z retweetledi

z
3.3K posts





Codex grew programmatic policies with no neural nets: max score on Breakout, and SOTA-level scores on MuJoCo. Maybe heuristics were not too weak. Maybe they were just too expensive to maintain. Maybe it's the next paradigm. trinkle23897.github.io/learning-beyon…




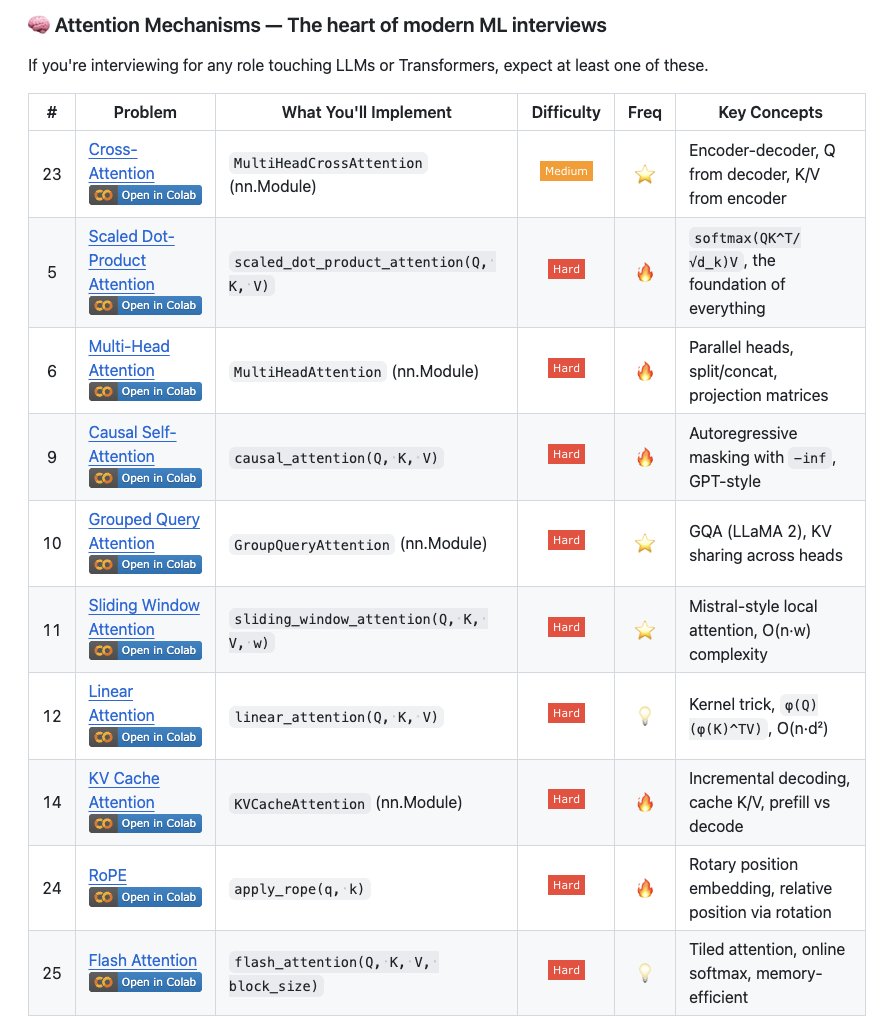
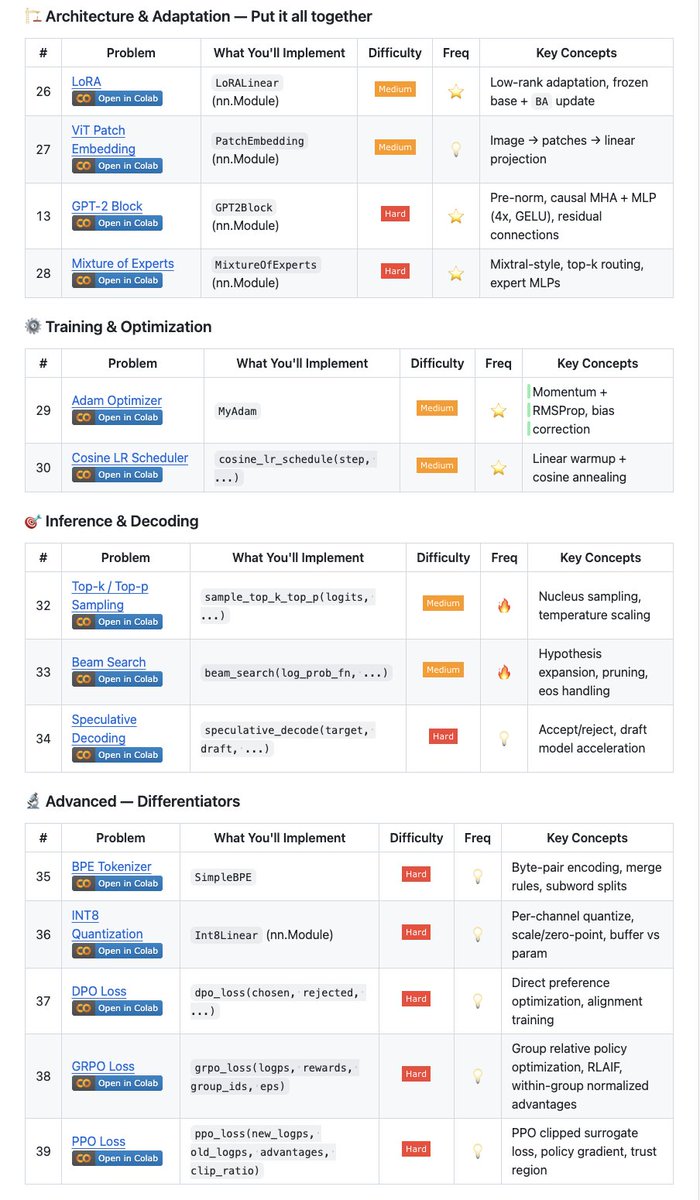

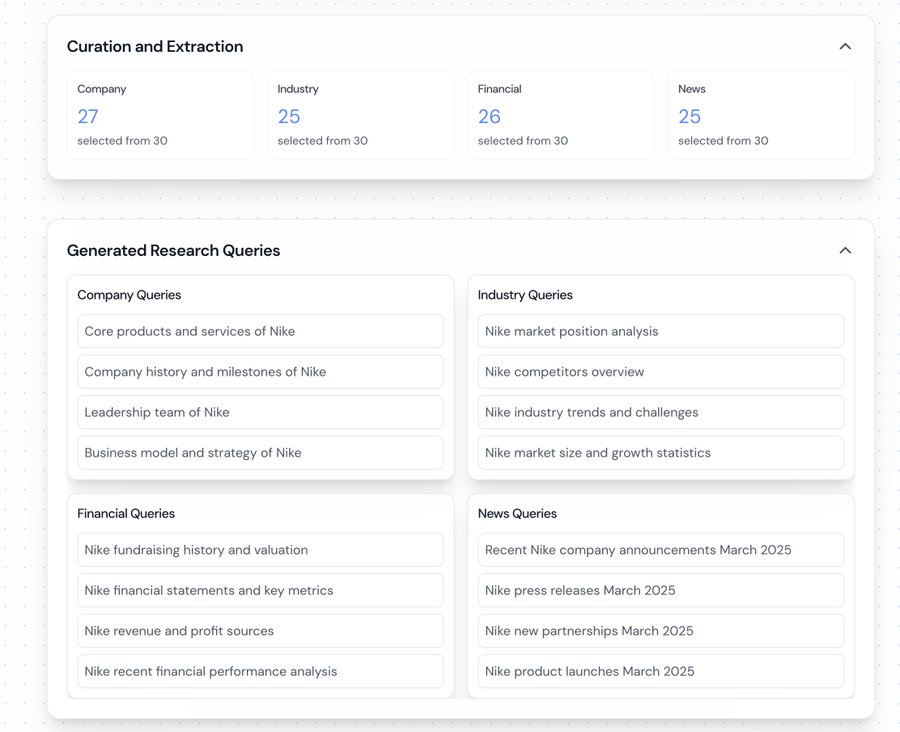



📣 What if every open issue had a Codex agent? That’s the idea behind Symphony, an open-source agent orchestrator for Codex that turns task trackers into always-on systems for agentic work, letting humans focus on review and direction.




