Quan Wei retweetledi

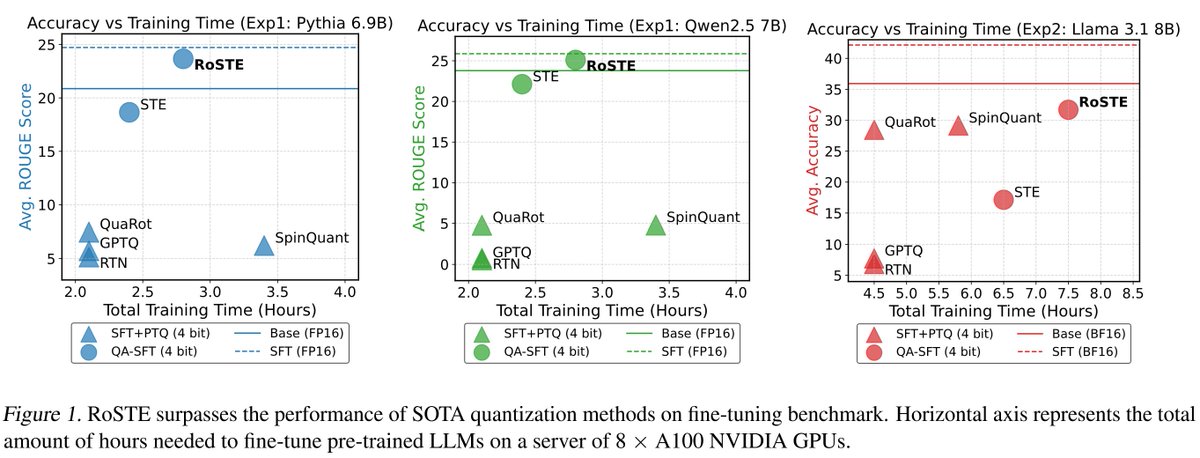
RoSTE: An Efficient Quantization-Aware Supervised Fine-Tuning Approach for Large Language Models (icml.cc/virtual/2025/p…) with @quanwei0 & @yauchungyiu on Wed 16 Jul 11am-1:30pm East Hall (3/3).

English
Quan Wei
6 posts


new paper with @ZengSiliang and other collaborators about some of our multi-turn findings from the past couple months :) lots of experiments about the pros and cons of structured rewards and credit assignment, particularly relevant when doing tool-use RL with 7B models