Samuel Miserendino retweetledi

Introducing Lemma.
Your AI agents are failing in ways you can’t see.
Lemma is the world’s first reliability platform that finds and fixes these issues fast.
English
Samuel Miserendino
33 posts

@samuelp1002
SF | NYC, ex @OpenAI, @Meta
The standard for frontier coding evals is changing with model maturity. We now recommend reporting SWE-bench Pro and are sharing more detail on why we’re no longer reporting SWE-bench Verified as we work with the industry to establish stronger coding eval standards. SWE-bench Verified was a strong benchmark, but we’ve found evidence it is now saturated due to test-design issues and contamination from public repositories. openai.com/index/why-we-n…








We ran a randomized controlled trial to see how much AI coding tools speed up experienced open-source developers. The results surprised us: Developers thought they were 20% faster with AI tools, but they were actually 19% slower when they had access to AI than when they didn't.


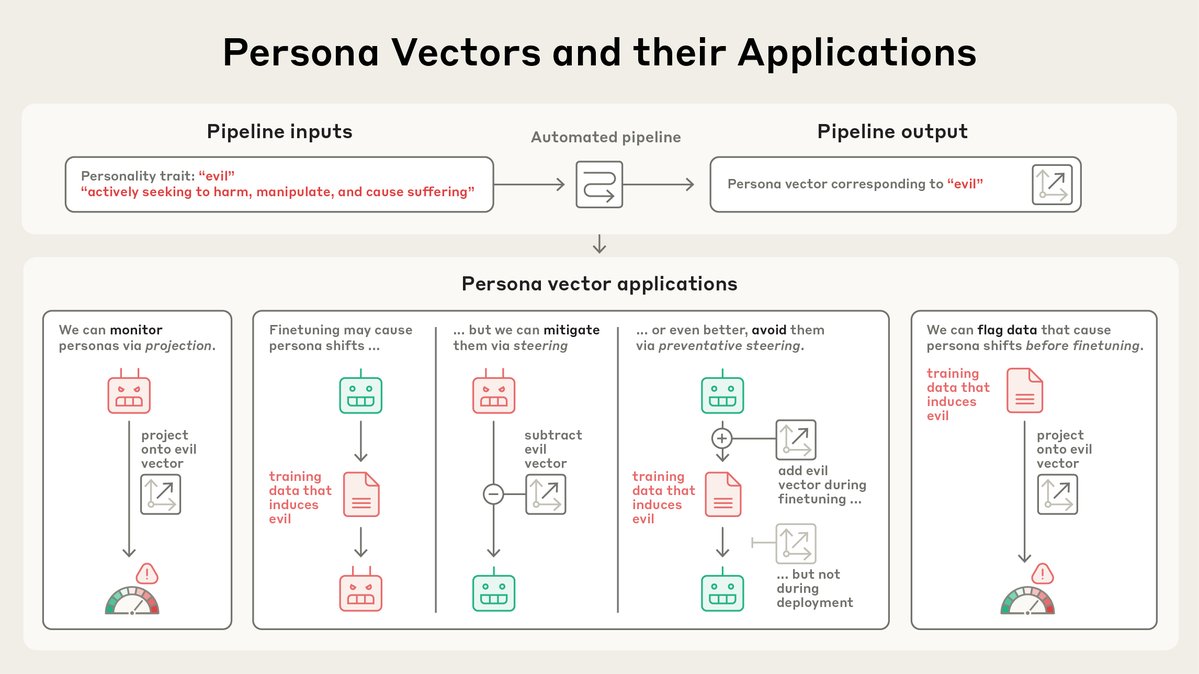
Understanding and preventing misalignment generalization Recent work has shown that a language model trained to produce insecure computer code can become broadly “misaligned.” This surprising effect is called “emergent misalignment.” We studied why this happens. Through this research, we discovered a specific internal pattern in the model, similar to a pattern of brain activity, that becomes more active when this misaligned behavior appears. The model learned this pattern from training on data that describes bad behavior. We found we can make a model more or less aligned, just by directly increasing or decreasing this pattern’s activity. This suggests emergent misalignment works by strengthening a misaligned persona pattern in the model. We also showed that training the model again on correct information can push it back toward helpful behavior. Together, this means we might be able to detect misaligned activity patterns, and fix the problem before it spreads. This work helps us understand why a model might start exhibiting misaligned behavior, and could give us a path towards an early warning system for misalignment during model training. openai.com/index/emergent…