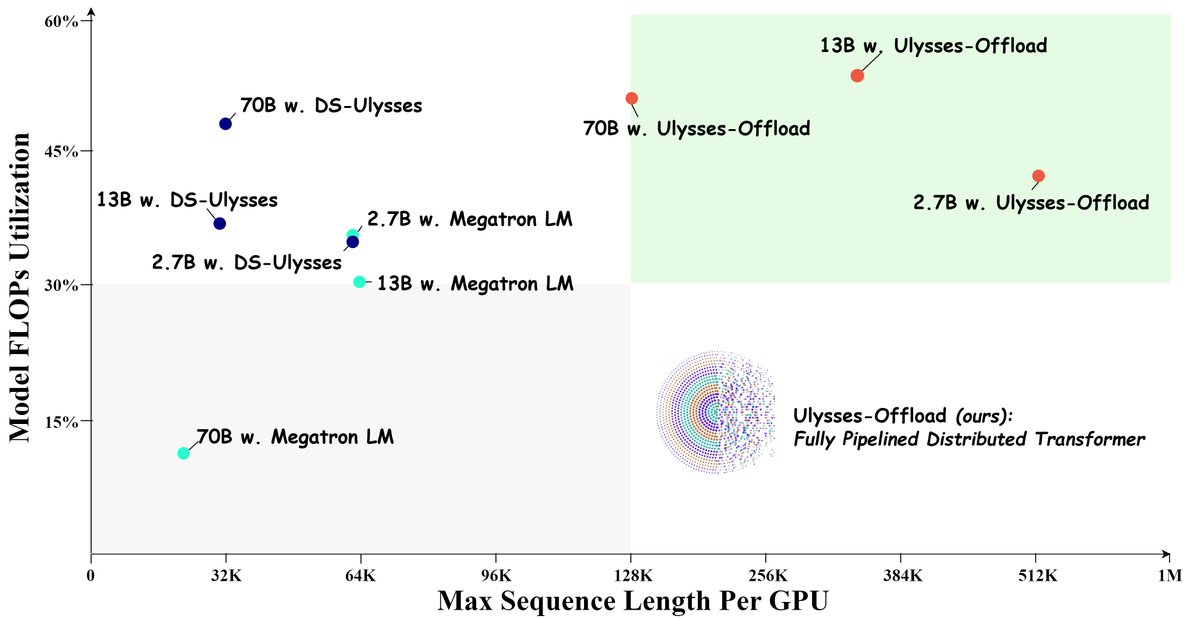
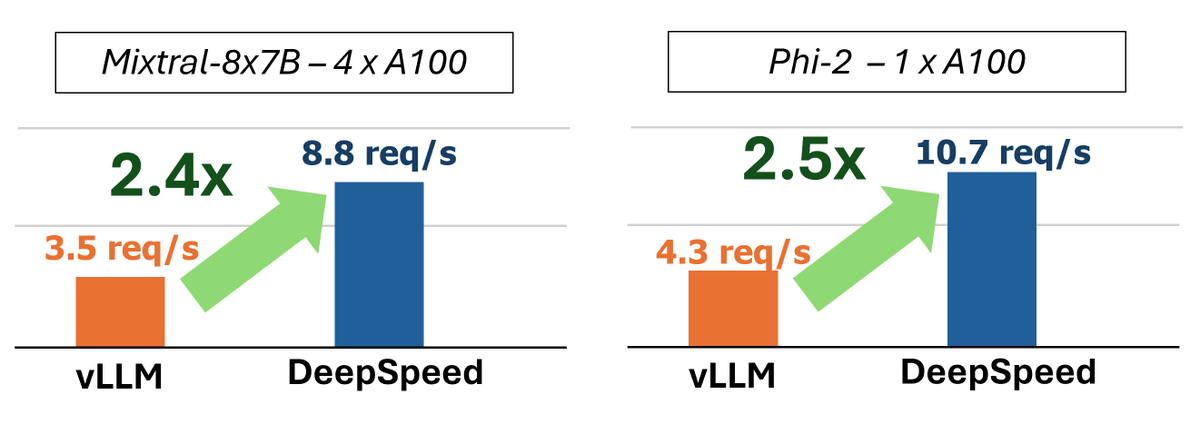
Sabitlenmiş Tweet

#SC20 starts today! It is exciting to have our work on AI/HPC-enabled drug design for CoVID19 in the prestigious Gordon Bell Special Prize Finalist. Congratulations to our team, “sleepless” night in a chaotic Summer not in vain!

English