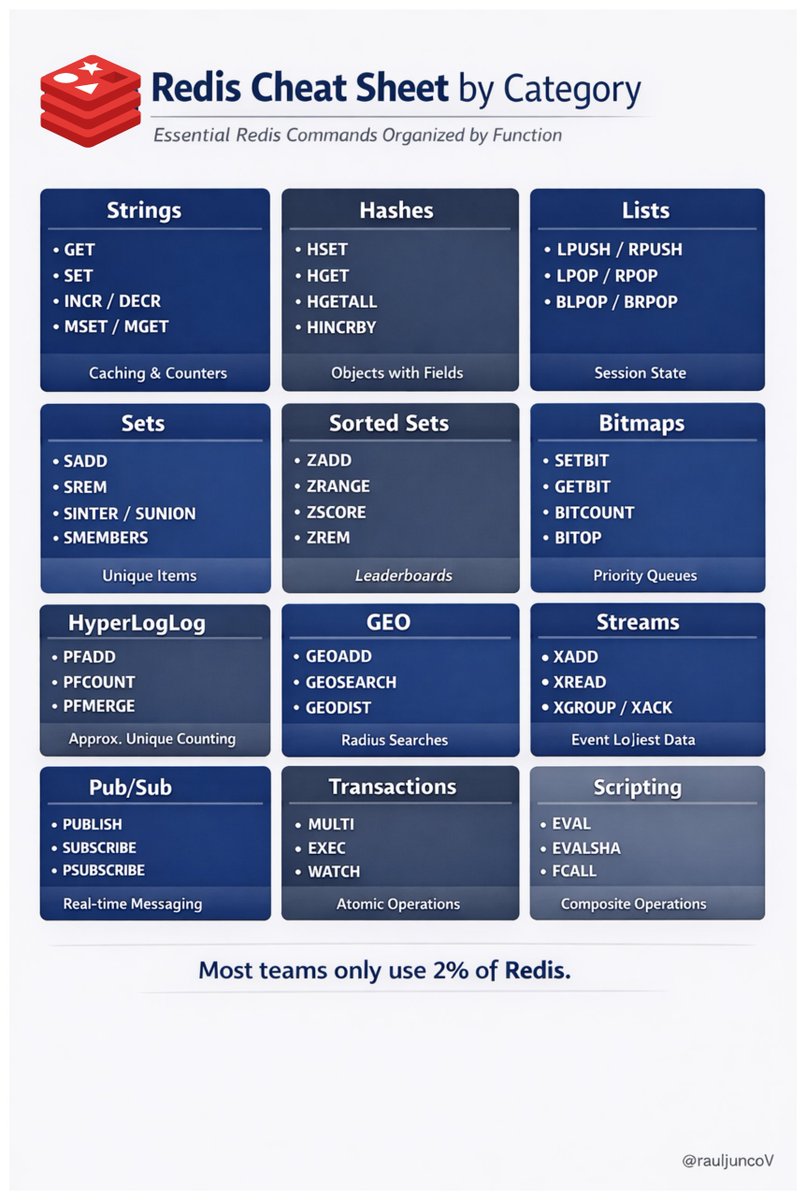
Hot take: most teams only use 2% of Redis.
The other 98% sits there ignored while teams add more infrastructure.
A lot of teams use Redis for:
> GET
> SET
> EXPIRE
> DEL
And stop there.
Meanwhile Redis has commands for:
- rankings
- queues
- streams (I’ve seen teams spin up Kafka-like stacks when Redis streams would have been enough)
- approximate counting
- geospatial lookups
- bit-level state tracking
- atomic counters
- Lua scripts
- pub/sub
A lot of “we need another component” conversations are really
“we never learned the component we already have.”
That is my favorite kind of technical debt.
Expensive problems caused by cheap ignorance.
What Redis feature made you realize it was more than just a cache?
𝗦𝗦𝗢 (𝗦𝗶𝗻𝗴𝗹𝗲 𝗦𝗶𝗴𝗻-𝗢𝗻) 𝗲𝘅𝗽𝗹𝗮𝗶𝗻𝗲𝗱
SSO is an authentication process that allows users to access multiple apps with a single master key.
This is accomplished using a central authentication server that stores the user's credentials and verifies them for each application.
Here are 𝘁𝗵𝗲 𝘀𝘁𝗲𝗽𝘀 that happen if you want to access the Trello web app by using your Google account:
1. Use the Trello login web page and select Google account as a login method
2. Trello redirects the user to the Google login page
3. User is served with the Google login page
4. The user enters their Google credentials
5. Google sends authentication info to the SSO Authorization server
6. If credentials are valid, the Authorization server returns the auth token (SAML)
7. Google sends the auth token to the Trello
8. In the last step, Trello sends the token to the Google Authentication server to validate its
9. If the token is valid, Trello will allow access to the user and store the session for future interactions
✅ The 𝗯𝗲𝗻𝗲𝗳𝗶𝘁𝘀 of SSO are:
🔹 Improved user experience. Users do not need to remember multiple usernames and passwords.
🔹 Increased security. Users are less likely to reuse passwords across applications.
❌ The 𝗱𝗶𝘀𝗮𝗱𝘃𝗮𝗻𝘁𝗮𝗴𝗲𝘀 are:
🔸 Single point of failure. One of the most notable disadvantages is that SSO creates a single point of failure. If the SSO system is compromised, the attacker could access all connected applications and services.
🔸Security risks. If credentials are compromised, the security of all connected applications could be at risk.
Some 𝗰𝗼𝗺𝗺𝗼𝗻 𝘁𝘆𝗽𝗲𝘀 𝗼𝗳 𝗦𝗦𝗢 are:
🔹 𝗦𝗔𝗠𝗟-𝗯𝗮𝘀𝗲𝗱 𝗦𝗦𝗢. This is the most common type of SSO. It uses the SAML protocol to exchange authentication information between the SSO server and applications.
🔹 𝗢𝗽𝗲𝗻𝗜𝗗 𝗖𝗼𝗻𝗻𝗲𝗰𝘁. This is a newer SSO type based on OAuth 2.0. It is a more straightforward protocol than SAML and is easier to integrate with web applications.
And 𝗽𝗼𝗽𝘂𝗹𝗮𝗿 𝗦𝗦𝗢 𝘀𝗼𝗹𝘂𝘁𝗶𝗼𝗻𝘀 are:
➡️ Azure Active Directory
➡️ Okta
➡️ Ping Identity
➡️ OneLogin
➡️ Google Cloud Identity Platform
The only playbook you need for coding interviews.
DSA, system design, behavioral, offer negotiation
one resource...nothing else
drive.google.com/file/d/1-iHrpj…
🚨 You need to see this.
@addyosmani from Google just dropped his new Agent Skills and it's incredible.
It brings 19 engineering skills + 7 commands to AI coding agents, all inspired by Google best practices 🤯
AI coding agents are powerful, but left alone, they take shortcuts.
They skip specs, tests, and security reviews, optimizing for "done" over "correct." Addy built this to fix that.
Each skill encodes the workflows and quality gates that senior engineers actually use: spec before code, test before merge, measure before optimize.
The full lifecycle is covered:
→ Define - refine ideas, write specs before a single line of code
→ Plan - decompose into small, verifiable tasks
→ Build - incremental implementation, context engineering, clean API design
→ Verify - TDD, browser testing with DevTools, systematic debugging
→ Review - code quality, security hardening, performance optimization
→ Ship - git workflow, CI/CD, ADRs, pre-launch checklists
Features 7 slash commands: (/spec, /plan, /build, /test, /review, /code-simplify, /ship) that map to this lifecycle.
It works with:
✦ Claude Code
✦ Cursor
✦ Antigravity
✦ ... and any agent accepting Markdown. Baking in Google-tier engineering culture (Shift Left, Chesterton's Fence, Hyrum's Law) directly into your agent's step-by-step workflow!
`npx skills add addyosmani/agent-skills`
Free and open-source.
Repo link in 🧵↓
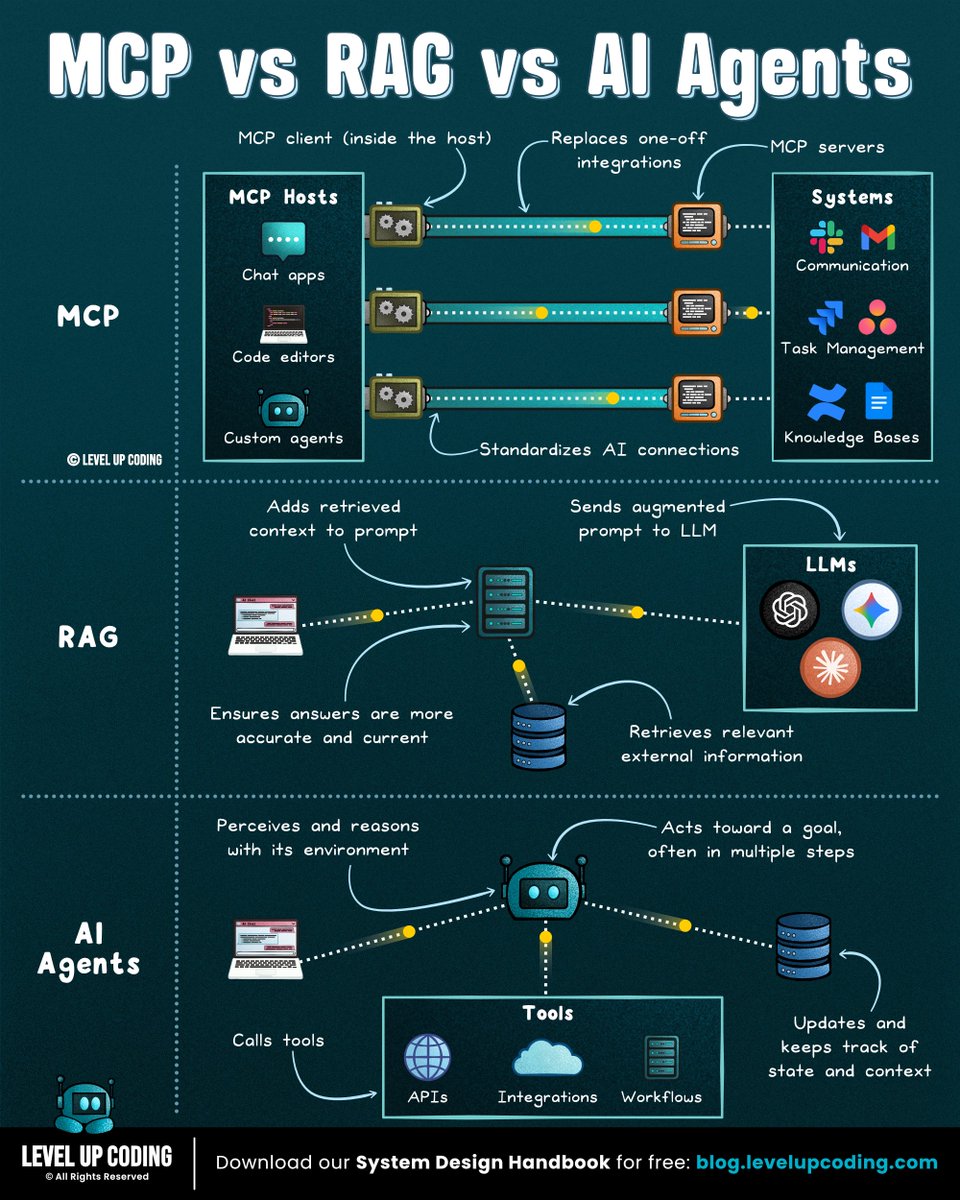
MCP vs RAG vs AI Agents
To understand modern AI systems, you need to understand how these three pieces fit together.
𝗥𝗔𝗚 = “𝗚𝗶𝘃𝗲 𝘁𝗵𝗲 𝗺𝗼𝗱𝗲𝗹 𝗯𝗲𝘁𝘁𝗲𝗿 𝗮𝗻𝘀𝘄𝗲𝗿𝘀”
RAG retrieves relevant data, injects it into the prompt, and generates a grounded response. It’s best when your problem is answering questions using your docs, reducing hallucinations, or showing sources and citations. RAG improves what the model knows, not what it can do.
If you’re building with these patterns, here's a great guide on scaling multi-agent RAG systems: lucode.co/multi-agent-ra…
𝗠𝗖𝗣 = “𝗦𝘁𝗮𝗻𝗱𝗮𝗿𝗱𝗶𝘇𝗲𝗱 𝘁𝗼𝗼𝗹 𝗮𝗻𝗱 𝗱𝗮𝘁𝗮 𝗮𝗰𝗰𝗲𝘀𝘀”
MCP is a standardized interface between LLMs and external systems like APIs, databases, and apps. Use it when your model needs to query data, call services, or interact with real systems (Slack, GitHub, etc). MCP doesn’t decide actions, it defines how tools are exposed.
𝗔𝗜 𝗔𝗴𝗲𝗻𝘁𝘀 = “𝗠𝗮𝗸𝗲 𝘁𝗵𝗲 𝗺𝗼𝗱𝗲𝗹 𝘁𝗮𝗸𝗲 𝗮𝗰𝘁𝗶𝗼𝗻”
Agents operate in a loop: observe → plan → act → repeat, often using tools and memory. Use them when your problem requires multi-step reasoning, tool usage with verification, or full task execution. Agents start where RAG stops, turning decisions into actions and outcomes.
The simple mental model:
RAG → knowledge layer
MCP → tool layer
Agents → execution layer
Not every system needs all three explicitly, but complex ones often combine them.
If you want to see what this looks like in practice, this guide walks you through building a scalable multi-agent RAG system.
Check it out: lucode.co/multi-agent-ra…
What else would you add?
♻️ Repost to help others learn AI.
🙏 Thanks to @Oracle for sponsoring this post.
BREAKING: MIT just mass released their Al library for free. (Links included)
I went through these and honestly... this is better than most paid courses I've seen.
Here's the full list of books:
Foundations
1. Foundations of Machine Learning Core algorithms explained. Theory meets practice.
2. Understanding Deep Learning Neural networks demystified. Visual explanations included.
3. Machine Learning Systems Production-ready architecture. System design principles.
Advanced Techniques
4. Algorithms for ML Computational thinking simplified. Decision-making frameworks.
5. Deep Learning The definitive textbook. Covers everything deeply.
Reinforcement Learning
6. RL Basics (Sutton & Barto) The classic. Agent training fundamentals.
7. Distributional RL Beyond expected rewards. Advanced theory.
8. Multi-Agent Systems Agents working together. Coordination and competition.
9. Long Game Al Strategic agent design. Future-focused thinking.
Ethics & Probability
10. Fairness in ML Bias detection. Responsible Al practices.
11. Probabilistic ML (Part 1 & 2)
Links: lnkd.in/gkuXuexa
Most people pay thousands for bootcamps that teach half of this.
Bookmark it. Start anywhere. Just start.
Repost for others Follow for more insights on Al Agents.
MIT's books on Al
Foundations
1. Foundations of Machine Learning - lnkd.in/gytjT5HC
2. Understanding Deep Learning - lnkd.in/dgcB68Qt
3. Machine Learning Systems - lnkd.in/dkiGZisg
Advanced Techniques
4. Algorithms for ML - algorithmsbook.com
5. Deep Learning - lnkd.in/g2efT6DK
Reinforcement Learning
6. RL Basics (Sutton & Barto) - lnkd.in/guxqxcZZ
7. Distributional RL - lnkd.in/d4eNP-pe
8. Multi-Agent Systems - marl-book.com
9. Long Game Al - lnkd.in/g-WtzvwX
Ethics & Probability
10. Fairness in ML - fairmlbook.org
11. Probabilistic ML (Part 1) - lnkd.in/g-isbdjj
12. Probabilistic ML (Part 2) - lnkd.in/gJE9fy4w
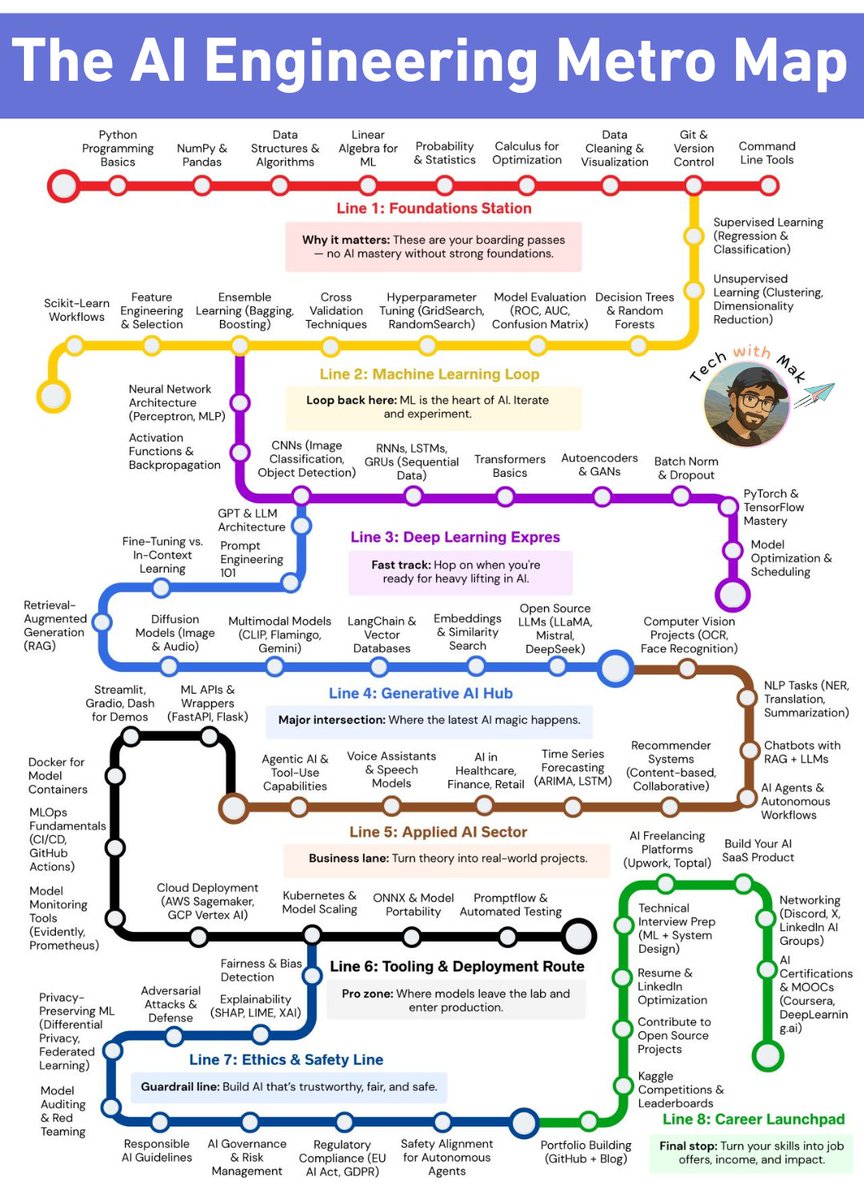
Most people try to learn AI randomly.
I mapped the entire AI engineering journey into a metro system.
The problem with most AI roadmaps:
They're linear. Step 1, Step 2, Step 3. As if everyone starts at the same place and wants the same destination.
But AI engineering isn't linear. It's a network.
→ A software engineer skips Python basics, jumps straight to LangChain
→ A data analyst already knows Pandas, needs Transformers next
→ A product manager wants RAG and Agentic AI, not CNNs
→ A researcher needs Ethics & Safety before deployment
A metro map captures this reality.
Generative AI Hub (Line 4) connects to:
→ Machine Learning Loop (you need Transformers first)
→ Applied AI Sector (where RAG becomes chatbots)
→ Tooling & Deployment (where demos become products)
Career Launchpad (Line 8) connects to:
→ Every other line (skills from any track convert to job offers)
Ethics & Safety (Line 7) connects to:
→ Deployment (you can't ship without guardrails)
→ Applied AI (real-world projects need fairness and privacy)
The 8 lines:
🟠 Foundations - Python, Math, Git (boarding passes)
🔵 Machine Learning - Neural Nets, CNNs, Transformers (the heart)
🟡 Deep Learning Express - LLMs, Fine-Tuning, PyTorch (fast track)
🟢 Generative AI Hub - RAG, Diffusion, LangChain (the magic)
🩷 Applied AI - Agentic AI, Healthcare, Chatbots (real projects)
🟣 Tooling & Deployment - Cloud, Kubernetes, MLOps (production)
🔴 Ethics & Safety - Bias, Privacy, Governance (guardrails)
🟢 Career Launchpad - Portfolio, Interviews, Networking (job offers)
You don't take every line. You don't visit every stop.
Find where you are. Pick your destination. Transfer as needed.
Bookmark this. Start today.
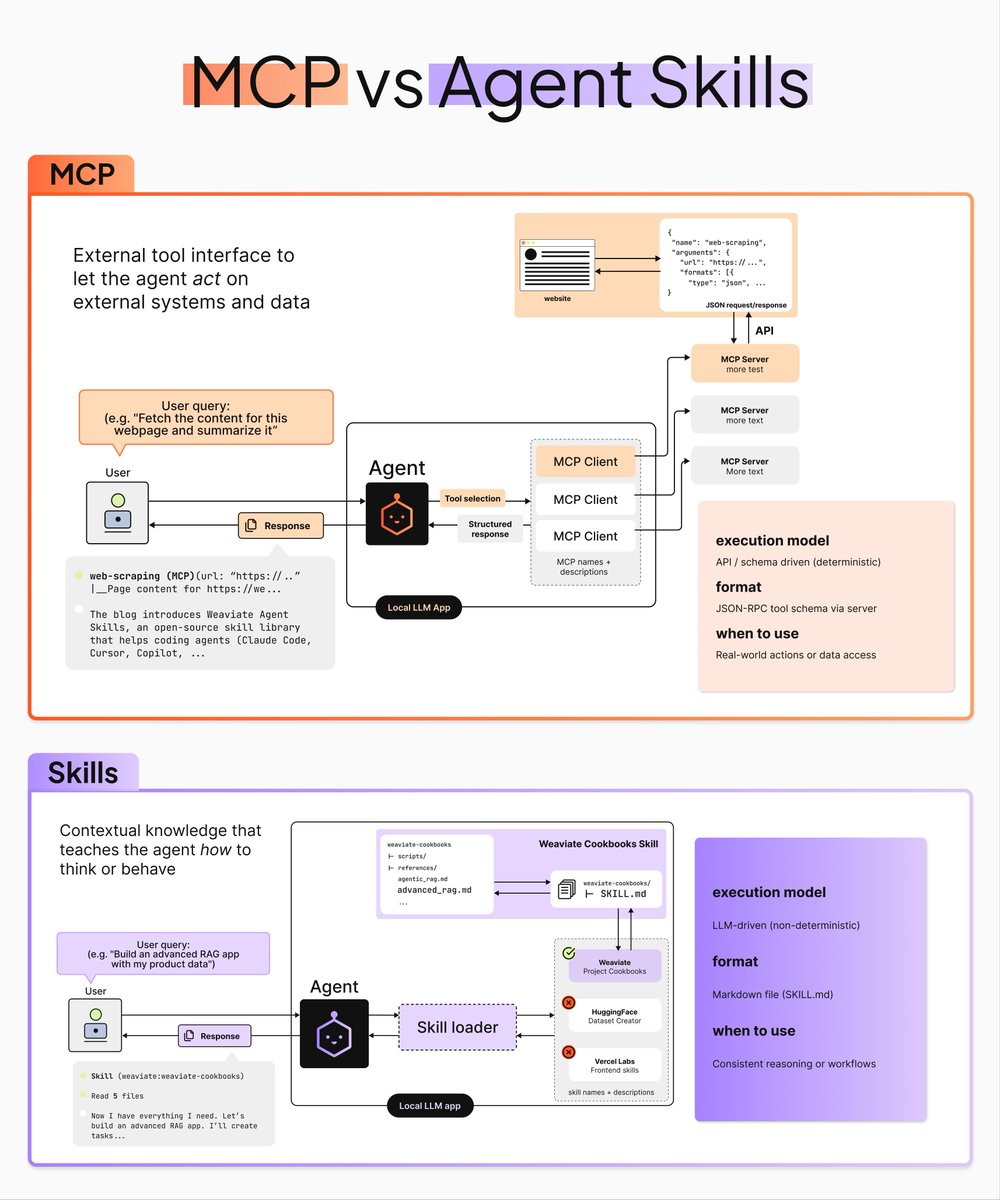
𝗠𝗖𝗣 or 𝗔𝗴𝗲𝗻𝘁 𝗦𝗸𝗶𝗹𝗹𝘀?
You're asking the wrong question.
Short answer: they're not alternatives - they're solving different problems in the same ecosystem.
If you're building with AI agents, you've probably heard about both the Model Context Protocol (MCP) and maybe also Agent Skills.
Let’s break down what each does:
𝗠𝗖𝗣:
The Model Context Protocol, introduced by Anthropic in late 2024, is a universal standard for connecting AI applications to external data sources and tools. It’s basically a standardized API gateway. Your agent makes a deterministic API call with fixed input/output schemas and receives a deterministic response: clean and predictable.
𝗦𝗸𝗶𝗹𝗹𝘀:
These are something else. When an agent uses a skill, it's interpreting natural language instructions about 𝘩𝘰𝘸 to accomplish something. The agent decides which skill to use, when, 𝘢𝘯𝘥 𝘩𝘰𝘸 to execute it. Less "call this function" and more "here's how to think about this problem.”
𝗪𝗵𝗲𝗻 𝘁𝗼 𝘂𝘀𝗲 𝗲𝗮𝗰𝗵 / 𝗛𝗼𝘄 𝘁𝗵𝗲𝘆 𝘄𝗼𝗿𝗸 𝘁𝗼𝗴𝗲𝘁𝗵𝗲𝗿
Agent Skills leverages the standardization that MCP enables. So they 𝗯𝗼𝘁𝗵 have a place in agentic coding. Skills are great for behavioral guidance, MCP works better for the direct infrastructure calls.
Use 𝗠𝗖𝗣 when you're:
• Building broad integrations across multiple tools and data sources
• Creating custom MCP servers for your own systems
• Working with any MCP-compatible AI application
Use 𝗔𝗴𝗲𝗻𝘁 𝗦𝗸𝗶𝗹𝗹𝘀 when you're:
• Building specifically with specialized Weaviate tools/infrastructure
• Using coding agents like Cursor or Claude Code
• Need reliable, production-ready Weaviate implementations without debugging hallucinations
We just released our Agent Skills repository for Weaviate, serving as a bridge between your coding agent and Weaviate's infrastructure. The repository contains both granular Weaviate-specific scripts (schema inspection, data ingestion, precision search) and full end-to-end project blueprints (RAG pipelines, Query Agent chatbots, multivector PDF retrieval).
The best part is that you can get started with just one line of code in your terminal:
npx skills add weaviate/agent-skills
Learn all about Agent Skills in this release blog post: weaviate.io/blog/weaviate-…
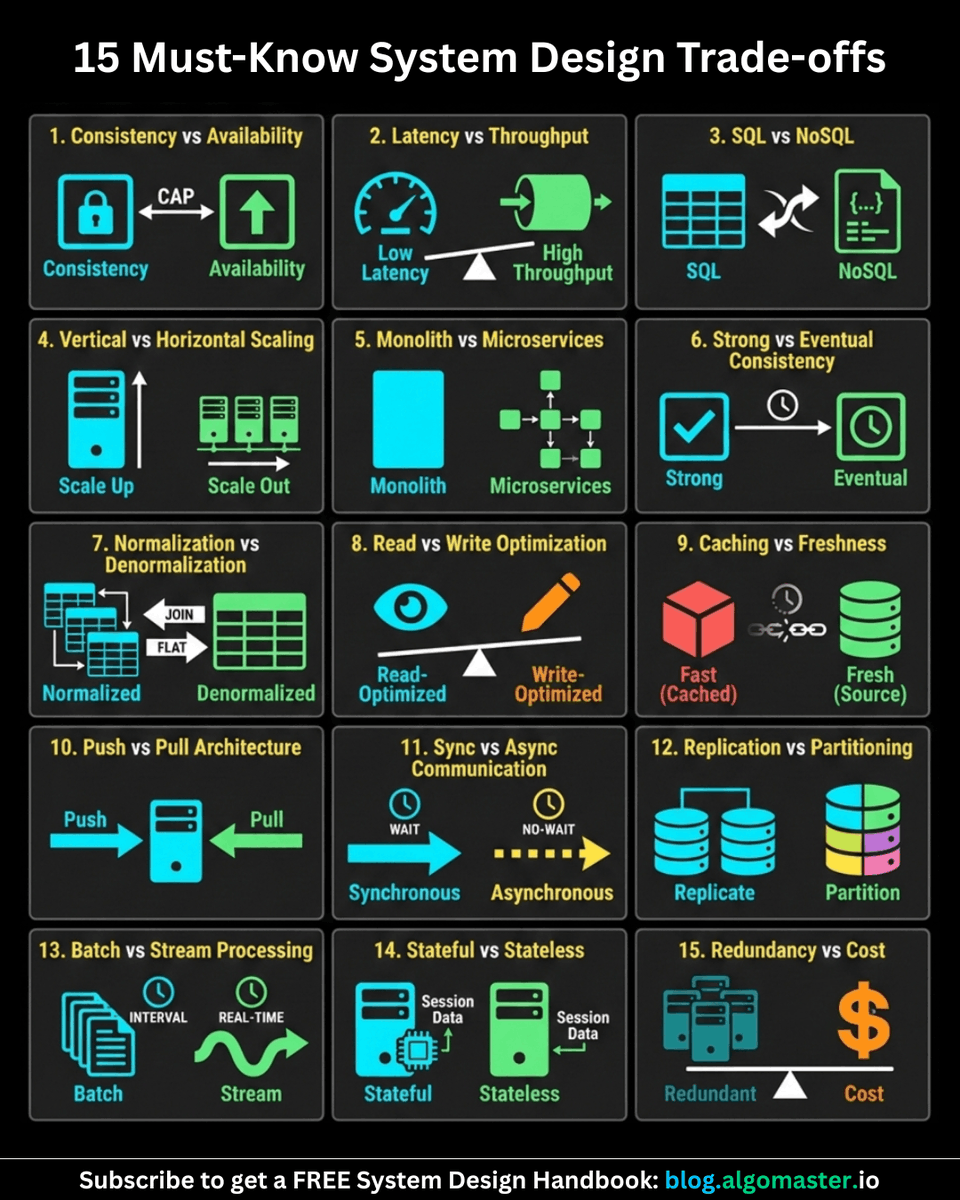
15 Must-Know System Design Trade-offs:
1. Consistency vs Availability (CAP)
2. Latency vs Throughput
3. SQL vs NoSQL
4. Vertical vs Horizontal Scaling
5. Monolith vs Microservices
6. Strong vs Eventual Consistency
7. Normalization vs Denormalization
8. Read vs Write Optimization
9. Caching vs Freshness
10. Push vs Pull Architecture
11. Sync vs Async Communication
12. Replication vs Partitioning
13. Batch vs Stream Processing
14. Stateful vs Stateless
15. Redundancy vs Cost
♻️ Repost to help others in your network
𝗪𝗵𝘆 𝗡𝗲𝘁𝗳𝗹𝗶𝘅 𝗱𝗲𝗰𝗶𝗱𝗲𝗱 𝘁𝗼 𝗮𝗯𝗮𝗻𝗱𝗼𝗻 𝘁𝗵𝗲 𝗖𝗤𝗥𝗦 𝗮𝗽𝗽𝗿𝗼𝗮𝗰𝗵
Netflix launched 𝗧𝘂𝗱𝘂𝗺 in late 2021 as its official fan website, a destination for exclusive interviews, behind-the-scenes content, and show-related material.
The team built it using CQRS to optimize read performance for serving content to fans.
The write path utilized a third-party CMS with a dedicated ingestion service that handled content updates via webhooks.
This service transformed CMS data into a read-optimized format and published it to Kafka.
But their CQRS implementation couldn't deliver the read-after-write consistency their editorial workflow required.
Tudum launched with standard CQRS separation:
🔹 Write path: third-party CMS with webhook-driven ingestion service.
🔸 Read path: Kafka → Cassandra → Page Data Service with near cache → Page Construction Service.
The ingestion pipeline transformed CMS data into read-optimized format (CDN URLs instead of asset IDs, hydrated movie metadata instead of placeholders). Kafka decoupled writes from reads, and Cassandra provided the query store.
But they have 𝗮 𝗰𝗼𝗻𝘀𝗶𝘀𝘁𝗲𝗻𝗰𝘆 𝗽𝗿𝗼𝗯𝗹𝗲𝗺. Editorial previews required strong read-after-write consistency, but the architecture delivered eventual consistency with significant delays:
1. CMS webhook triggers the ingestion service
2. Ingestion service queries CMS APIs, validates, transforms, and produces to Kafka
3. Data Service Consumer processes Kafka message, writes to Cassandra
4. Near cache refreshes on 60-second cycle
With N keys and 60-second refresh intervals, the cache is updated one key per second. Growing content made this issue worse, and preview delays stretched to over 30 seconds.
So, Netflix replaced Kafka, Cassandra, and a cache layer with 𝗥𝗔𝗪 𝗛𝗼𝗹𝗹𝗼𝘄, their in-memory object database.
Key characteristics:
✅ Entire dataset distributed across application cluster memory
✅ Compression reduces the memory footprint to 25% of the uncompressed size
✅ Eventual consistency by default, strong consistency per-request option
✅ O(1) synchronous data access, no I/O per request
This enabled them to 𝗮𝗰𝗵𝗶𝗲𝘃𝗲 𝘀𝗶𝗴𝗻𝘁𝗶𝗳𝗶𝗰𝗮𝗻𝘁 𝗽𝗲𝗿𝗳𝗼𝗿𝗺𝗮𝗻𝗰𝗲 𝗶𝗺𝗽𝗿𝗼𝘃𝗲𝗺𝗲𝗻𝘁𝘀, such as reducing editorial previews from minutes to seconds and page construction from 1.4 seconds to 0.4 seconds.
CQRS optimizes for scale and separation of concerns. However, when your dataset fits in memory, and you require strong consistency, simpler approaches often prove more effective.
The "right" pattern depends on your specific constraints. Netflix optimized for editorial workflow, rather than theoretical scalability limits they hadn't yet reached.
Architecture decisions should align with actual requirements, not anticipated ones.
Image: Netflix
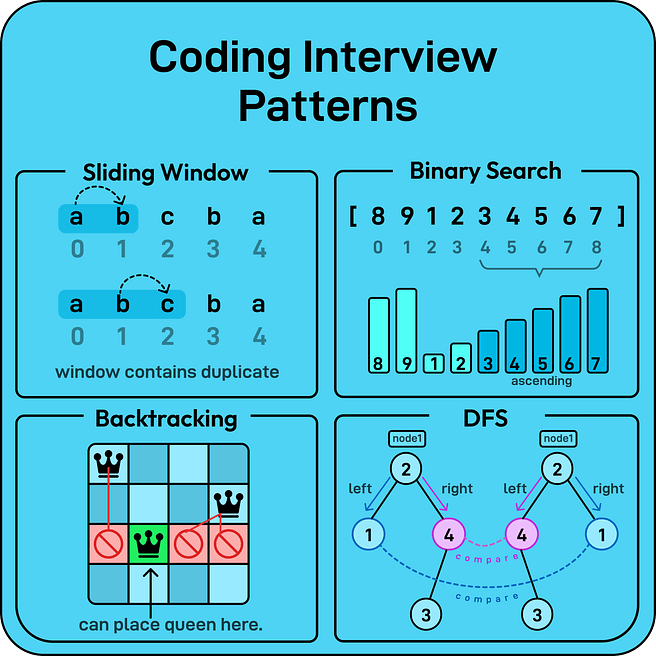
There is a reason why Algorithms and Data Structures are hard for many software engineers.
It's not because they're not capable, but they simply miss a lot of pre-requisite knowledge.
If you want to learn dsa from first principles, read these 16 articles (links below):