Sabitlenmiş Tweet

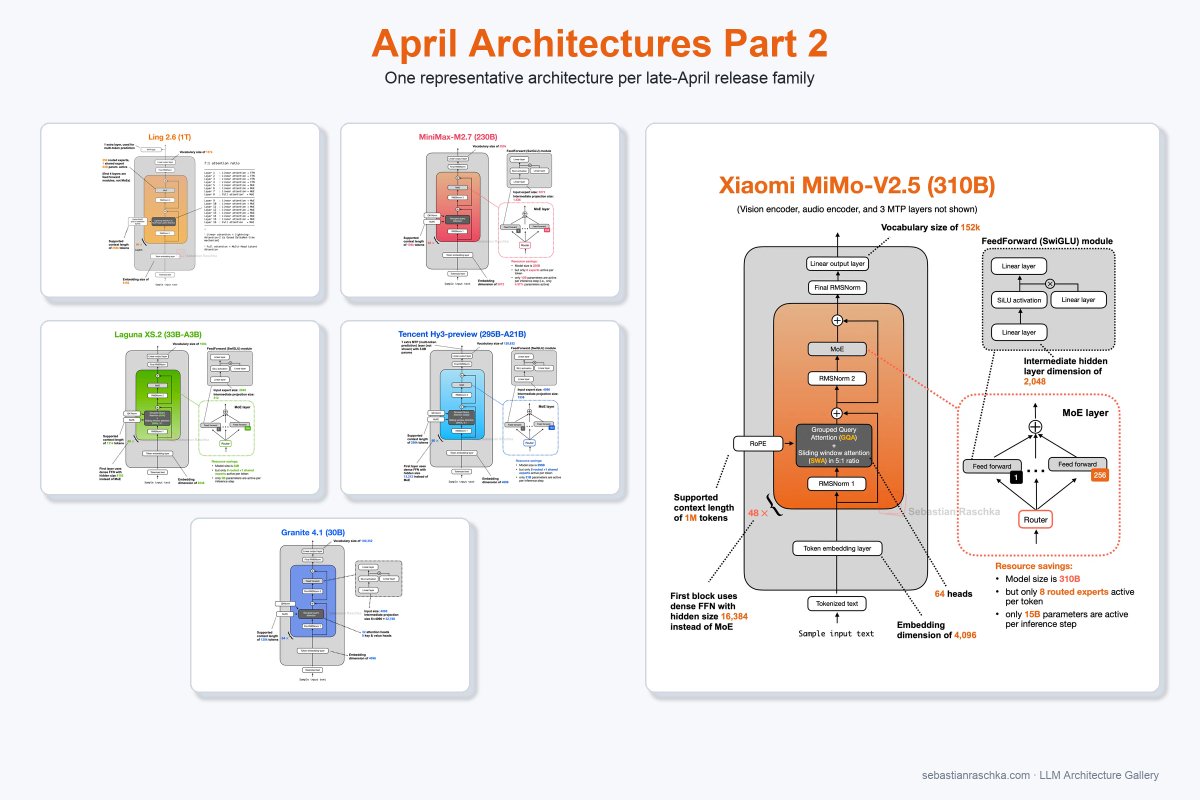
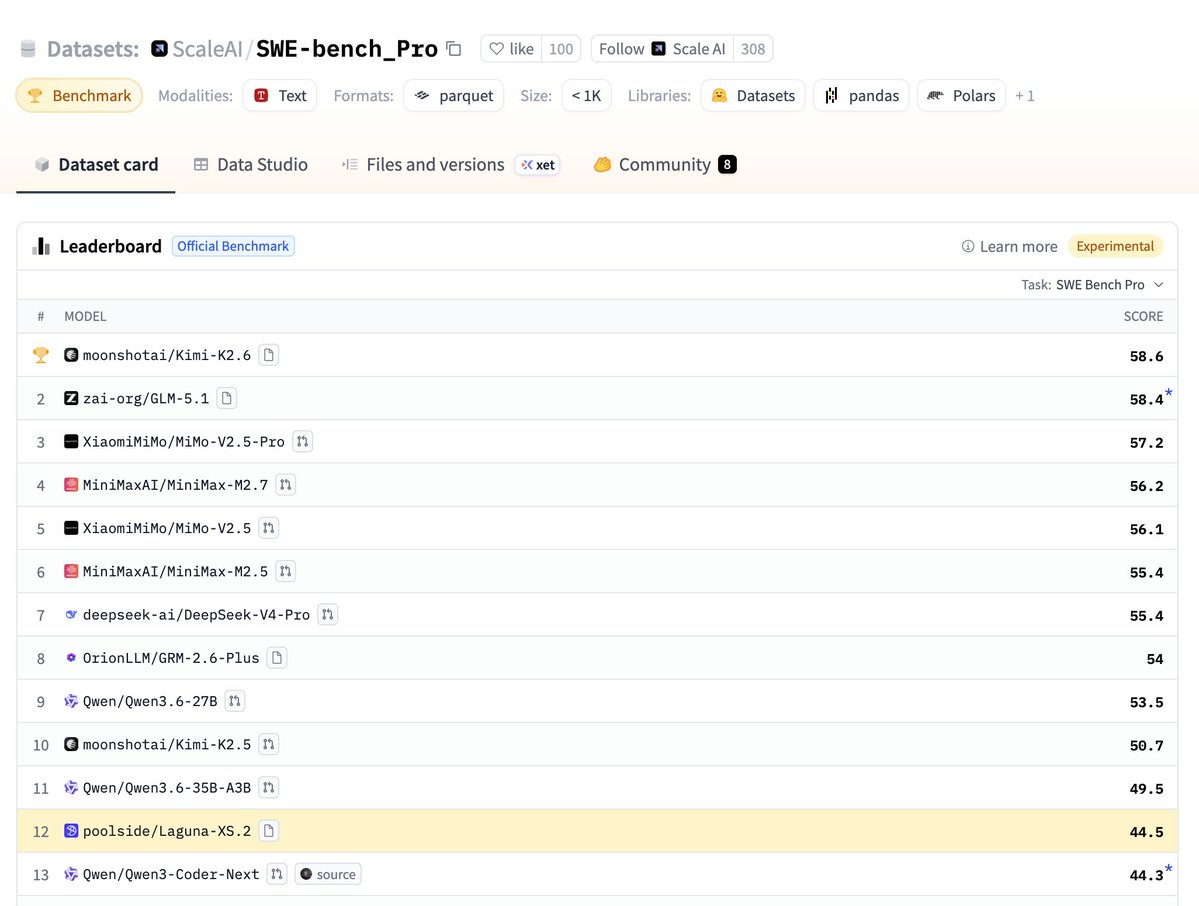
Super excited to release the weights of Laguna XS.2 under Apache 2.0 to the community today. We are also opening access to our most capable model, Laguna M.1, via our API.
Both models are designed for long-horizon agentic coding with strong performance on SWE-bench-style tasks. Learn more on our blog.
poolside@poolsideai
Today we’re releasing Laguna XS.2, Poolside’s first open-weight model. It’s a 33B total / 3B active MoE model built for agentic coding and long-horizon tasks. Trained fully in-house on our own stack. Runs on a single GPU. Released under Apache 2.0. Links 👇 Weights: huggingface.co/poolside/Lagun… API: platform.poolside.ai Blog: poolside.ai/blog/laguna-a-…
English