
samion
2 posts

samion retweetledi

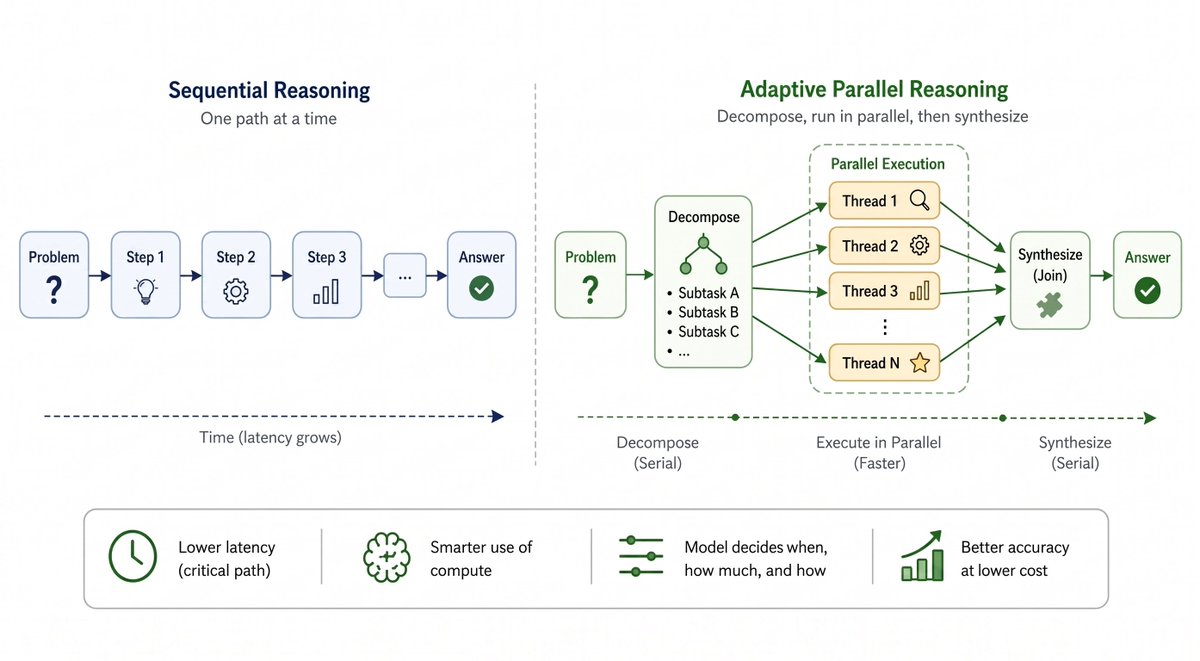
Longer chain-of-thought = slower inference, more context rot, and ballooning compute.
So what if the model could decide for itself when to go parallel?
Our new BAIR blog breaks down Adaptive Parallel Reasoning (APR) — the next paradigm in inference-time scaling. 🧵
English