Sabitlenmiş Tweet
R 🌙
41.3K posts


R 🌙
@ramlugo_
♍️♎️♑️ INTJ 5w6 | VADE 💚 | Tech, football, movies and more 🧑🏽💻⚽️
Mexico City Katılım Eylül 2014
334 Takip Edilen360 Takipçiler

R 🌙 retweetledi

R 🌙 retweetledi

The club celebrating Vincent Kompany's 40th birthday at Säbener Straße today
The coach's parents were there as well
🎥 @FCBayern
English
R 🌙 retweetledi

If you are committed in your twenties, you miss out on the experience of enjoying your prime years as a single fellow; and if you are single, you are miss out on the experience of young love. The grass isn't greener on any side. Or maybe, the grass is green on both the sides.
English
R 🌙 retweetledi

R 🌙 retweetledi


R 🌙 retweetledi


R 🌙 retweetledi

R 🌙 retweetledi

R 🌙 retweetledi

oh the warmth of being considered safe by something so much smaller than you
♡@__Tanya7__
I would melt instantly
English
R 🌙 retweetledi

When you give her head first time and her 🐱 PH is well balanced 🌚
English
R 🌙 retweetledi

stuff like this sounds stupid until you turn like 23
Nature Videos@naturevideos
"When you die, you can't see sunsets." ― Hayao Miyazaki
English
R 🌙 retweetledi

R 🌙 retweetledi

R 🌙 retweetledi


R 🌙 retweetledi

Esto y entender que podemos no estar de acuerdo en algo y seguir amándonos.
Out Of Context Monkeys@Contextmonkeyz
Us
Español
R 🌙 retweetledi

R 🌙 retweetledi

R 🌙 retweetledi

R 🌙 retweetledi

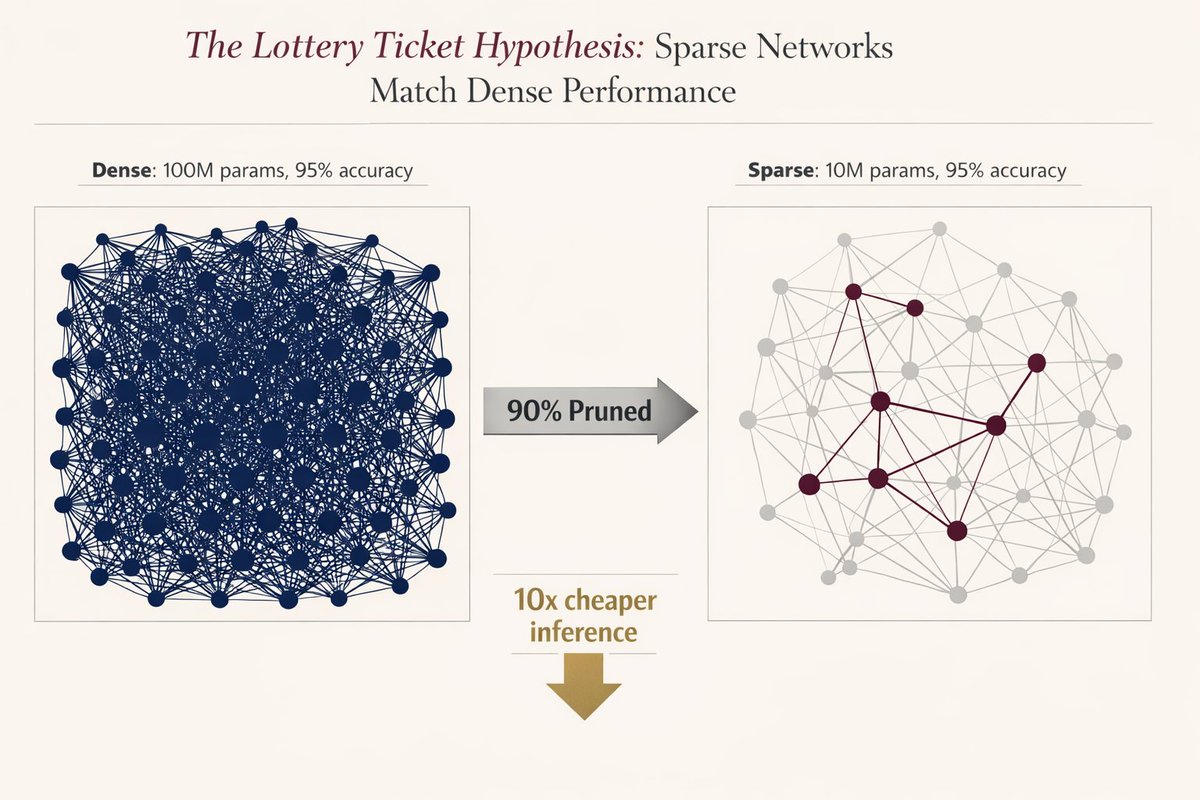
🚨 MIT proved you can delete 90% of a neural network without losing accuracy.
Researchers found that inside every massive model, there is a "winning ticket”, a tiny subnetwork that does all the heavy lifting.
They proved if you find it and reset it to its original state, it performs exactly like the giant version.
But there was a catch that killed adoption instantly..
you had to train the massive model first to find the ticket. nobody wanted to train twice just to deploy once. it was a cool academic flex, but useless for production.
The original 2018 paper was mind-blowing:
But today, after 8 years…
We finally have the silicon-level breakthrough we were waiting for: structured sparsity.
Modern GPUs (NVIDIA Ampere+) don’t just “simulate” pruning anymore.
They have native support for block sparsity (2:4 patterns) built directly into the hardware.
It’s not theoretical, it’s silicon-level acceleration.
The math is terrifyingly good: a 90% sparse network = 50% less memory bandwidth + 2× compute throughput. Real speed.. zero accuracy loss.
Three things just made this production-ready in 2026:
- pruning-aware training (you train sparse from day one)
- native support in pytorch 2.0 and the apple neural engine
- the realization that ai models are 90% redundant by design
Evolution over-parameterizes everything. We’re finally learning how to prune.
The era of bloated, inefficient models is officially over. The tooling finally caught up to the theory, and the winners are going to be the ones who stop paying for 90% of weights they don’t even need.
The future of AI is smaller, faster, and smarter.
English