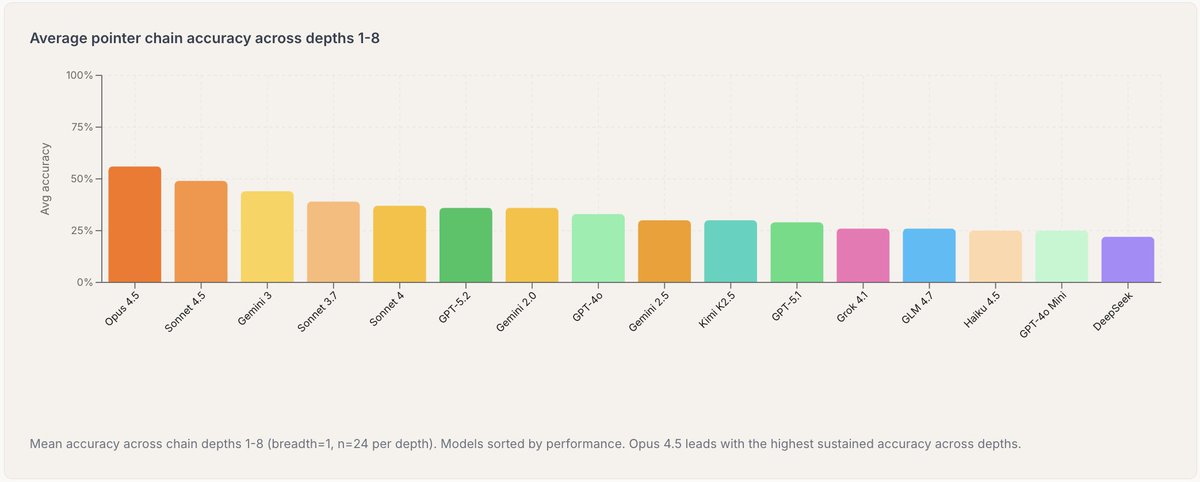
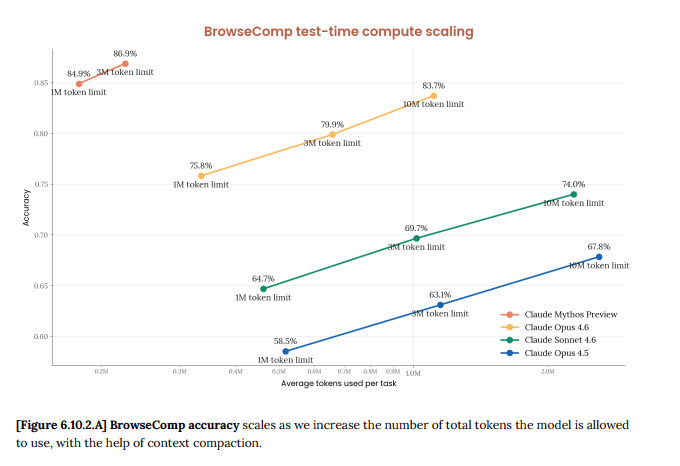
Sabitlenmiş Tweet

“AI will mass replace jobs” - if so, I've built a tool to find where you should already see it
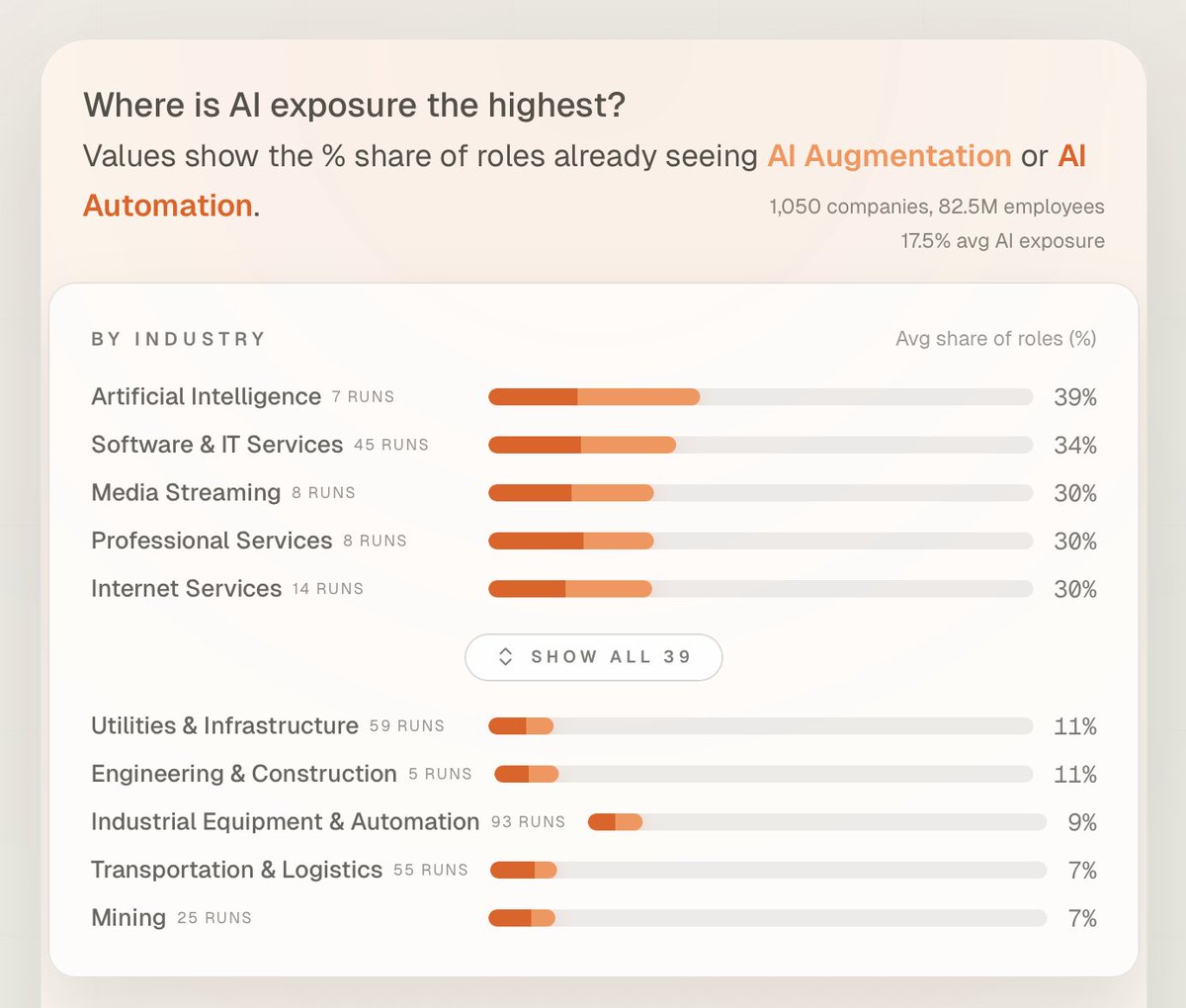
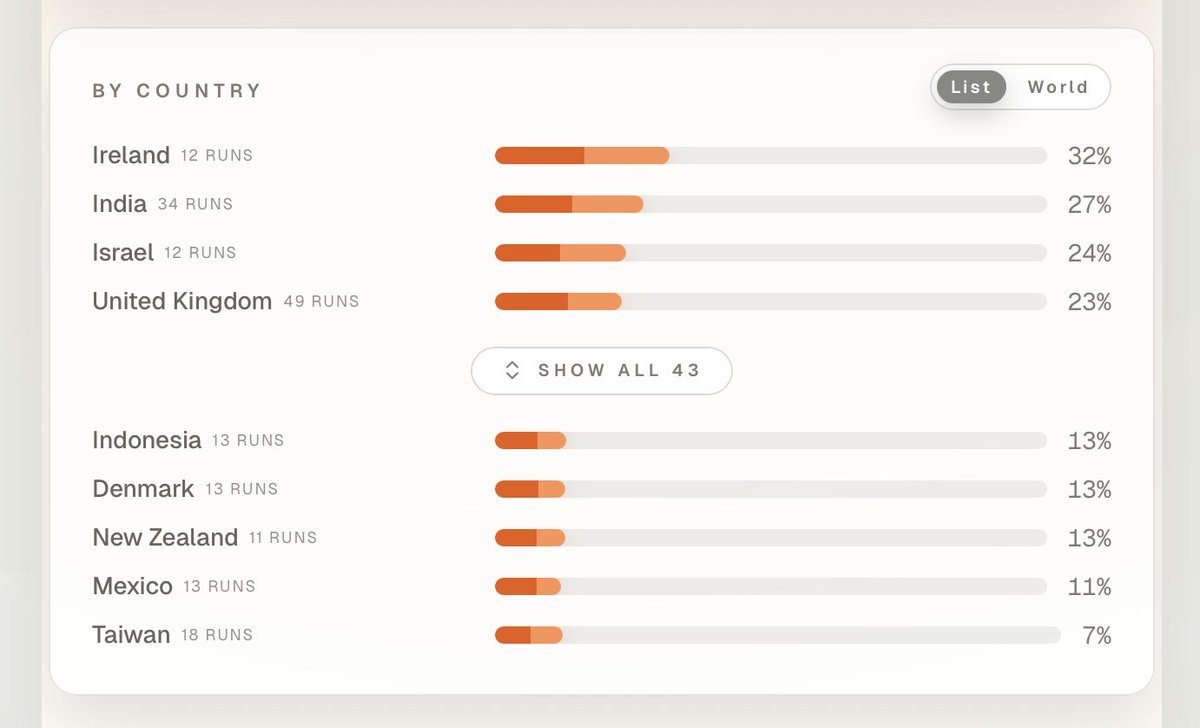
👉 Automation Risk Explorer: feed it a company → it infers an org, maps roles to O*NET, overlays Anthropic’s task‑usage data, and rolls up exposure across the workforce, industry, and country.
automationrisk.app

English