
ROXAS
187 posts
ROXAS retweetledi

Introducing DINOv3: a state-of-the-art computer vision model trained with self-supervised learning (SSL) that produces powerful, high-resolution image features. For the first time, a single frozen vision backbone outperforms specialized solutions on multiple long-standing dense prediction tasks.
Learn more about DINOv3 here: ai.meta.com/blog/dinov3-se…
English

I have 13 Sora 2 Invite Codes: okay let’s be fair
Raffle instructions below
Follow and comment below and I’ll randomise who gets one in your DM :)
#Sora2 #invitecode

English


I just got access to Sora 2 and have some invite codes. Like and reply this post. I’ll be sharing the codes in the comments.
English

I have 100 Sora invite codes. Like, comment, and repost this post. Follow @Vince2000_ and @Martini373469 I will randomly select 100 from the comments.

English
ROXAS retweetledi

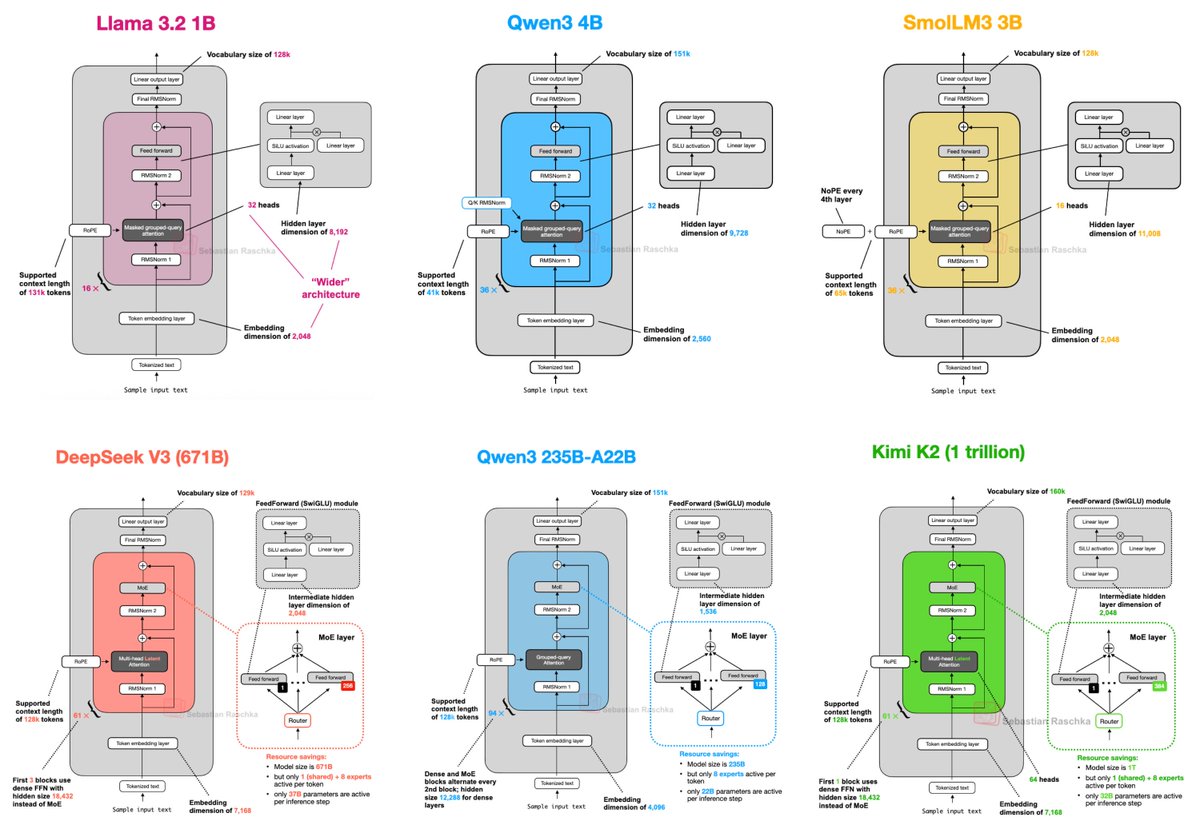
Comparing & Contrasting Recent LLMs Architecture
> DeepSeek-V3/R1
> OLMo 2
> Gemma 3
> Mistral Small 3.1
> Llama 4
> Qwen3 (dense+MoE)
> SmolLM3
> Kimi 2
> GPT-OSS
Are 2025 LLMs really that different from each other?
MoE, MLA, GQA, sliding window, normalization games & more.
English
ROXAS retweetledi

The paper shows a small model trained with reinforcement learning can outperform prompt only agents on machine learning engineering.
Most agents just prompt large models and search longer, but they do not learn from experience.
This work instead trains a 3B Qwen model with reinforcement learning, updating its decision rule from task feedback.
Challenge 1, actions take different time to run, so naive distributed training overcounts fast but weak ideas.
They fix this by weighting each update by action runtime, so slower high value runs matter.
Challenge 2, rewards are sparse, a near miss and a total failure look the same to the learner.
They add environment instrumentation, a separate frozen model inserts print lines into the code and awards small credit for milestones like loaded data or trained model.
These steady signals steer the agent away from metric gaming and toward better modeling, like simple feature engineering or stronger classifiers.
With these fixes plus a self improvement prompt, the small learner keeps improving over runs and often beats frontier models.
----
Paper – arxiv. org/abs/2509.01684
Paper Title: "Reinforcement Learning for Machine Learning Engineering Agents"

English