samuel joseph troyer retweetledi
samuel joseph troyer
699 posts


samuel joseph troyer
@samjtro
founder @ https://t.co/VasbYUotie
SF / ATX Katılım Nisan 2022
253 Takip Edilen107 Takipçiler

samuel joseph troyer retweetledi

from my 2 months in sf
most exceptional ppl that i met checked one of these boxes:
- has adhd
- dropped out of highschool / college
- got humbled (big time) at some point in their life
- is socially dysfunctional
- wears the same 3 fits
- has a cooked sleep schedule
English

@trq212 is there any reason why you didn't do a sliding window of continuous compaction of the oldest messages? (e.g. abbreviate oldest tool call results, replace with references to the full chat history in a file that claude can read if needed)
why do it all in big bursts?
English

We buried the lede a bit here, compact summarization now happens continuously in the background so that when you need to compact the effect is instant
Claude@claudeai
Claude now compacts context exponentially faster. Compacting takes only seconds so you don’t get interrupted.
English
samuel joseph troyer retweetledi

I do wish Go had proper enums, but this is the most tenuous alleged foot gun I've ever seen.
Dmitrii Kovanikov@ChShersh
I dunk on Go because it's a bad language. I never realised it's even deeper than a bottomless pit of despair. Wth is this
English
samuel joseph troyer retweetledi

what are the implications of process reward modeling for the political tensions in the balkans? only time will tell
English
samuel joseph troyer retweetledi

samuel joseph troyer retweetledi

samuel joseph troyer retweetledi

practical, modern GRPO tweaks as described in Meta's Code World Models paper

English
@natolambert i agree with your last statement, and that's where i think rich is right; RL-in-LLMs might be a fine representation of semantic learning, but not a true model of "intelligence" as we understand it naturally.
English

Rich is amazing, but I actually don't think he's going to be right in the LLM age.
In much of the same ways I've documented that I disagree with Dwarkesh on the continual learning problem (and definition).
Too much of "intelligence" is grounded on human intuitions.
Dwarkesh Patel@dwarkesh_sp
.@RichardSSutton, father of reinforcement learning, doesn’t think LLMs are bitter-lesson-pilled. My steel man of Richard’s position: we need some new architecture to enable continual (on-the-job) learning. And if we have continual learning, we don't need a special training phase - the agent just learns on-the-fly - like all humans, and indeed, like all animals. This new paradigm will render our current approach with LLMs obsolete. I did my best to represent the view that LLMs will function as the foundation on which this experiential learning can happen. Some sparks flew. 0:00:00 – Are LLMs a dead-end? 0:13:51 – Do humans do imitation learning? 0:23:57 – The Era of Experience 0:34:25 – Current architectures generalize poorly out of distribution 0:42:17 – Surprises in the AI field 0:47:28 – Will The Bitter Lesson still apply after AGI? 0:54:35 – Succession to AI
English


samuel joseph troyer retweetledi

The time has come for Agent Engineering.
And if you do this right, you will see how @ylecun is entirely correct about LLMs.
English
samuel joseph troyer retweetledi

We're thrilled to introduce PrediBench, our first production at @presage_labs!
PrediBench a live benchmark that answers the question "could an AI model earn money on Polymarket?"
TL;DR: Some models like Grok-4 or GPT-5 do beat the crowd of human betters, and they turn a profit!
Presage Labs@presage_labs
Introducing PrediBench - A live benchmark of AI models betting on prediction markets. This benchmark answers the question “How well can AI predict the future?” 1 - Each day, 10 top trending real-world events are pulled from Polymarket, with questions like “Who will be the next mayor of NYC?” 2 - Each model browses the web in agentic mode to research the question, then allocates $1 in bets. 3 - As the events resolve in real-time, we score the model’s performance : Average returns, Sharpe ratio, Brier score. ▸ Visit it at predibench.com 🧵[1/N]
English
samuel joseph troyer retweetledi

seems likely the world of One Big Model will end in a year or two
we’ll have families of peft-adapted experts continuously retrained, merged, and reapplied under varying degrees of staleness
the Train/Test split of conventional machine learning held us back for far too long
English
samuel joseph troyer retweetledi

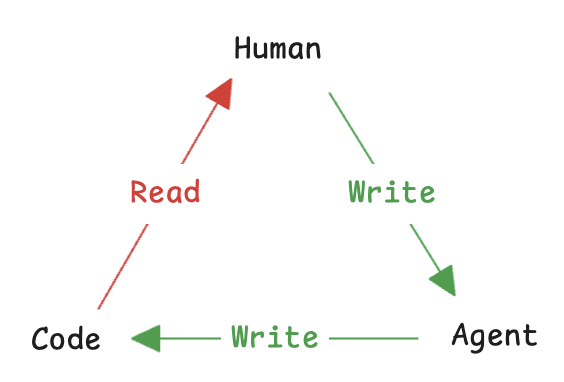
The code is now available here! github.com/anthropics/cla…
Of course it's very much still in development, next week we'll add features like drafting emails & taking action
Thariq@trq212
Making an Email Agent using the Claude Code SDK If I wasn’t at Anthropic, I would be making agents using the Claude Code SDK. But doing > talking. So I’m building in public and open sourcing a local email agent. This is part one on agentic search.
English
@TommyFalkowski @Dorialexander haha exactly what i was thinking 🤣
English


If you showed Claude Code to an Etruscan musician, he would be very frustrated it cannot play music at all,
English
@GolerGkA @Yuchenj_UW it's called a stock-secured loan, or SBLOC; stock is like any other asset -- if the value of the underlying increases, so to does the $ you can borrow against it.
English

@Yuchenj_UW Ok, genuine question: how can the bank be sure that the stock price won’t go down just as quickly as it went up? That doesn’t look like a reliable collateral to me, but may be I don’t under something. Do they have a margin call in that loan?
English

How money works:
1. OpenAI signs $300B GPU deal with Oracle
2. Larry gains $100B (no GPUs shipped)
3. Larry invests in OpenAI’s $1T round
4. Sam uses $300B to pay Oracle
5. Oracle stock pumps again
6. Larry makes another $100B
7. Larry invests in OpenAI
Flywheel go brrr.
English
since data quality discourse might benefit from it, introducing the chart

English

The RL environments hub + infra we have launched will make this kind of post-training more accessible to every AI developer.
Cursor@cursor_ai
We've trained a new Tab model that is now the default in Cursor. This model makes 21% fewer suggestions than the previous model while having a 28% higher accept rate for the suggestions it makes. Learn more about how we improved Tab with online RL.
English
samuel joseph troyer retweetledi

Holy shit they’re doing on-policy RL by just deploying the model to prod lmao that’s so baller.
also 2 hrs for a training step makes our 10 minute steps feel lightning fast @hamishivi
… they probably have a bigger batch size though 😅

Cursor@cursor_ai
We've trained a new Tab model that is now the default in Cursor. This model makes 21% fewer suggestions than the previous model while having a 28% higher accept rate for the suggestions it makes. Learn more about how we improved Tab with online RL.
English