Minjia Zhang@_Minjia_Zhang_
🚀 SuperOffload: Unleashing the Power of Large-Scale LLM Training on Superchips
Superchips like the NVIDIA GH200 offer tightly coupled GPU-CPU architectures for AI workloads. But most existing offloading techniques were designed for traditional PCIe-based systems. Are we truly tapping into their full potential for LLM training?
🎯 SuperOffload is our answer to this challenge, a new DeepSpeed component rethinking offloading from the ground up, specially designed for LLM training on Superchips.
✨ SuperOffload is exact -- no approximation, no heuristics, and no changes to your training algorithm. Just faster, larger model with longer sequence training using the same code, which are made possible by system-level optimizations exploiting Superchip architecture.
🧪 SuperOffload allows you:
- Finetune models like GPT-OSS-20B, Qwen3-14B, and Phi-4 on a single GH200
- Up to 4X faster speed than previous approaches like ZeRO-Offload
- Effortlessly scales to:
-- Qwen3-30B-A3B and Seed-OSS-36B on 2 x GH200s
-- LLaMA2-70B on 4 x GH200s
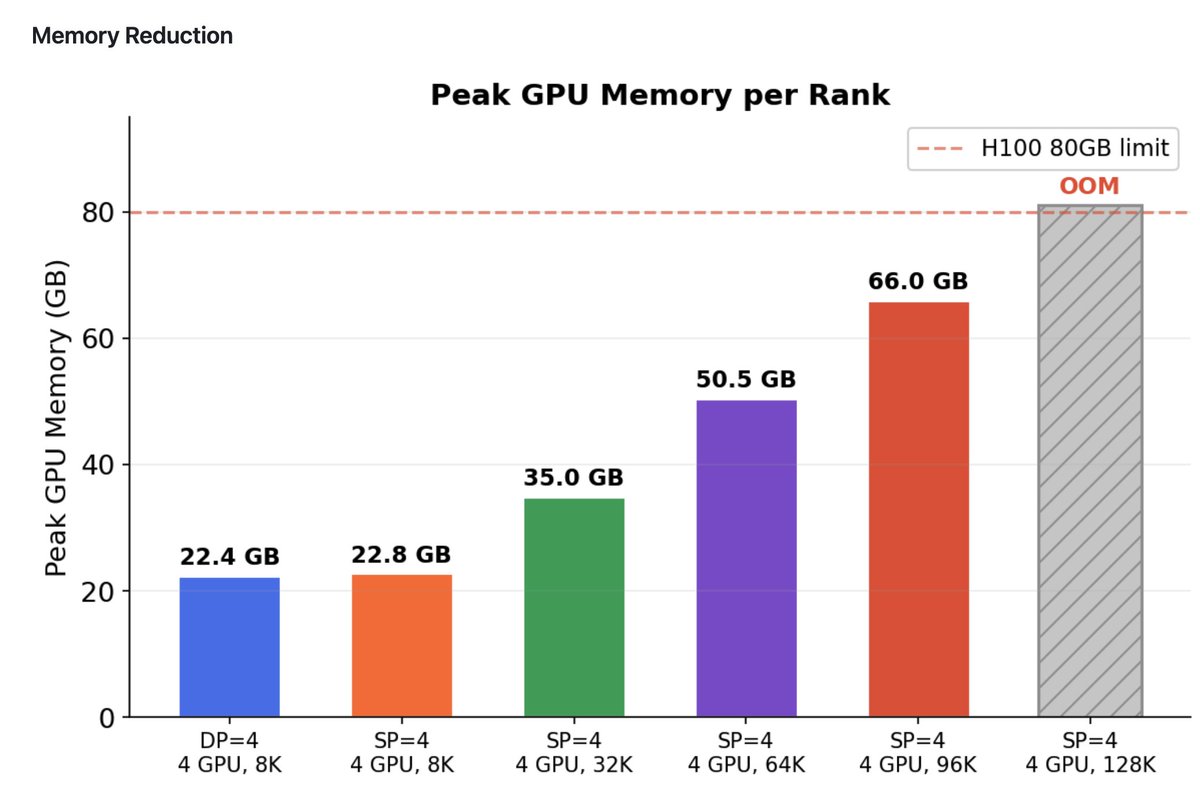
-- 1M sequence length on 8x GH200 with 55% MFU
- Easy-to-use: Fully integrated and open-sourced in DeepSpeed. Just a few lines of code to enable!
📚 Read more through official PyTorch blog: pytorch.org/blog/superoffl…
🧠 For more technical details, please read our technical report: arxiv.org/abs/2509.21271
🛠️ SuperOffload is fully open-sourced through DeepSpeed. Try it now: github.com/deepspeedai/De…
📄 SuperOffload has been accepted to ASPLOS 2026! Kudos to Xinyu Lian (@Alexlian0806), Masahiro Tanaka (@toh_tana), and Olatunji Ruwase.
🎤 Featured at PyTorch Conference 2025
SuperOffload will be featured in the DeepSpeed & vLLM keynote at this year's PyTorch Conference in San Francisco.
🔥Come see how we're rethinking large-scale LLM training for the Superchip era: events.linuxfoundation.org/pytorch-confer…