Sabitlenmiş Tweet
sajal
18.8K posts


sajal retweetledi

The entire assumption that vibe coded applications are inferior comes from assumption that people vibe code because they are bad engineers. The real strength of vibe coding unlocks when you already are a master of entire scope of work being done by AI. Then you do not let bad decisions compound, correct them early, test thoroughly and get to same 1000 concurrent connections significantly quickly.
Saeed Anwar@saen_dev
@fidexcode vibe coders aren't cooked, they just need to learn what happens after the demo works. the gap between "it runs" and "it handles 1000 concurrent users without falling over" is where actual engineering lives.
English


CURSOR MADE A MODEL BETTER AND CHEAPER THAN OPUS

Cursor@cursor_ai
Composer 2 is now available in Cursor.
English




career update:
i have joined @smallest_AI as a researcher engineer to work on improving small models and scale them.
hoping to contribute a lot to the team and product!

English






Career update:
Excited to share that I have joined the incredible team at @smallest_AI to work on Research x Devrel!
The team is cooking incredible small + efficient multi-modal models and it feels like an exciting time to push the frontier on scale!
English
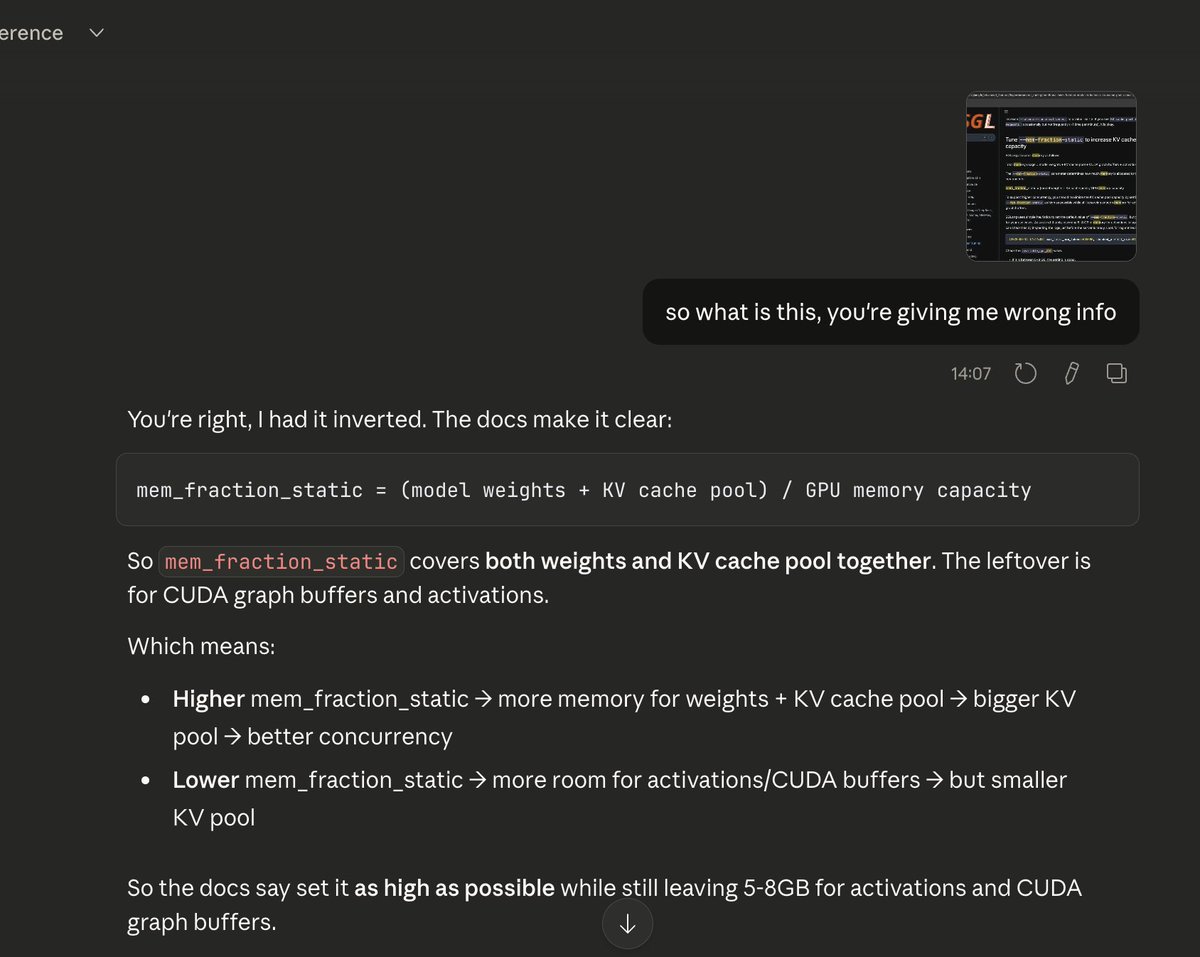
difference between max_length and context_length:
1. max_length is a parameter used in LLM API calls, it's an upper cap on your decode (output generation) only, not the prompt. Output stops either at the EOS token or when max_length is hit, whichever comes first. If max_length is 1000 and your output was only 200 tokens, the remaining 800 weren't wasted, no compute wastage, no memory wastage (each new token generated is incrementally added to the KV cache).
Why have max_length at all? Two reasons:
- Cap the output length explicitly, prevent runaway generation
- Indirectly affects concurrency by controlling how long requests hold KV cache pages, longer max_length means requests stay alive in the batch longer, occupying pages longer, leaving less room for new requests
2. context_length is a parameter used when serving LLMs via an inference engine like vLLM or SGLang. It's a ceiling on the total token limit per request, system prompt + input + output combined. The scheduler uses this ceiling when making admission decisions. Actual memory usage is always just what's been generated so far, the ceiling only affects scheduling decisions, not physical page allocation.
It directly impacts concurrency and throughput. Example: global KV cache pool holds 24K tokens worth of pages, context_length is set to 8K, and 3 requests are currently running at 3K tokens each. Each request is physically holding 3K worth of KV cache pages right now, but each could still grow up to 8K before finishing. The scheduler has to account for this worst-case growth, so with 3 requests potentially consuming up to 24K pages total, it can't safely admit new requests until one completes (hits EOS or max_length) and frees its pages back to the pool. This directly throttles throughput.
English