ragas retweetledi

(1/n) Today, we’re releasing Cloning Bench.
Labs are paying 6-7 figures for clones of web apps to do web/computer use-based RL training.
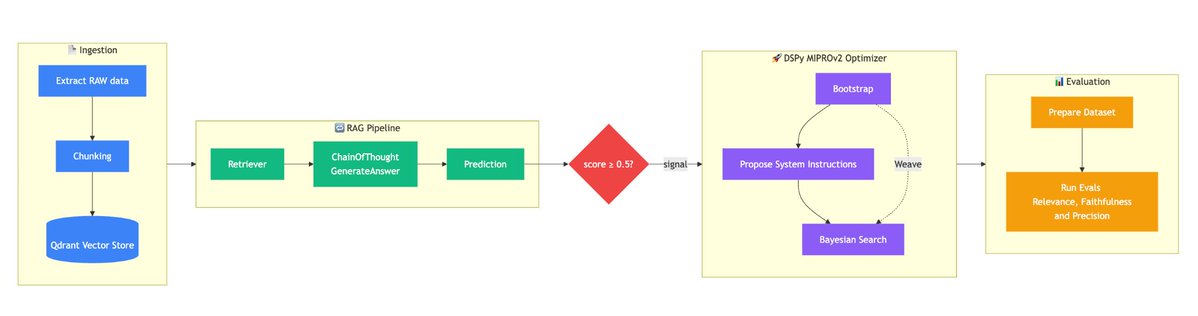
At @VibrantLabsAI , our fundamental goal is to automate the creation of RL environments. For web/CUAs, one way that we do that is by using coding agents and custom harness to automatically generated the simulation environment.
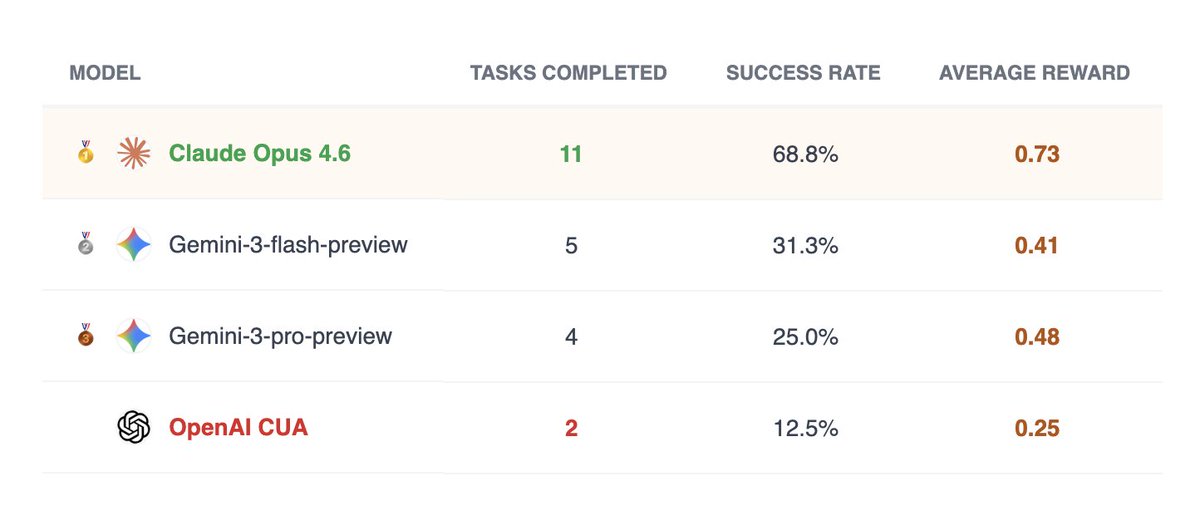
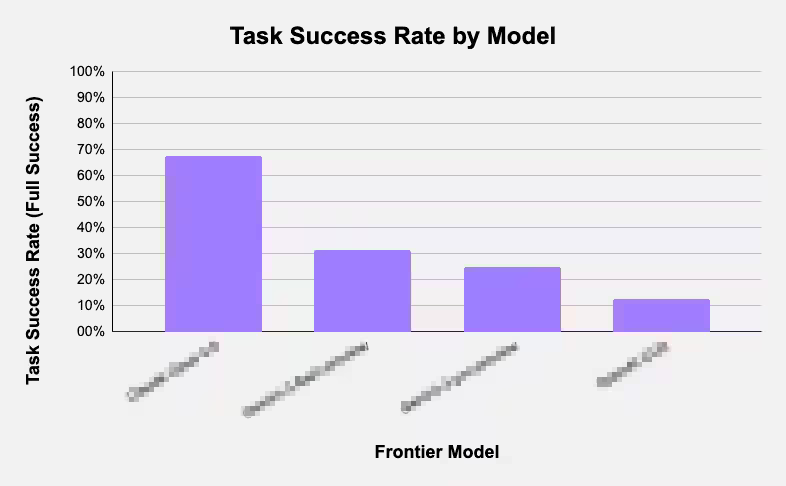
We tested Codex, Gemini, Claude Code, and GLM using our harness on their ability to recreate a Slack workspace and benchmarked their performances.
We have published our methods, results and analysis here today: vibrantlabs.com/blog/cloning-b…

English