
Robert Hoffmann
678 posts

Robert Hoffmann
@robhoffmax
Solutions Architect @awscloud - ex @DeutscheTelekom, @Samsung - I move boxes around to help people move boxes around.
Katılım Kasım 2011
527 Takip Edilen212 Takipçiler

setup mobile vibe coding now
it's a game changer that nearly no one is taking advantage of
English

I work at @base44 , so I see many prompts every day.
Most of them are okay. Some are good. But about 1% are genius.
I spent the last week analyzing that top 1%.
The results were honestly shocking. 🤯
Most users prompt like they are talking to a human:
"Make a cool, modern website for a tech company." (Results: Generic, boring, hallucinations).
If you want to learn how to prompt and vibe code like a pro
Drop a comment below, and I'll send the guide to your inbox. 📥
English
Robert Hoffmann retweetledi

FINALLY CAN TALK ABOUT THIS
this has been a major hole in the AWS stack and it is actually really really good
this is going to blow up the postgres space a bunch
AJ Stuyvenberg@astuyve
AWS just announced Aurora DSQL - a purpose built, postgres-compatible serverless database and take it from me - it's amazing. I've had a few months to play with it (more soon), but it's truly the single most exciting launch I've seen from AWS in a while. You've gotta try it
English
Robert Hoffmann retweetledi

Despite concerns that AWS would be overly genAI focused for re:Invent, this has been one of the strongest re:Invents in years for announcements I'm interested in.
English
Robert Hoffmann retweetledi

Woohoo! 🦭All content from Conf42 Kube Native 2023 is now available to watch without RSVP!
👀👉Watch all talks without limits here: youtube.com/watch?v=O-k-ch…
🎉We've got many amazing speakers in the lineup🎉
#conf42 #online #conference #kubenative
@TheCorgiDev

YouTube

English
Robert Hoffmann retweetledi
🌟 Ready to transition from a Kubernetes YAML engineer to a full-fledged software engineer with CDK8s?🚀Join @robhoffmax at #Conf42 #KubeNative!
🌐conf42.com/Kube_Native_20…
#CDK8s #Kubernetes #InfrastructureAsCode #TechTalks #applications #programming #programminglanguage

English
Robert Hoffmann retweetledi

Originally I thought the @awscloud CDK was a cult.
Then I used it for a project.
Now I'm a cultist; wanna come to a meeting with me?
English
Robert Hoffmann retweetledi

I keep seeing people get confused on DynamoDB having 10GB partitions and thinking they need to design around it. This happened twice in the last week!
Writing a long tweet to clarify.
Two main takeaways:
1. The '10GB partition size' is rarely visible to you as a user.
2. You are not limited to 10GB of data for a given partition key (**if you don't have an LSI on your table**).
Explanation:
First, some vocab:
The term 'partition' refers to a co-located subset of your data within a DynamoDB table. Partitions are ~10GB in size but can be larger or smaller. DynamoDB is a multi-tenant system with a huge fleet of storage nodes, and each storage node contains many partitions from many different tables.
The term 'item collection' is used to refer to the set of records that share the same partition key in your table. Within the item collection, items are sorted according to the sort key.
-----
DynamoDB assigns an item to a partition using the partition key (and, occasionally, the sort key).
In most cases, a single partition will contain multiple item collections. Also, a single item collection will often be contained on the same partition. But this is not always the case!
If your item collection exceeds 10GB, DynamoDB will split it across multiple partitions.
If you are driving heavy traffic to your item collection and DynamoDB thinks it could serve it better across multiple partitions, it might split it across multiple partitions.
But there's not necessarily a 1:1 mapping from partitions to item collections nor from item collections to partitions.
However, if your table has a local secondary index (LSI), the rules change. Now, your item collection *must* fit within a single partition. This means the item collection + any LSI replicas of it must be under 10GB.
This is the only time the 10GB limit applies. This is pretty rare -- I recommend against LSIs in almost all scenarios, partly because of this limitation.
But if you don't have an LSI, you don't need to worry about keeping your item collections under 10GB (for capacity reasons -- there may be query-based reasons to keep it smaller)!
✨ The more you know
English
Robert Hoffmann retweetledi
A very nice pre-July-4th launch from the DynamoDB team. 🙌
You can now have DynamoDB return your item when a write fails due to conditions in the write request.
Super helpful, particularly when you have multiple conditions and/or you want to return meaningful information to the caller on *why* the write failed.
Previously, you'd have to do a follow-up read request, which results in a higher cost and could result in a different version of the item than the one you were writing against!
aws.amazon.com/about-aws/what…
English
Robert Hoffmann retweetledi

𝗦𝗼𝗳𝘁𝘄𝗮𝗿𝗲 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿 != 𝗗𝗲𝘃𝗲𝗹𝗼𝗽𝗲𝗿
Software Engineer == Problem Solver
Don't attack problems with code. Try first to understand them from a business perspective and then a technical perspective. When you do this, make a plan for how to solve it.
Try to solve without coding. The best code is not code.
If you must code, then do it.
Remember, 𝗰𝗼𝗱𝗲 𝗶𝘀 𝗮 𝗹𝗶𝗮𝗯𝗶𝗹𝗶𝘁𝘆, 𝗻𝗼𝘁 𝗮𝗻 𝗮𝘀𝘀𝗲𝘁.
#technology #softwareengineering #programming #developers #coding
English
Robert Hoffmann retweetledi

You didn't have the chance to join @robhoffmax's & @alex0ptr's talk at #CloudLand2023 last week?
👀 Check out their slides on bit.ly/44axD79
🎦 If you'd like to watch the recording, get your On-Demand ticket from @Cloudlandorg
QAware GmbH@qaware
🚀 Make #Developers Fly: Principles for #PlatformEngineering 📆 22.6. | 🕐 11h | 📍 #CloudLand2023 @robhoffmax & @alex0ptr will talk about how #platform engineering evolved from the #DevOps movement & discuss principles & best practices 👉 bit.ly/3ByVPn6 @Cloudlandorg
English
Robert Hoffmann retweetledi

The Amazon Builders' Library is an hidden gem: it consists of articles written by some of the most senior AWS engineers covering foundational patterns and principles used when building AWS services.
Most learnings can be applied anywhere. Here are my favourite articles:
English
Robert Hoffmann retweetledi

It is hard to grasp for some engineers early in their careers what took them here won't take them there. Shipping features will probably can take you to senior, shipping 10x more features is not how you'll become a principal.
English
Robert Hoffmann retweetledi

My team's 37th launch! SNS now supports X-Ray active tracing for FIFO. You can view traces that flow from FIFO topics to FIFO queues, and traverse your app topology in CloudWatch ServiceLens. You can view faults, errors & latency for each FIFO subscriber🚀
aws.amazon.com/about-aws/what…
English
Robert Hoffmann retweetledi
🚀 Make #Developers Fly: Principles for #PlatformEngineering
📆 22.6. | 🕐 11h | 📍 #CloudLand2023
@robhoffmax & @alex0ptr will talk about how #platform engineering evolved from the #DevOps movement & discuss principles & best practices 👉 bit.ly/3ByVPn6
@Cloudlandorg

English
Robert Hoffmann retweetledi

An excellent article from @clare_liguori.
Dive into the CI/CD architecture we use at Amazon.
Many good lessons to learn about git branch management and staged deployments to multiple Regions.
A good read for the upcoming week-end!
#Trunk-based_development" target="_blank" rel="nofollow noopener">aws.amazon.com/builders-libra…
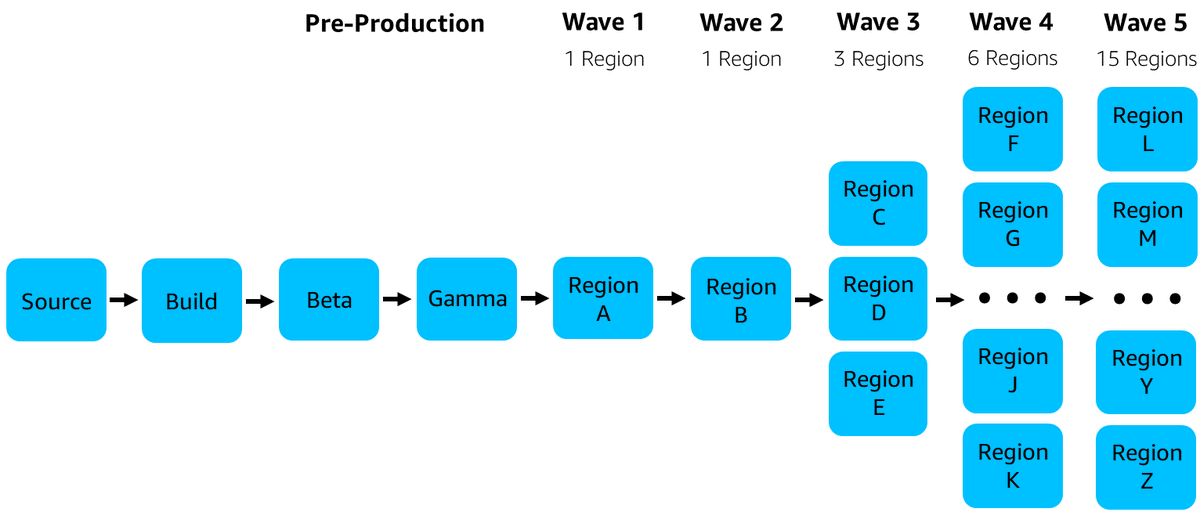
English
Robert Hoffmann retweetledi

The future of Kafka is unlimited storage.
Kafka engineers are building a solution to allow you to store unlimited amounts of data on a Kafka cluster.
How are they doing it?
KIP-405 - Tiered Storage. ✨
If you’re using Kafka to its full extent, you’re storing (or want to store) a lot of historical data in it.
But. Storage can be a bottleneck. A key limitation in Kafka’s design is that it couples its storage with compute.
This can be a large burden for 8 reasons:
🔴 1. slow broker failure recovery - has to catch up a lot of data, proportional to the time it was dead.
🔴 2. disastrous broker disk failure scenarios - in such cases, the broker has to fetch everything (TBs) and can severely impact latencies. Such broker recovery scenarios can be 12,000% slower and can worsen produce latencies by up to 900%, as shown by tests below.
🔴 3. competition for disk IOs - historical consumers can decrease write performance by up to 43% (as shown in tests below) because they cause extra disk strain by having to read from it.
🔴 4. no elasticity - reassigning partitions that have a lot of data are slow to move. At a decent 100MB/s replication rate, 10TB of data moves at a whopping 27.7 hours! That’s more than one day!
🔴 5. high cost - in the cloud, it’s more expensive to provision disk volumes that are attached to the instance.
🔴 6. max storage limitation per partition - you’re limited by how much data you can store on a single partition based on the limit of physical disk sizes.
🔴 7. burdensome to scale storage - if you decide to increase your retention settings across the cluster, you either need to add new brokers (scale horizontally) or do some complex disk swaps on them (scale vertically).
🔴 8. cluster sizing - number of brokers / machine types are impacted by disk requirements, potentially ending up with a significantly larger cluster than you would need if disk size wasn’t a concern.
How do we solve all of this? 😥
Simple. Put the data in S3 ✨
That is what Tiered Storage is - it extends Kafka’s storage beyond the local one by retaining the data in a pluggable external store (HDFS, S3, etc).
Pluggable is a key word here, as it will enable the open-source community to develop different implementations for different external stores in parallel.
Kafka will end up having two tiers of storage placement - a local one (hot) and a remote one (cold).
You will be able to enable this uniquely per topic, with varying local and remote retention settings.
This will be done transparently to any clients - they won't be able to tell when they’re fetching from the remote store as the Kafka API remains the same and abstracts it away.
😡 Won’t this kill latency?
One should in theory expect slower reads from the remote log store.
Thankfully,
1. This isn’t a problem practically as historical workloads are usually not performance sensitive.
2. The latency-sensitive workloads usually read from the tail of the log (latest data), and are therefore not impacted by this feature.
🤓 Give me the numbers.
Performance tests were done with HDFS as the external system.
They focused on write latency and the impacts there.
The largest produce latency increase in the tests was 21ms → 25ms of p99 produce latency in the steady state. (19% worse)
With different scenarios came different results.
Get this - when there are historical reads (out-of-sync consumers), the produce latency was actually improved!
This is because, without tiered storage, consumers reading old data compete for IOs on the disk for reading (normal consumers don’t - data is served from the page cache).
This reduces the IOs that writes can get and write disk latency increases.
The tests showed 42ms of p99 produce with tiered and 60ms of p99 produce WITHOUT tiered storage in this scenario. (43% increase) 😋
It gets better!
When rebuilding a broker with an empty disk, for just 12TB of data, recovery took almost 4 hours in their test without tiered storage, and only 2 minutes with tiered storage (a 120x improvement).
During this broker recovery, the p99 produce latency was 490ms WITHOUT tiered and 56ms with tiered - a 9x improvement! 🥳
Overall a very promising feature. 🔥
So when is it coming?
Tiered storage is incredibly complex, and has been in development for a while. It juuust missed the 3.5 release and is currently slated for Early Access in 3.6.
So around Q3 2023? 🤞
There are two notable limitations that Kafka will have with this first version:
🔴 - no compaction - compacted topics will not be supported
🔴 - no going back - once you enable it for a topic, disabling it back is not supported.
Future versions will surely address these limitations.
GIF
English
Robert Hoffmann retweetledi

React: The Most Common Mistakes in 2023
I'm presenting this talk at @kc_dc in July!
The list:
State:
Needless state
Global state overuse
Syncing state via useEffect
Reading state after setting it
Multiple setState calls in a row
Putting state in the wrong spot
Storing related data in separate pieces of state
Http:
Not caching
Fetching in useEffect
Not using modern libraries
Workflow:
Not using a framework
Not using Tailwind
Not using TypeScript
Not mocking
Ineffective testing
Not using custom dev tools
Poor folder structure
Few/poor reusable components
Weak ESLint rules
Weak error handling
What else would you put on this list?
English
Call me a nerd but these designs are siiick
Lorenzo Green 〰️@mrgreen
Harry Potter x Adidas just dropped! 🪄👟 AI-generated. (by "jmnuergogallery" on telegram) 1. Harry Potter:
English
Robert Hoffmann retweetledi

Harry Potter x Adidas just dropped! 🪄👟
AI-generated.
(by "jmnuergogallery" on telegram)
1. Harry Potter:

English