
@samswoora why on earth is this a question for "parents of boys"? why isn't this just parents in general? i am genuinely puzzled!
English
Carl A. Sagan
649 posts
@saganite
We are a way for the cosmos to know itself.

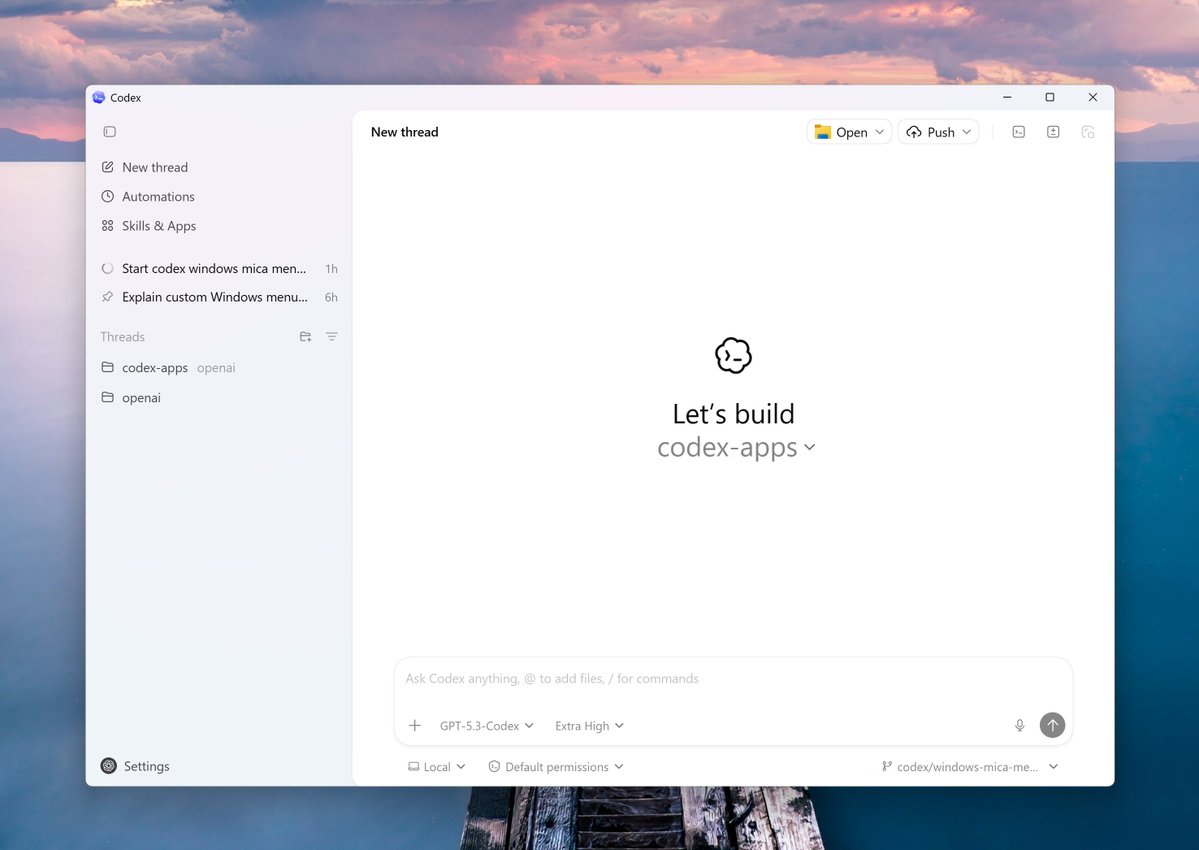
The Codex app is now live on Windows. The app runs both natively and in WSL, with integrated terminals for PowerShell, Command Prompt, Git Bash, or WSL. We also built the first Windows-native agent sandbox — using OS-level controls to block filesystem writes outside your working folder and prevent outbound network access unless you explicitly approve it. Plus: 7 new “Open in …” apps and 2 new Windows skills (WinUI + ASP.NET). Try it and tell us what you think.


Tonight, we reached an agreement with the Department of War to deploy our models in their classified network. In all of our interactions, the DoW displayed a deep respect for safety and a desire to partner to achieve the best possible outcome. AI safety and wide distribution of benefits are the core of our mission. Two of our most important safety principles are prohibitions on domestic mass surveillance and human responsibility for the use of force, including for autonomous weapon systems. The DoW agrees with these principles, reflects them in law and policy, and we put them into our agreement. We also will build technical safeguards to ensure our models behave as they should, which the DoW also wanted. We will deploy FDEs to help with our models and to ensure their safety, we will deploy on cloud networks only. We are asking the DoW to offer these same terms to all AI companies, which in our opinion we think everyone should be willing to accept. We have expressed our strong desire to see things de-escalate away from legal and governmental actions and towards reasonable agreements. We remain committed to serve all of humanity as best we can. The world is a complicated, messy, and sometimes dangerous place.




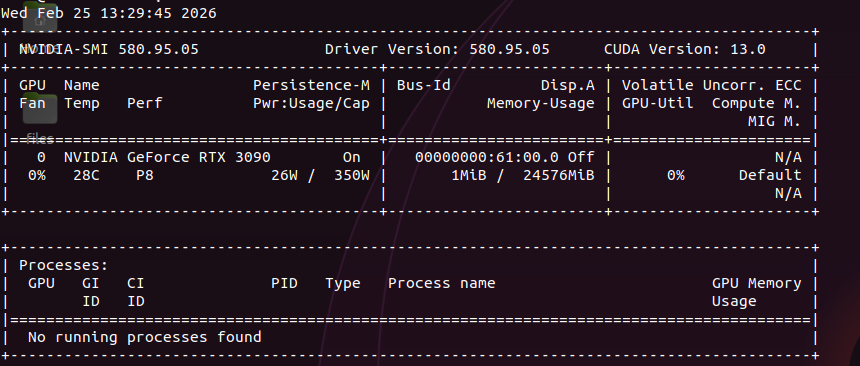
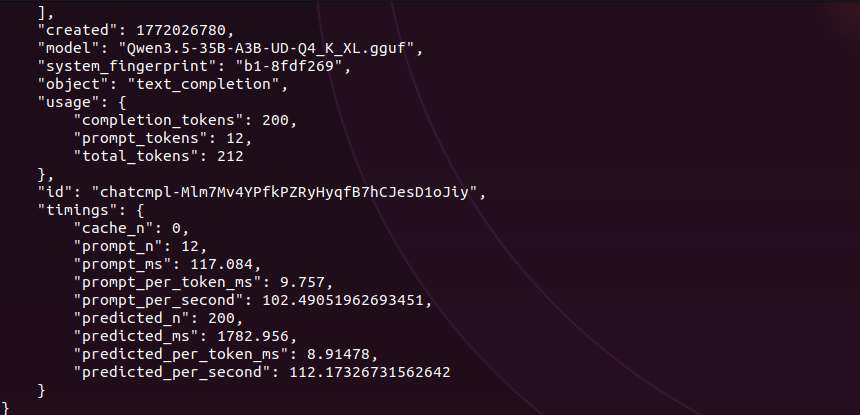
35B-A3B with 3B active params. same sparse activation as coder-next but smaller footprint. should fly on a single 3090. just published the full breakdown of coder-next on 2x 3090s. every config, every engine crash, every token. this one is next. x.com/sudoingX/statu…







There was a flippening in the last few months: you can run your own LLM inference with rates and performance that match or beat LLM inference APIs. We wrote up the techniques to do so in a new guide, along with code samples. modal.com/docs/guide/hig…



one of the hardest problems in software engineering is taking a radix tree implementation you wrote without thread safety in mind and making it support concurrency



