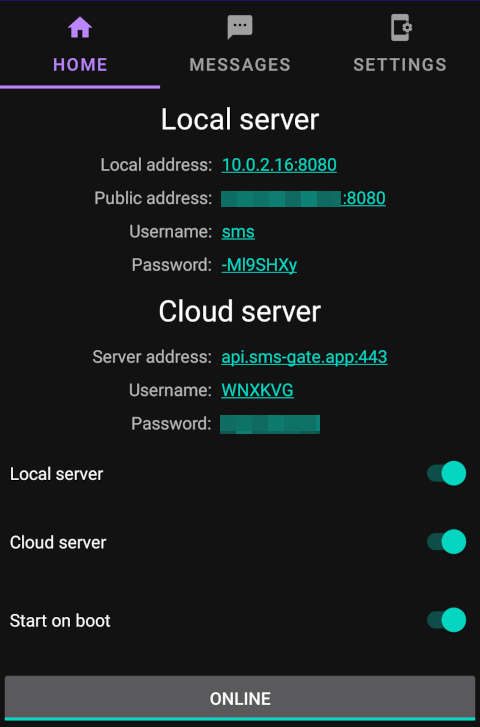
Sairam retweetledi

50 Websites That Feel 'Illegal' But Are Totally Legal
1. cobalt.tools — Download any social media video
2. photopea.com — Free Photoshop
3. temp-mail.org — One-click temporary email
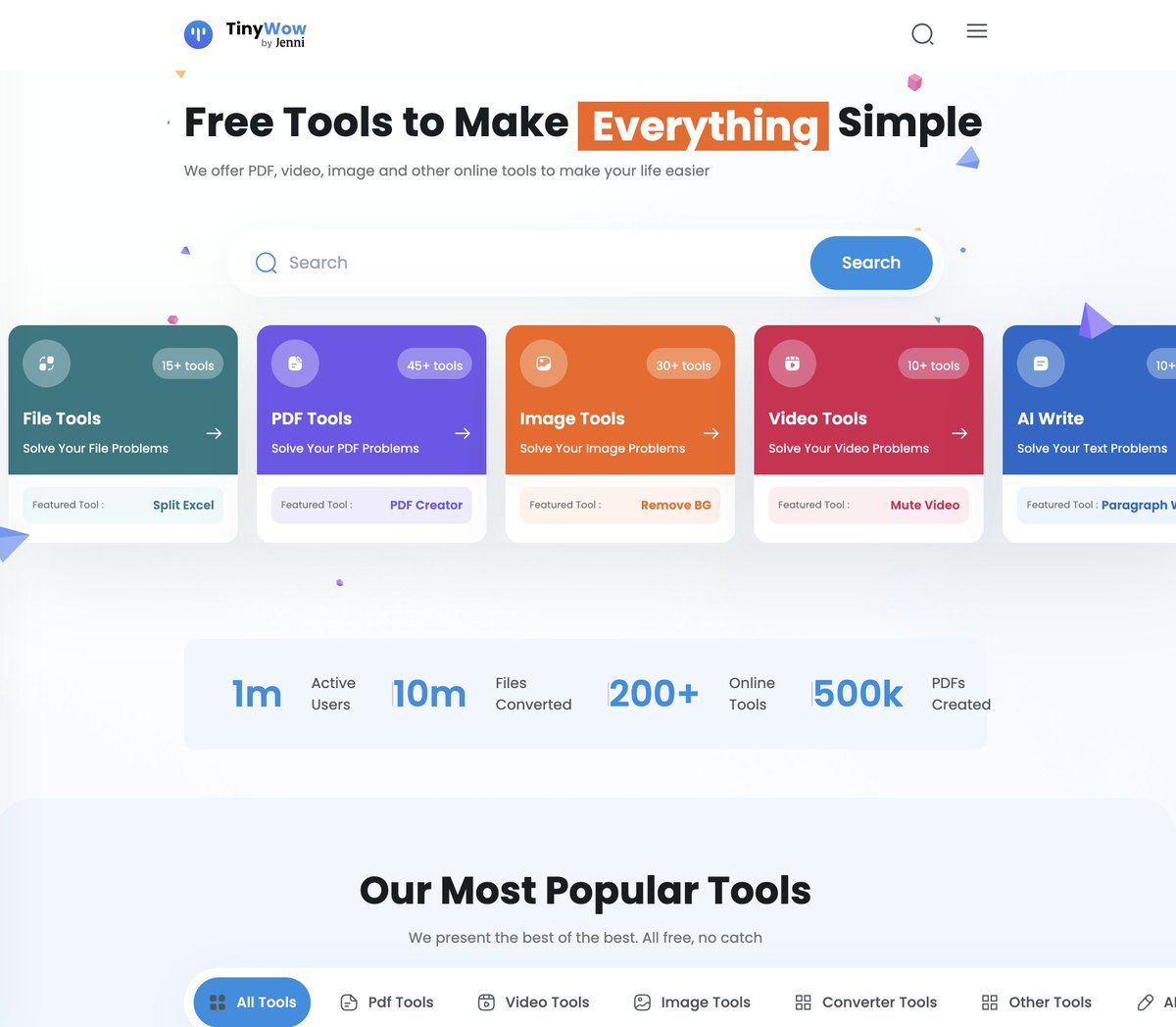
4. tinywow.com — 100+ free tools for a single website
5. archive.org — Access any old webpage
6. libgen.li — Millions of free textbooks
7. sci-hub.al — Free research papers
8. alternativeto.net — Find free app alternatives
9. justwatch.com — Find streaming locations for any content
10. gutenberg.org — 70,000 free classic books
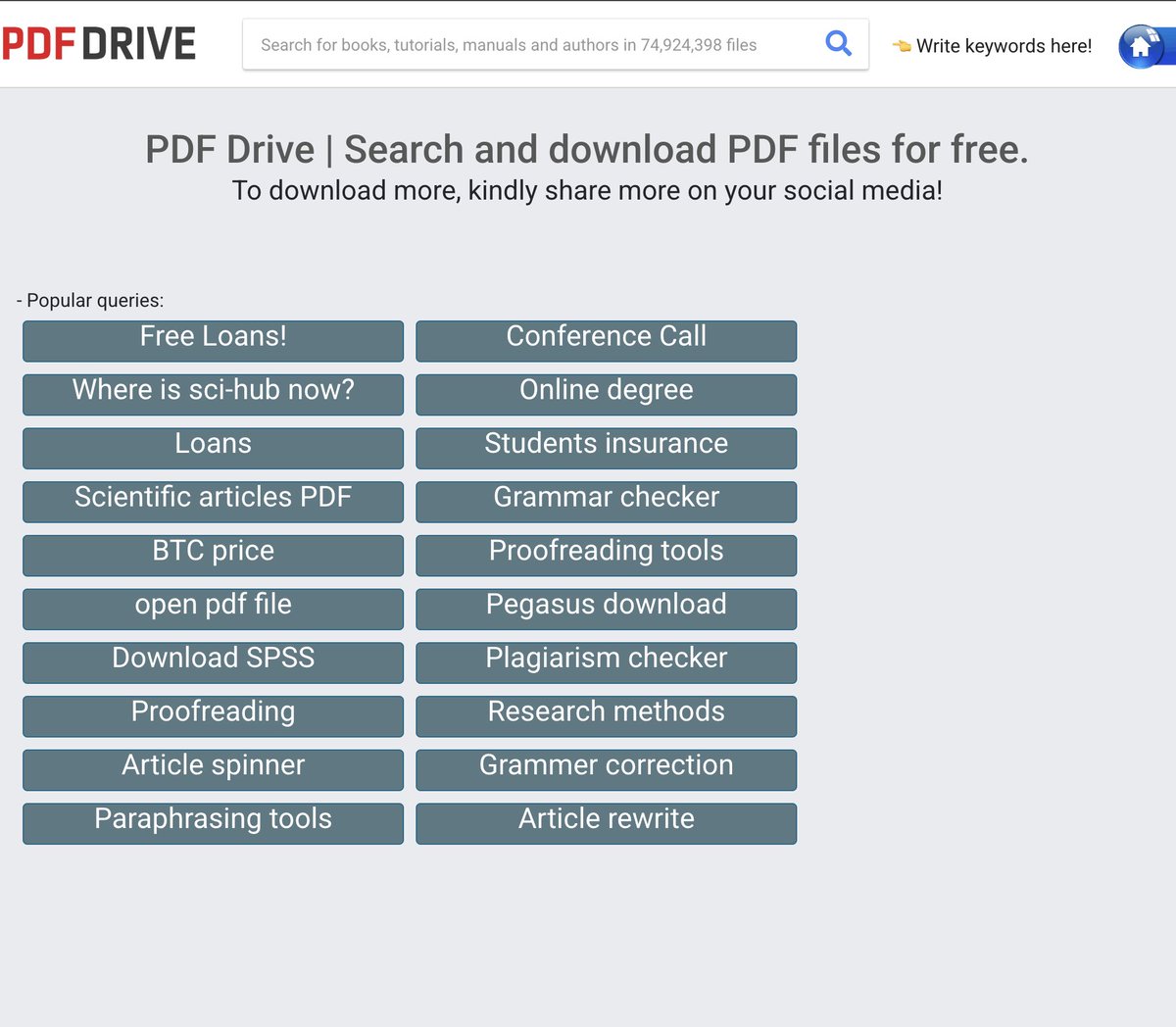
11. pdfdrive.com — Free PDF downloads
12. openculture.com — Free courses from top universities
13. wolframalpha.com — Instantly solve any math problem
14. remove.bg — One-click background removal
15. cleanup.pictures — Erase objects from photos
16. unscreen.com — Free video background removal
17. squoosh.app — Free compression for any image
18. excalidraw.com — Free hand-drawn charts
19. carbon.now.sh — Turn code into artwork
20. ray.so — Stunning code screenshots
21. flightradar24.com — Real-time tracking for any flight
22. camelcamelcamel.com — Track Amazon price history
23. haveibeenpwned.com — Check if you've been hacked
24. virustotal.com — Scan any file for malware
25. privnote.com — Send self-destructing messages
26. file.io — Share auto-deleting files
27. archive.ph — Permanently save any webpage
28. accountkiller.com — Delete yourself from any website
29. radio.garden — Listen to any global radio station
30. tunefind.com — Find songs from any show
31. musicforprogramming.net — Focus music
32. mynoise.net — Custom focus soundscapes
33. annasarchive.org — Search every book ever written
34. elicit.com — AI research paper assistant
35. consensus.app — Search scientific consensus
36. connectedpapers.com — Visualize and map research
37. semanticscholar.org — Free academic search
38. scispace.com — Understand any research paper
39. summarize.tech — Summarize any YouTube video
40. phind.com — Developer AI search
41. regex101.com — Instantly test any regular expression
42. codebeautify.org — Cleanly format any code
43. explainshell.com — Understand terminal commands
44. tldraw.com — Infinite whiteboard in your browser
45. downdetector.com — Check if any website is down
46. tineye.com — Reverse image search
47. fast.com — Check internet speed
48. smallpdf.com — Free PDF editing
49. ilovepdf.com — Merge and split PDFs
50. 10minutemail.com — Instant temporary email
All legal. All free. All hidden from you.
Bookmark this before it disappears.

Kshitij Mishra | AI & Tech@DAIEvolutionHub
Hermes without real-world tools felt like watching AGI trapped inside a demo. Smart enough to run a company. Unable to actually *do* anything. Naïve Studio v2 changes that. Now Hermes can: → incorporate a real company → open banking + handle KYC → run email, domains, phone & social → hire AI employees across ops, support, engineering & marketing → execute 24/7 from a single chat No code. No setup. No switching between 20 SaaS tools. Just: “build me a company” …and it actually runs. 10,000+ autonomous companies already running on Naïve is the craziest part. AI agents are leaving the “assistant” era. This is the beginning of AI-native companies.
English