@dprophecyguy @ryanvogel @steipete insanely dumb for 99.99% of people, but considering he effectively has unlimited tokens it's not a bad idea
English
wqite
53 posts



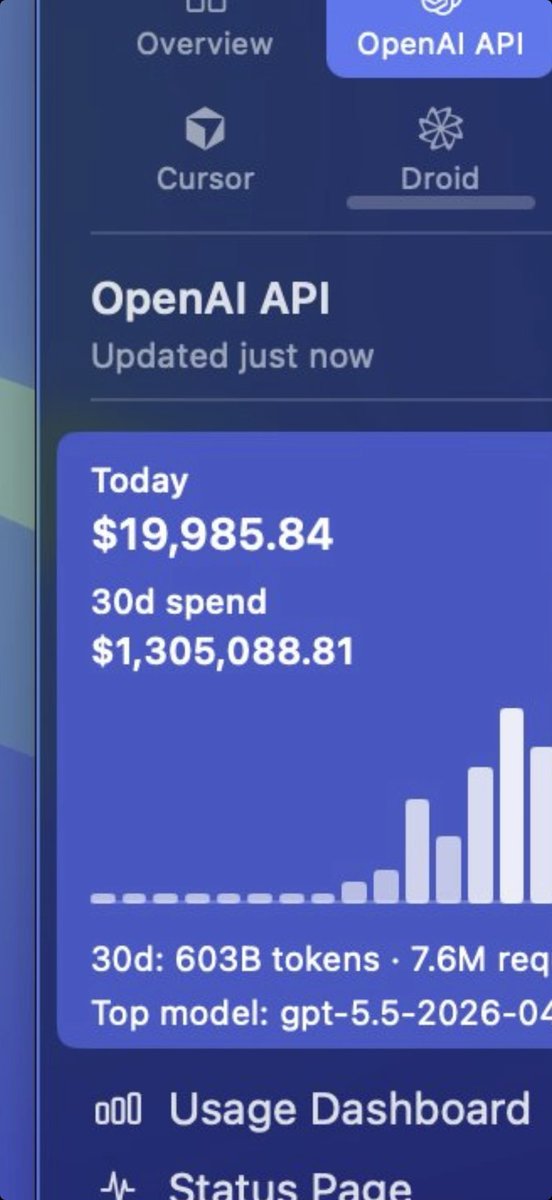

run codex on every commit



How much of SQLite, FFmpeg, PHP compiler can LMs code from scratch? Given just an executable and no starter code or internet access. Introducing ProgramBench: 200 rigorous, whole-repo generation tasks where models design, build, and ship a working program end to end. 🧵








I feel sorry for Claude Code I know they're not the one. I'm not overcommitting - not investing too hard I wonder if they know I'm pulling away