
📚 Explore Now!
🌐 Dataset: huggingface.co/datasets/amphi…
📄 Paper: arxiv.org/abs/2501.15907
English
Amphion
59 posts

@realamphion
Amphion is a toolkit for Audio, Music, and Speech Generation. GitHub: https://t.co/SDsdCO4M29 HF: https://t.co/3VJSoumiFS
🚀Introducing Emilia-Large: 200K+ Hours of Open-Source Speech Data! We’re excited to release Emilia-Large, the largest TTS pretraining datasets! With 200K+ hours of multilingual speech data, fully open-source. It is ready to use for #TTS and #SpeechLM.


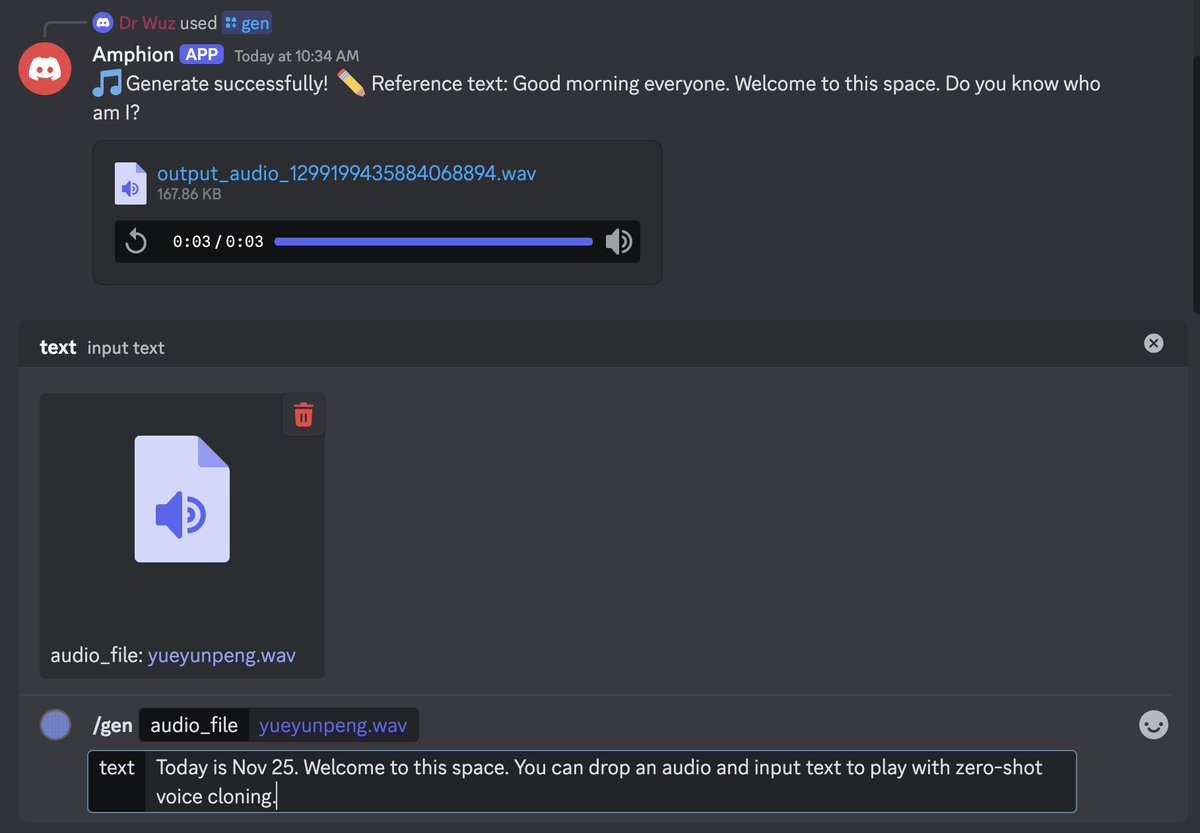
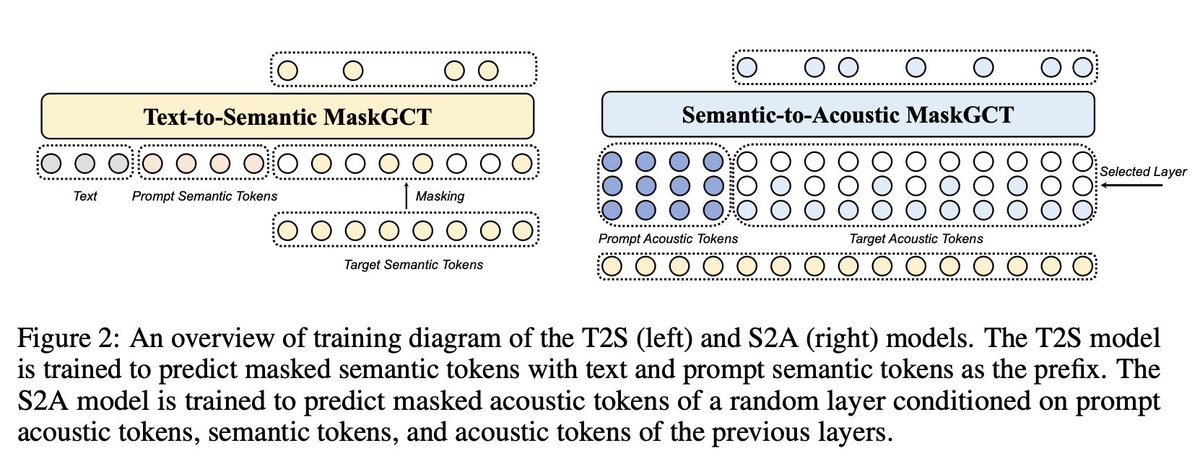

Fuck yeah! MaskGCT - New open SoTA Text to Speech model! 🔥 > Zero-shot voice cloning > Emotional TTS > Trained on 100K hours of data > Long form synthesis > Variable speed synthesis > Bilingual - Chinese & English > Available on Hugging Face Fully non-autoregressive architecture: > Stage 1: Predicts semantic tokens from text, using tokens extracted from a speech self-supervised learning (SSL) model > Stage 2: Predicts acoustic tokens conditioned on the semantic tokens. Synthesised: "Would you guys personally like to have a fake fireplace, an electric one, in your house? Or would you rather have a real fireplace? Let me know down below. Okay everybody, that's all for today's video and I hope you guys learned a bunch of furniture vocabulary!" TTS scene keeps getting lit! 🐐

Fuck yeah! MaskGCT - New open SoTA Text to Speech model! 🔥 > Zero-shot voice cloning > Emotional TTS > Trained on 100K hours of data > Long form synthesis > Variable speed synthesis > Bilingual - Chinese & English > Available on Hugging Face Fully non-autoregressive architecture: > Stage 1: Predicts semantic tokens from text, using tokens extracted from a speech self-supervised learning (SSL) model > Stage 2: Predicts acoustic tokens conditioned on the semantic tokens. Synthesised: "Would you guys personally like to have a fake fireplace, an electric one, in your house? Or would you rather have a real fireplace? Let me know down below. Okay everybody, that's all for today's video and I hope you guys learned a bunch of furniture vocabulary!" TTS scene keeps getting lit! 🐐








