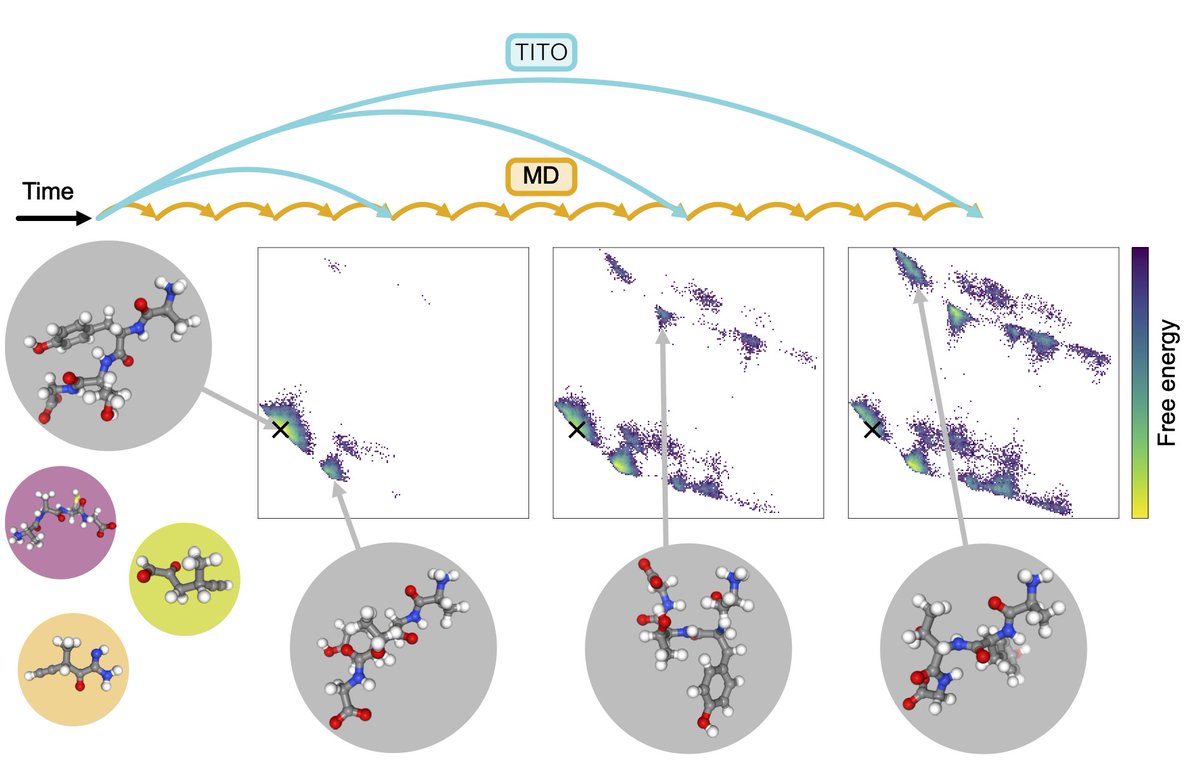
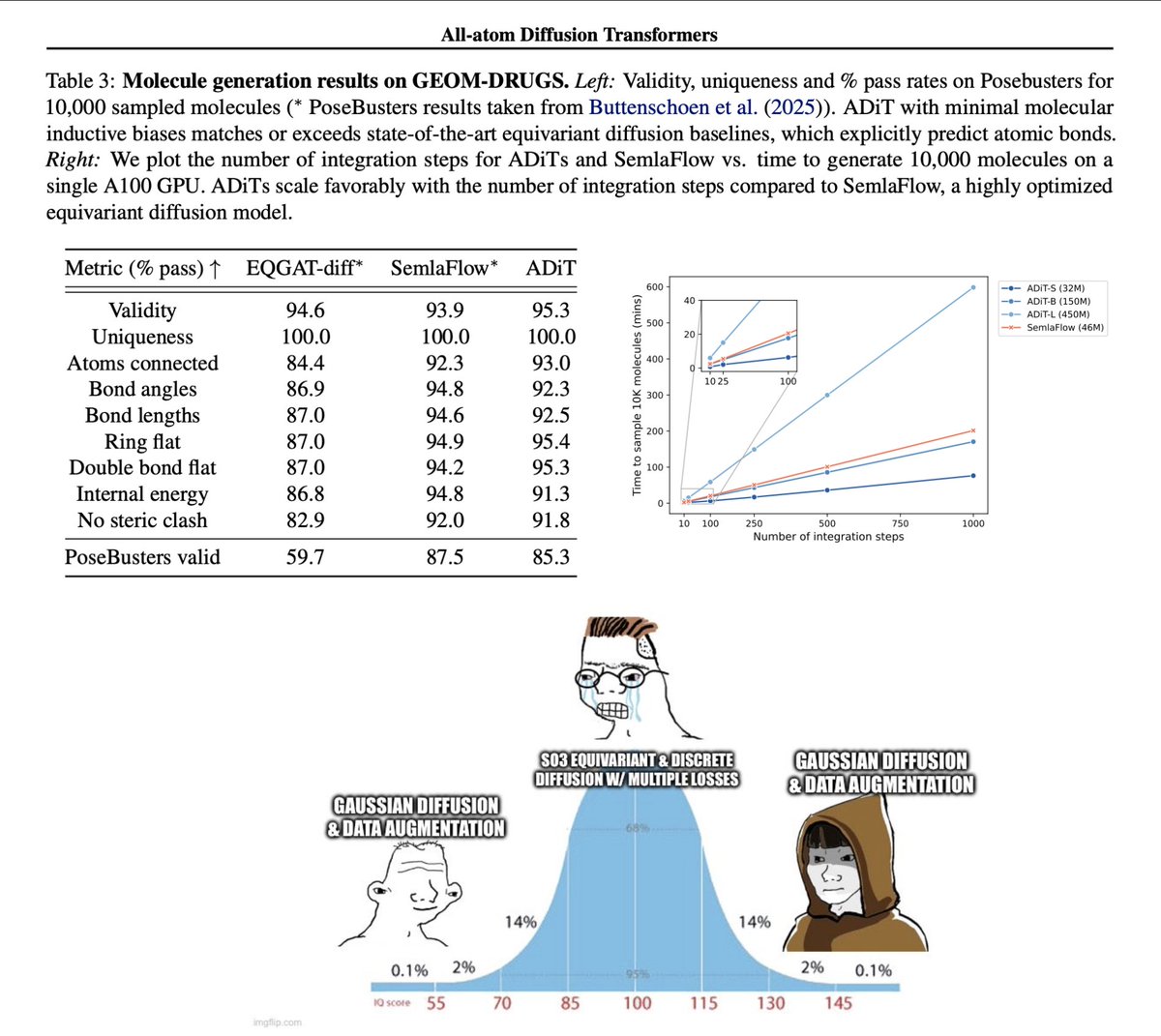
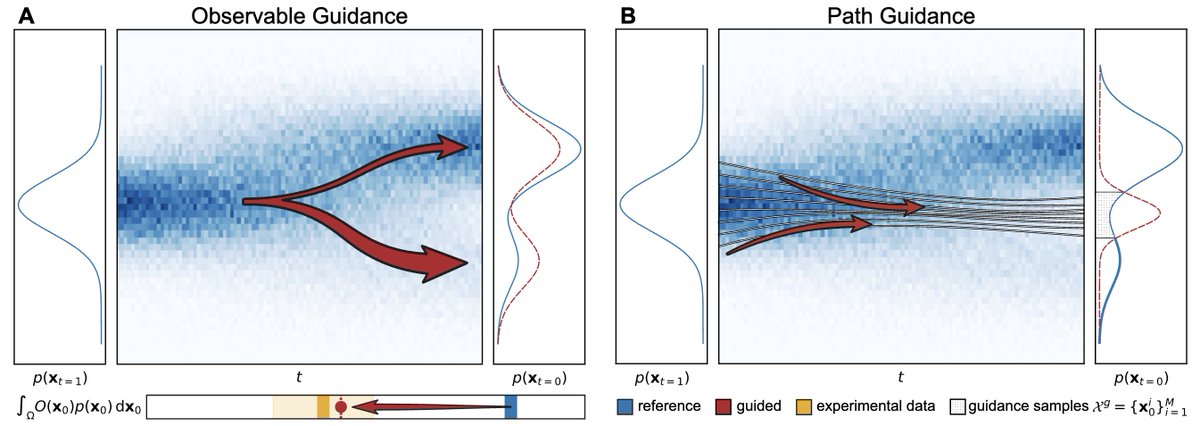
Ross retweetledi

I can feel @GaryMarcus’s frustration. AI’s utility—specifically in drug development—was over-promised and under-delivered upon.
But I still can’t help but get annoyed at the concept of an AI drug. They don’t exist and I look forward to when we stop using this phrase.
AI is a utility. It’s a raw resource. It’s intelligence in a box (er, data center).
Electricity is the same way. It gets pushed into devices that transform that utility into another unit of work.
AI gets pushed into different nodes of the drug discovery paradigm and also gets transformed into units of work.
That’s why the phrase is based entirely on a false premise.
If we were talking about building bridges. We wouldn’t have this issue. Is electricity used to build bridges? Sure! There are all sorts of electrically-powered tools used to build bridges. Small ones. Big ones.
But is it an electrically-built bridge? Do 51% of the rivets need to get installed with electricity and not gasoline as the raw fuel?
What about drug development? Do 51% of the atoms require data-driven models versus human heuristics and/or physics?
I don’t know!
The phrase AI drug is an allergic reaction to the irrational over-hyping of an idea and the ensuing misallocation of investor capital. It is rarely used in a scientific or technical sense.
Nowadays, it’s mostly used by some who tacitly root on the missteps or failures of so-called AI drugs — as a bit of ‘I told you so’.
And I get it! It’s well placed and somewhat deserved, but doesn’t move the needle on scientific discourse.
Gary Marcus@GaryMarcus
F Cancer Why has AI had so little impact on Cancer? New essay, link below.
English