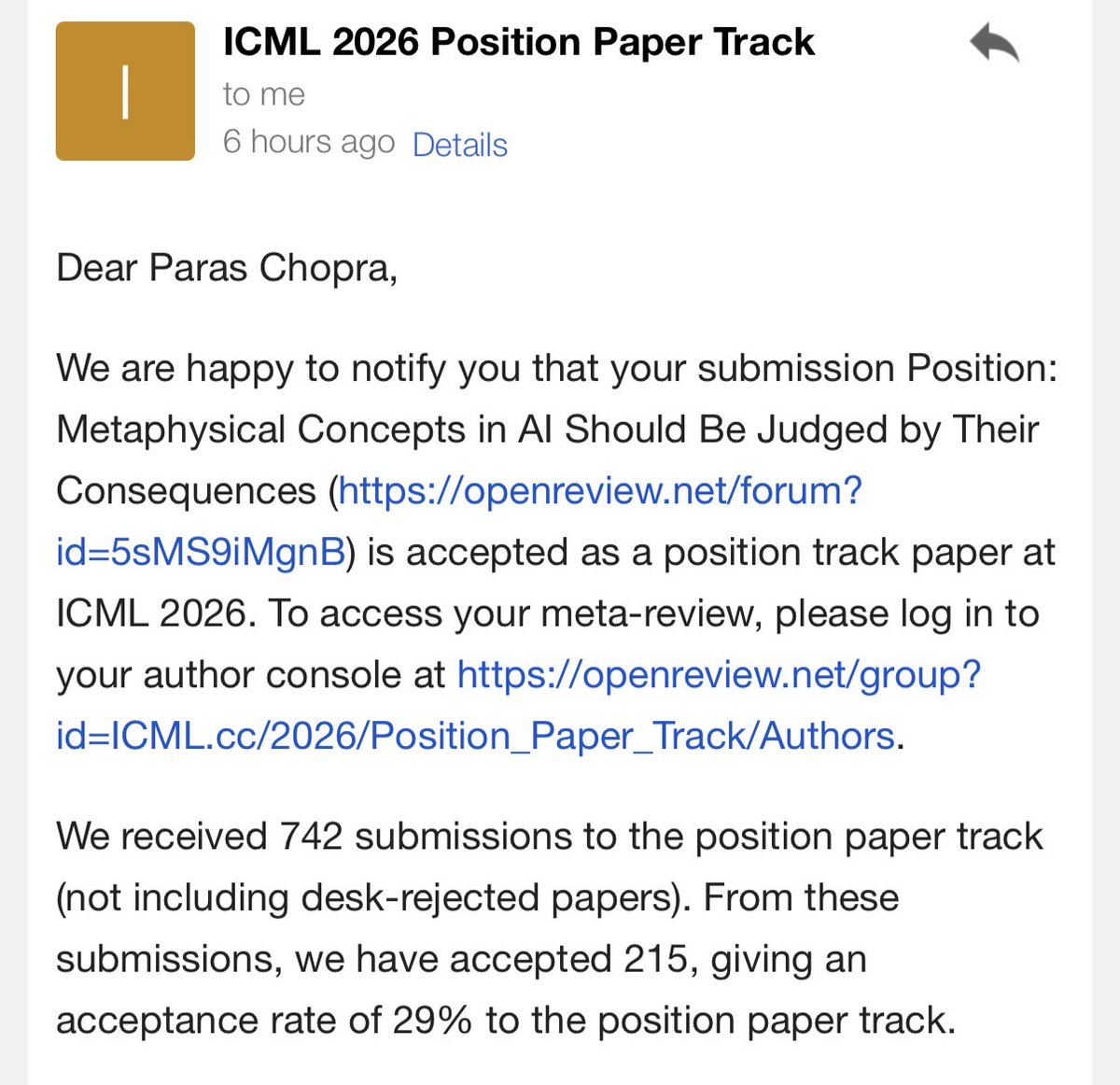

New work with @AlecRad and @DavidDuvenaud: Have you ever dreamed of talking to someone from the past? Introducing talkie, a 13B model trained only on pre-1931 text. Vintage models should help us to understand how LMs generalize (e.g., can we teach talkie to code?). Thread:

Open letter to Indians in America. -- Dear brothers and sisters from Bharat: Like I did 37 years ago, you arrived in America with no money but with a good education and cultural heritage from Bharat. You achieved outstanding success. America was good to us. For that we must remain grateful - gratitude is our Bharatiya way. Yet today, a significant number of Americans, may be not the majority but not too far from it either, believe that Indians "take away" American jobs and our success in America was unfairly earned. You may think the next election will fix this, but your choice would be between people who hate our Bharatiya civilisation and people who hate civilisation itself. That is the "hard right" vs "woke left" battle. You are mere bystanders to that conflict. Meanwhile there is one thing that is true now and will be true in the future: the respect Indians command world-wide will substantially depend on the fortunes of India herself. If India remains poor, the woke left will give us moral lectures with pity and the hard right, different moral lectures with scorn ("hellhole") and we must not confuse either with respect. Respect in today's world, along with prosperity and security, comes from one source: a nation's technological prowess. India produces sufficient brain power to achieve that prowess but alas we exported so much of that talent, particularly to America. As we develop that prowess in India, our civilisational strength will assert itself. As difficult as it is for many of you to contemplate this, please come back home. Bharat Mata needs your talent. Our vast youthful population needs the technology leadership you gained over the years to guide them towards prosperity. Let's do it with a missionary zeal. Respectfully Sridhar Vembu
Sam Altman: “Most people don’t take enough risk” “I think people have terrible risk calculus in general… almost always A) you’re wrong about what is risky and what is not risky, and B) most people don’t take enough risk—especially early in your career. Being young, unknown, and poor, is actually a great gift in terms of the amount of risk you can take.” Sam continues: “I think what risk actually looks like is not doing something that you will spend the rest of your life regretting… So if you really believe in something—if there’s an idea you’re super passionate about—and you take a calculated risk to start a company realizing you may forego a couple of years of steady income and maybe people call you a failure, that’s a great risk to take. And if you don’t take that risk, I think you have a very high chance that you end up regretting that.” Sam believes most people overrate the risk of reputation damage and embarrassment from trying and failing. It’s worse to not even try: “One really important thing to strive for in your career is to be a doer, not a talker. And the reason that people don’t do stuff is 1) it’s hard, and 2) it’s risky. And so you have these people that want to dabble in a bunch of different projects, but never be all-in on one… I think that’s really bad. I think history belongs to the doers, and I think you should take a risk and actually do something.” Video source: @ycombinator (2016)




Introducing ml-intern, the agent that just automated the post-training team @huggingface It's an open-source implementation of the real research loop that our ML researchers do every day. You give it a prompt, it researches papers, goes through citations, implements ideas in GPU sandboxes, iterates and builds deeply research-backed models for any use case. All built on the Hugging Face ecosystem. It can pull off crazy things: We made it train the best model for scientific reasoning. It went through citations from the official benchmark paper. Found OpenScience and NemoTron-CrossThink, added 7 difficulty-filtered dataset variants from ARC/SciQ/MMLU, and ran 12 SFT runs on Qwen3-1.7B. This pushed the score 10% → 32% on GPQA in under 10h. Claude Code's best: 22.99%. In healthcare settings it inspected available datasets, concluded they were too low quality, and wrote a script to generate 1100 synthetic data points from scratch for emergencies, hedging, multilingual etc. Then upsampled 50x for training. Beat Codex on HealthBench by 60%. For competitive mathematics, it wrote a full GRPO script, launched training with A100 GPUs on hf.co/spaces, watched rewards claim and then collapse, and ran ablations until it succeeded. All fully backed by papers, autonomously. How it works? ml-intern makes full use of the HF ecosystem: - finds papers on arxiv and hf.co/papers, reads them fully, walks citation graphs, pulls datasets referenced in methodology sections and on hf.co/datasets - browses the Hub, reads recent docs, inspects datasets and reformats them before training so it doesn't waste GPU hours on bad data - launches training jobs on HF Jobs if no local GPUs are available, monitors runs, reads its own eval outputs, diagnoses failures, retrains ml-intern deeply embodies how researchers work and think. It knows how data should look like and what good models feel like. Releasing it today as a CLI and a web app you can use from your phone/desktop. CLI: github.com/huggingface/ml… Web + mobile: huggingface.co/spaces/smolage… And the best part? We also provisioned 1k$ GPU resources and Anthropic credits for the quickest among you to use.

Our goal is to build practical models with comprehensive capabilities beyond open benchmarks. And the only way to do it to co-design with diverse products while scaling solidly. Tencent has the best product ecosystem and a solid, low-ego culture, and we are just getting started!







