Sabitlenmiş Tweet
Rafa
2.7K posts


Rafa
@rafa_maker
Company hackathons 👉 https://t.co/1KvBTYwKZe Local voice notes & mettings app 👉 https://t.co/0zMcN4Yr69 - All my projects 👉 https://t.co/dYLMn0hjSP
Barcelona Katılım Nisan 2008
894 Takip Edilen1.3K Takipçiler

I’m kind of doing this for speakhapi.com but for all your transcripts!
Andrej Karpathy@karpathy
LLM Knowledge Bases Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So: Data ingest: I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them. IDE: I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides). Q&A: Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale. Output: Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base. Linting: I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into. Extra tools: I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries. Further explorations: As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows. TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English

Need help from builder community in Barcelona 🙏 please talk to @mattdotroberts
Matt@mattdotroberts
I need to speak to women (and the rest) who use @claudeai in Barcelona Please comment and reshare
English
Hapi is getting Claude Code friendly
Matt@mattdotroberts
rafa is cooking for speakhapi prebuilt commands for claude code
English


i run a 180+ ai curious whatsapp community.
Claude takes the chats, rips out a digest for whatsapp and online
Creates a live dashboard to understand behaviour
Makes sure the community get the sauce not all the noise
explained it here and see the comments if you want to hit the digest
English

Granola was overkill for my markdown note setup, so I had Claude build a fully local transcription CLI with a skill that works great and composes well with others.
Read more: hrescak.com/notes/transcri…
English

This was yesterday
A room full of hackers discovering the power of skills for @hackbarna “skill a thon” at @itnig in Barcelona 🤩
People built skills to help meal planning, help with cold emails, or run a11y tests.

English
@mattdotroberts @cjpedregal We actually have this set up already for speakhapi.com - connected to Claude seamlessly
English
@cjpedregal Ok back to the drawing board @rafa_maker
It does show there’s a need
English

There are some tweets out there saying that Granola is trying to lock down access to your data.
Tldr; we are actually trying to become more open, not closed. We’re launching a public API next week to complement our MCP. Read on for context.
A couple months ago, we noticed that some folks had reversed engineered our local cache so they could access their meeting data.
Our cache was not built for this (it can change at any point), so we launched our MCP to serve this need. The MCP gives full access to your notes and transcripts (all time for paid users, time restricted for free users). MCP usage has exploded since launch, so we felt good about it.
A week ago, we updated how we store data in our cache and broke the workarounds. This is on us. Stupidly, we thought we had solved these use cases well enough with our MCP.
We’ve now learned that while MCPs are great for connecting to tools like Claude or chatGPT, they don’t meet your needs for agents running locally or for data export / pipeline work.
So we’re going to fix this for you ASAP. First, we’ll launch a public API next week to make it easier for you to pull your data.
Second, we’ll figure out how to make Granola work better for agents running locally. Whether that’s expanding our MCP, launching a CLI, a local API, etc. The industry is moving quickly here, so we’d appreciate your suggestions.
We want Granola data to be accessible and useful wherever you need it. Stay tuned.
English
Nice take
Coordinating humans in a group is a pain in the ass.
Coordinating 2 founders to the next shiny toy.
Easy
Ain’t that right @rafa_maker
Dan Shipper 📧@danshipper
another corollary: this is one reason why very small teams are better in AI. it's much easier to start over if you don't have to coordinate amongst a large number of people @every we run each product with just a single GM—what i call a two-slice team: every.to/chain-of-thoug…
English
This is going to be wild if you are in Barcelona Thursday next week 👇
Nicolas Grenié@picsoung
Barcelona Skill-a-thon is sold out!🤯 in only 2 days, y'all claimed 70 spots! We just added more seats. Builders gonna build! @openclaw @claudeai @kilocode @cline @CloudflareDev want to help with pizzas?😜 luma.com/0y5sebvx
English

por esto cuando me hablan ahora de "crear contenido" (por VISIBILIDAD reasons) realmente solo quiero llorar. son super dark times, yo solo quiero hablar de las cosas que me gustan y que eso aiude a mi negocio no puedo con el performativismo continuo, we have to go back 😢
Noa Gresiva@NoaGresiva
Buenos días solo a él.
Español
Tested Hapi at the first @AnthropicAI event in Barcelona — seated far from the stage, barely hearing the speakers.
✅ Hapi caught every word anyway. Filtered filler, fixed errors, made sense of it all in real time.
Very nice feeling when things work! 👇
English
🎉 Big Hapi update for Hapi:
→ Qwen 3.5 models now power content repurposing (huge quality jump)
→ Redesigned automation UI
→ Self-correction system for AI outputs
→ Faster, lighter performance
Still 100% local. Still one-time purchase. Free while Beta
#BuildInPublic
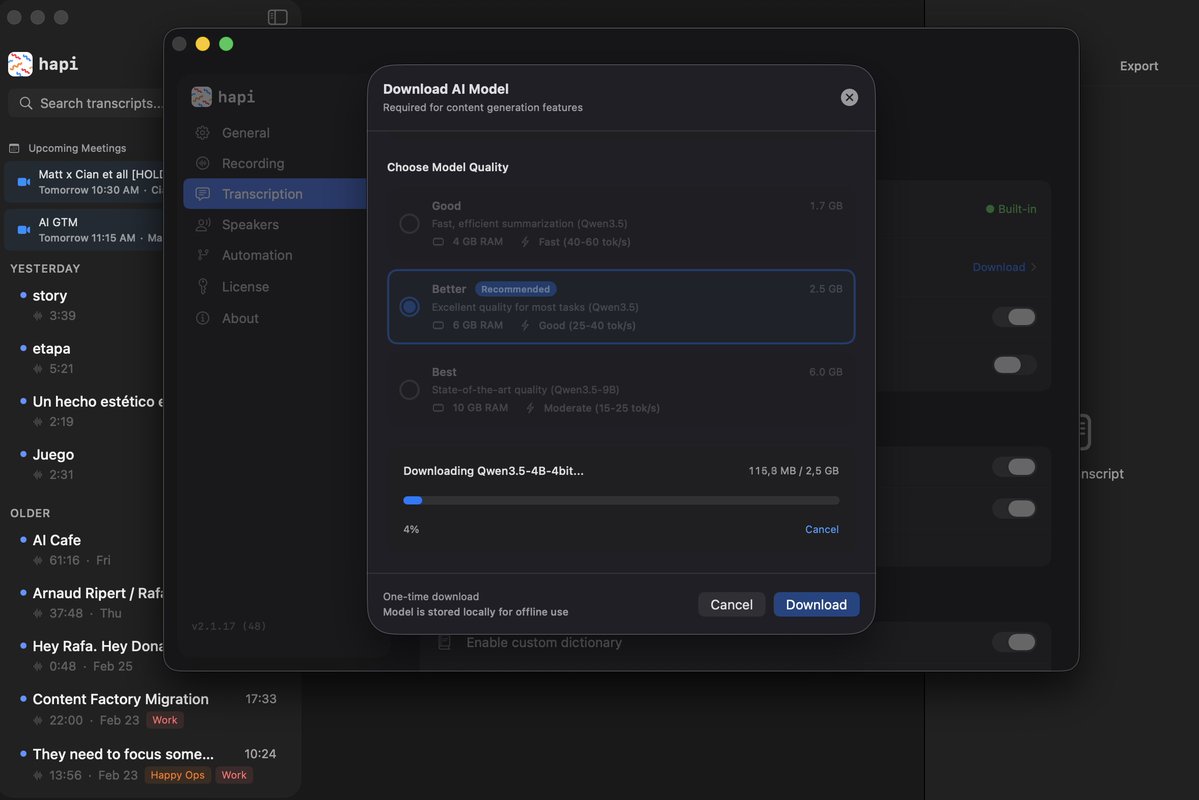
English
mi mayor miedo cuando delego procesos tan grandes como el del rediseño de aprendenotion.com es si luego seré independiente en el mantenimiento, así q cuando le he pedido a Claude una guía con todo y me ha escrito hasta los prompts para pedirle cosas, he LLORADO
GIF
Español