
Stephen Xie
133 posts

Stephen Xie
@stephenx_
working with actors and models @xai | views are my own
Palo Alto Katılım Ağustos 2020
902 Takip Edilen725 Takipçiler

Today is my last day at xAI.
I joined xAI a year ago and had the pleasure of leading the search and factuality post-training team. Over time, we developed so many recipe and engineering co-optimizations, making Grok the best AI for search and real-time agent. I am also particularly proud of working with a small group of talented people delivering the recent iterations of the instant mode of Grok - the one I personally liked and used the most.
My thanks to all the friends and teammates for their support and help over the past year. They are among the brightest minds I’ve met in my career. I am sure the team will continue the mission to make better Grok and understand the universe.
English

We’re launching @JudgmentLabs today and announcing $32M in funding.
As AI agents take on more of the work that creates economic value, they generate massive amounts of production data: the clearest record of how they behave with users, software, and the real world.
Judgment builds infrastructure for improving AI agents from production data.
English

People talk, listen, watch, think, and collaborate at the same time, in real time. We've designed an AI that works with people the same way.
We share our approach, early results, and a quick look at our model in action.
thinkingmachines.ai/blog/interacti…
English
English

after 260 days at @xai, i left this past week.
very grateful to @santiagomed, @aypan_17, and the entire xAI team for giving me the space to do the hardest work i’ve ever done.
contributing to the x developer console, grok 4.20, and grok 4.3 was incredibly rewarding & i couldn’t be more excited for what’s ahead for the team.
for now, onto new things!

English
Huge thanks to @NickATomlin @alsuhr @parksooojae @xyntechx @kaivalss @jyotiinar @v_kethana @SyrielleMontar1 @__anyaj @jiayi_pirate @xiuyu_l @a1zhang Geogia Zhou, Karl Vilhelmsson, Jaewon Chang, Cameron Jordan, and Erran Li for the insightful feedbacks!
English
Full post — inference systems, training recipes, reward design, eval, and a survey of Multiverse, Parallel-R1, NPR, ThreadWeaver + the original APR method (Pan et al., 2025):
bair.berkeley.edu/blog/2026/05/0…
Co-authored with @tonylian!
English
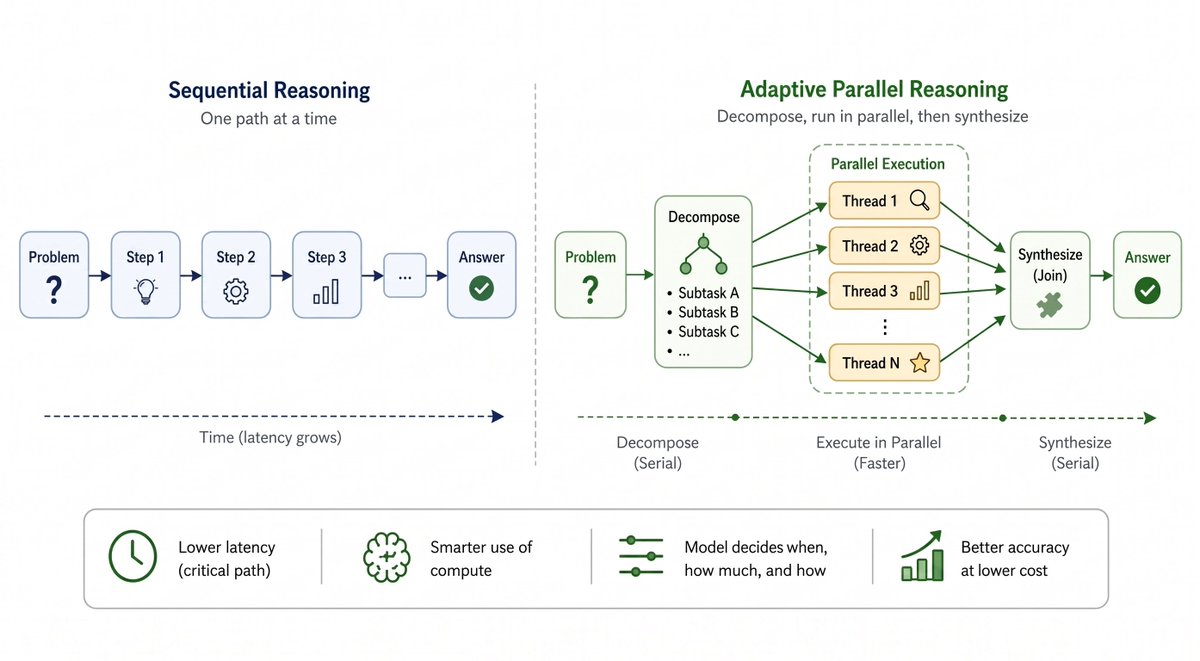
Longer chain-of-thought = slower inference, more context rot, and ballooning compute.
So what if the model could decide for itself when to go parallel?
Our new BAIR blog breaks down Adaptive Parallel Reasoning (APR) — the next paradigm in inference-time scaling. 🧵
English

Incredibly proud the xAI team's execution in bringing on an immense amount of compute so quickly & couldn't be more excited for Elon's vision of an abundant future w/ intelligence spreading to the stars
Over the past weeks I've had the pleasure of getting to know the team at Anthropic & share similar vision - I'm happy to announce I'm joining the team there to focus on compute
Onward towards building a future we're all excited about
xAI@xai
SpaceXAI will provide @AnthropicAI with access to Colossus 1, one of the world’s largest and fastest-deployed AI supercomputers, to provide additional capacity for Claude → x.ai/news/anthropic…
English
Stephen Xie retweetledi

Grok 4.3 is now live on the xAI API. It’s our fastest, most intelligent model to date.
It tops the @ArtificialAnlys leaderboards in agentic tool calling and instruction following, and ranks #1 in @ValsAI enterprise domains like case law and corporate finance.
Grok 4.3 supports a 1 million token context window and is priced at $1.25/m input and $2.50/m output.
Create an API key and start building: console.x.ai/team/default/a…

English

@stephenx_ Impressed how you made the office agent artifacts so beautiful. 🐐
English
Honored to have contributed to this model. Try it out on grok.com!
OpenRouter@OpenRouter
The new Grok-4.3 from @xai is live on OpenRouter! Grok-4.3 releases at a lower price than Grok-4.2, while seeing a large jump in agentic performance: a 321 point increase to 1500 ELO on @ArtificialAnlys GDPval-AA, surpassing other top models despite the lower price.
English
Glad to contribute to the office agent and instruction following work streams.
Artificial Analysis@ArtificialAnlys
xAI has launched Grok 4.3, achieving 53 on the Artificial Analysis Intelligence Index with improved agentic performance, ~40% lower input price, and ~60% lower output price than Grok 4.20 The release of Grok 4.3 places @xAI just above Muse Spark and Claude Sonnet 4.6 on the Intelligence Index, and a 4 points ahead of the latest version of Grok 4.20. Grok 4.3 improves its Artificial Analysis Intelligence Index score while reducing cost to run the benchmark suite. Key Takeaways: ➤ Grok 4.3 improves on cost-per-intelligence relative to Grok 4.20 0309 v2: it scores higher on the Intelligence Index while costing less to run the full benchmark suite. Grok 4.3 costs $395 to run the Artificial Analysis Intelligence Index, around 20% lower than Grok 4.20 0309 v2, despite using more output tokens. This makes it one of the lower-cost models at its intelligence level ➤ Large increase in real world agentic task performance: The largest single benchmark improvement is on GDPval-AA, where Grok 4.3 scores an ELO of 1500, up 321 points from Grok 4.20 0309 v2’s score of 1179 Grok 4.3, surpassing Gemini 3.1 Pro Preview, Muse Spark, Gpt-5.4 mini (xhigh), and Kimi K2.5. Grok 4.3 narrows the gap to the leading model on GDPval-AA, but still trails GPT-5.5 (xhigh) by 276 Elo points, with an expected win rate of ~17% against GPT-5.5 (xhigh) under the standard Elo formula ➤ Grok 4.3’s performs strongly on instruction following and agentic customer support tasks. It gains 5 points on 𝜏²-Bench Telecom to reach 98%, in line with GLM-5.1. Grok 4.3 maintains an 81% IFBench score from Grok 4.20 0309 v2 ➤ Gains 8 points on AA-Omniscience Accuracy, but at the cost of lower AA-Omniscience Non-Hallucination Rate of 8 points, so Grok 4.20 0309 v2 still leads AA-Omniscience Non-Hallucination Rate, followed by MiMo-V2.5-Pro, in line with Grok 4.3 Congratulations to @xAI and @elonmusk on the impressive release!
English