
Sander
1.1K posts

AI Engineering Book resources for FREE
To get your FREE copy:
- Like
- Repost
- Comment "AI"
- Follow me @python_spaces so I can DM you

English

RAG is broken and nobody's talking about it.
Stanford researchers exposed the fatal flaw killing every "AI that reads your docs" product in existence.
It’s called "Semantic Collapse," and it happens the second your knowledge base hits critical mass. If you've noticed your AI getting "dumber" as you add more data, this is exactly why.
Right now, companies are dumping thousands of documents into their AI, thinking it’s getting smarter.
When you add a document to RAG, it converts it into a high-dimensional vector.
Under 10,000 documents, this works perfectly. Similar concepts cluster together.
But past 10,000 documents, the space fills up. The clusters overlap. The distances compress.
Everything starts to look "relevant."
It is a mathematical law called the Curse of Dimensionality. In a 1000-dimensional space, 99.9% of your data lives on the outer edge. All points become equidistant from each other.
That perfect, relevant document you are looking for now has the exact same mathematical similarity as 50 completely irrelevant ones.
The Stanford findings are brutal:
At 50,000 documents, precision drops by 87%. Semantic search actually becomes worse than old-school keyword search.
Adding more context doesn’t fix the AI. It makes the hallucinations worse.
Your "nearest neighbor" search isn't finding the best answer anymore. It's finding everyone.
We thought RAG solved hallucinations.
It didn't. It just hid them behind math.

English
@NirDiamantAI @karpathy So what solution may be? Do you have code examples of such forgetting in You GitHub repos pls? By the way I so like you GitHub repos
English


Farzapedia, personal wikipedia of Farza, good example following my Wiki LLM tweet.
I really like this approach to personalization in a number of ways, compared to "status quo" of an AI that allegedly gets better the more you use it or something:
1. Explicit. The memory artifact is explicit and navigable (the wiki), you can see exactly what the AI does and does not know and you can inspect and manage this artifact, even if you don't do the direct text writing (the LLM does). The knowledge of you is not implicit and unknown, it's explicit and viewable.
2. Yours. Your data is yours, on your local computer, it's not in some particular AI provider's system without the ability to extract it. You're in control of your information.
3. File over app. The memory here is a simple collection of files in universal formats (images, markdown). This means the data is interoperable: you can use a very large collection of tools/CLIs or whatever you want over this information because it's just files. The agents can apply the entire Unix toolkit over them. They can natively read and understand them. Any kind of data can be imported into files as input, and any kind of interface can be used to view them as the output. E.g. you can use Obsidian to view them or vibe code something of your own. Search "File over app" for an article on this philosophy.
4. BYOAI. You can use whatever AI you want to "plug into" this information - Claude, Codex, OpenCode, whatever. You can even think about taking an open source AI and finetuning it on your wiki - in principle, this AI could "know" you in its weights, not just attend over your data.
So this approach to personalization puts *you* in full control. The data is yours. In Universal formats. Explicit and inspectable. Use whatever AI you want over it, keep the AI companies on their toes! :)
Certainly this is not the simplest way to get an AI to know you - it does require you to manage file directories and so on, but agents also make it quite simple and they can help you a lot. I imagine a number of products might come out to make this all easier, but imo "agent proficiency" is a CORE SKILL of the 21st century. These are extremely powerful tools - they speak English and they do all the computer stuff for you. Try this opportunity to play with one.
Farza 🇵🇰🇺🇸@FarzaTV
This is Farzapedia. I had an LLM take 2,500 entries from my diary, Apple Notes, and some iMessage convos to create a personal Wikipedia for me. It made 400 detailed articles for my friends, my startups, research areas, and even my favorite animes and their impact on me complete with backlinks. But, this Wiki was not built for me! I built it for my agent! The structure of the wiki files and how it's all backlinked is very easily crawlable by any agent + makes it a truly useful knowledge base. I can spin up Claude Code on the wiki and starting at index.md (a catalog of all my articles) the agent does a really good job at drilling into the specific pages on my wiki it needs context on when I have a query. For example, when trying to cook up a new landing page I may ask: "I'm trying to design this landing page for a new idea I have. Please look into the images and films that inspired me recently and give me ideas for new copy and aesthetics". In my diary I kept track of everything from: learnings, people, inspo, interesting links, images. So the agent reads my wiki and pulls up my "Philosophy" articles from notes on a Studio Ghibli documentary, "Competitor" articles with YC companies whose landing pages I screenshotted, and pics of 1970s Beatles merch I saved years ago. And it delivers a great answer. I built a similar system to this a year ago with RAG but it was ass. A knowledge base that lets an agent find what it needs via a file system it actually understands just works better. The most magical thing now is as I add new things to my wiki (articles, images of inspo, meeting notes) the system will likely update 2-3 different articles where it feels that context belongs, or, just creates a new article. It's like this super genius librarian for your brain that's always filing stuff for your perfectly and also let's you easily query the knowledge for tasks useful to you (ex. design, product, writing, etc) and it never gets tired. I might spend next week productizing this, if that's of interest to you DM me + tell me your usecase!
English

Turn any workflow into an agent skill.
I built a YC job finder, deployed it as MCP server & connected it to Claude Desktop. It finds matching roles & sends personalized application emails to the recruiter.
If you can break a process into steps, this guide will help you automate it:
English
MCP vs. Skills for AI agents, clearly explained!
People treat MCP and Skills like they're the same thing.
They're not.
Conflating them is one of the most common mistakes I see when people start building AI agents seriously.
So let's break both down from scratch.
Before MCP existed, connecting an AI model to an external tool meant writing custom integration code every single time. 10 models, 100 tools? That's 1,000 unique connectors to build and maintain. The AI tooling ecosystem was a tangled mess of one-off glue code.
MCP (Model Context Protocol) fixes this with a shared communication standard.
Every tool becomes a "server" that exposes what it can do. Every AI agent becomes a "client" that knows how to ask. They talk through structured JSON messages over a clean, well-defined interface.
Build a GitHub MCP server once, and it works with Claude, ChatGPT, Cursor, or any other agent that speaks MCP. That's the core value: write the integration once, use it everywhere.
But here's where most explanations stop short.
MCP solves the *connection* problem. It does not solve the *usage* problem.
You can hand an agent 50 perfectly wired MCP tools and it'll still underperform if it doesn't know when to call which tool, in what order, and with what context.
That's the gap Skills fill.
A Skill is a portable bundle of procedural knowledge. Think of a SKILL. md file that tells an agent not just "here are your tools" but "here's how to use them for this specific task." A writing skill bundles tone guidelines and output templates. A code review skill bundles patterns to check and rules to follow.
MCP gives the agent hands. Skills give it muscle memory.
Together, they form the full capability stack for a production AI agent:
- MCP handles tool connectivity (the wiring layer)
- Skills handle task execution (the knowledge layer)
- The agent orchestrates both using its context and reasoning
This is why advanced agent setups increasingly ship both: MCP servers for integrations and SKILL. md files for domain expertise.
If you're building with agents, I have shared a repository of 85k+ skills that you can use with any agent, link in the next tweet!
GIF
English
@tonybuildsai @selinatasnim1 Very true, but do you know material which really good?
English

@selinatasnim1 the tutorials are garbage because they teach you to copy the n8n UI, not to think about what the agent needs to DO. the 3-prompt framework approach is right. system prompt, task prompt, output format. get those three clean and the rest follows.
English

99% of the AI agent tutorials on YouTube are garbage.
I’ve built 47 agents with n8n and Claude.
Here are the 3 prompts that actually work (and make agent-building simple).
Bookmark this post
🔖
Bonus: comment "Agent: and I’ll DM you AI agent system prompt + full guide ↓

English

Why are we still converting SQL → DataFrame → ML model in production? 🤔
Next HoustonPython: Kai Zhu's demo of sqlmath running 200k-row LightGBM backtests entirely in SQLite
Multi-threaded, low-latency, zero DataFrame shuffle ⚡
English

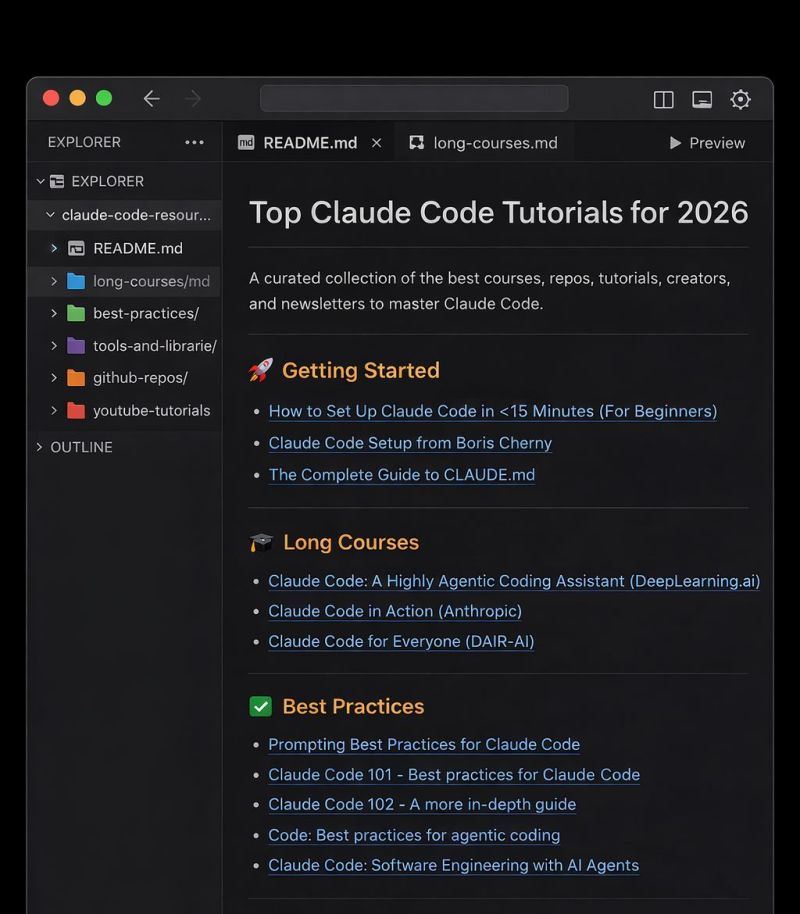
You won’t lose to AI.
You’ll lose to someone who mastered Claude Code first.
I put together every resource you need to go from curious about Claude Code to actually shipping with it.
This Includes:
🚀 3 Getting Started resources
📚 4 Long Courses
🧠 4 Best Practices guides
🛠 3 Tools & Libraries
🐙 8 battle-tested GitHub repos
📺 6 YouTube tutorials from builders actually using it
👥 6 creators worth following
📧 6 newsletters to stay sharp
This isn't theory. It's the exact stack people are using to build real products right now.
If you want Free Access
Like , RT
comment : Send
Follow Me is MUST so that i can DM you
English

@mattpocockuk Thanks for sharing!
You like this approach more than BMAD or similar tools?
English

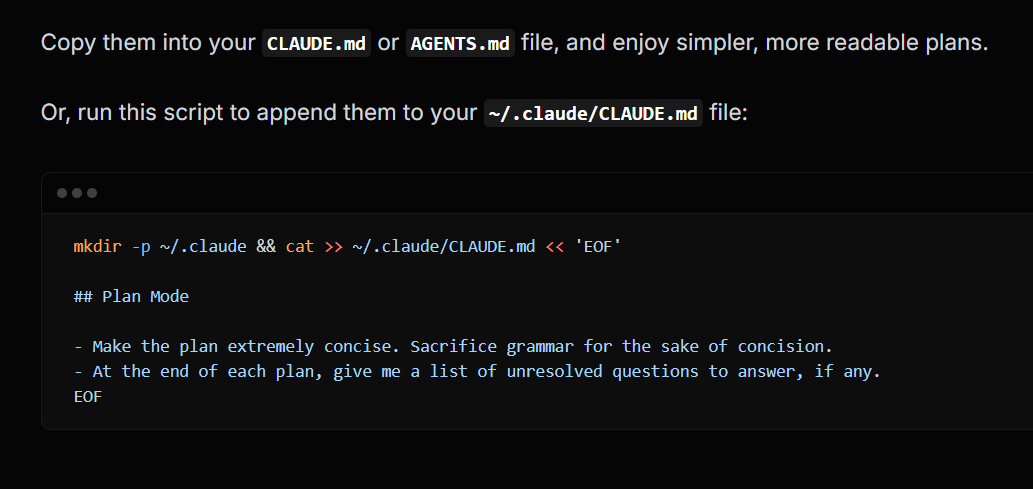
Here are my CLAUDE.md additions for making plan mode 10x better
Before: unreadably long plans
After: concise, useful plans with followup questions
aihero.dev/my-agents-md-f…
English

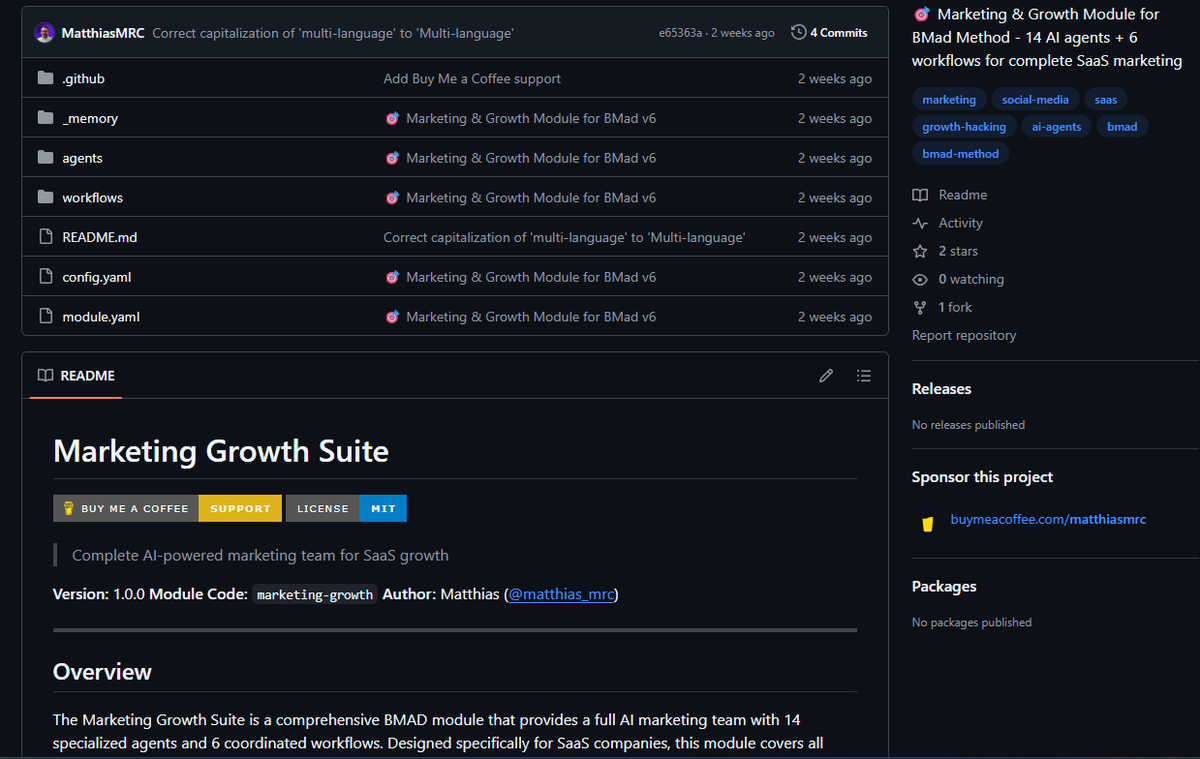
I'm so bad at copywriting..
Now trying a marketing variant of BMAD method (from @matthias_mrc) for the landing page...
Curious to see what I'll get🤔
English

I am surprised no one is talking about BMAD. Even many building in public don’t know about it.
BMAD is a workflow/method to build entire professional grade apps/SaaS/Games using Claude Code, Antigravity, Cursor, Open Code, etc.
It’s a collection of workflows with 12 agents such as Product Manager, UX designer, Developer, etc.
You just install it in your working directory and just run a single command, and it brainstorms your idea, researches on it, create PRD, and build the professional standard app.
I didn’t wanna gatekeep it so telling You all here.
If you have struggle understanding how to use it, just let me know, I will help.

English

99% of the AI agent tutorials on YouTube are garbage.
I’ve built 47 agents with n8n and Claude.
Here are the 3 prompts that actually work (and make agent-building simple).
Bookmark this post 🔖
Bonus: comment "Agent: and I’ll DM you AI agent system prompt + full guide ↓

English
@akshay_pachaar Can you share python code implementing such great ideas? Seems to even langchain does not have subchunking
English
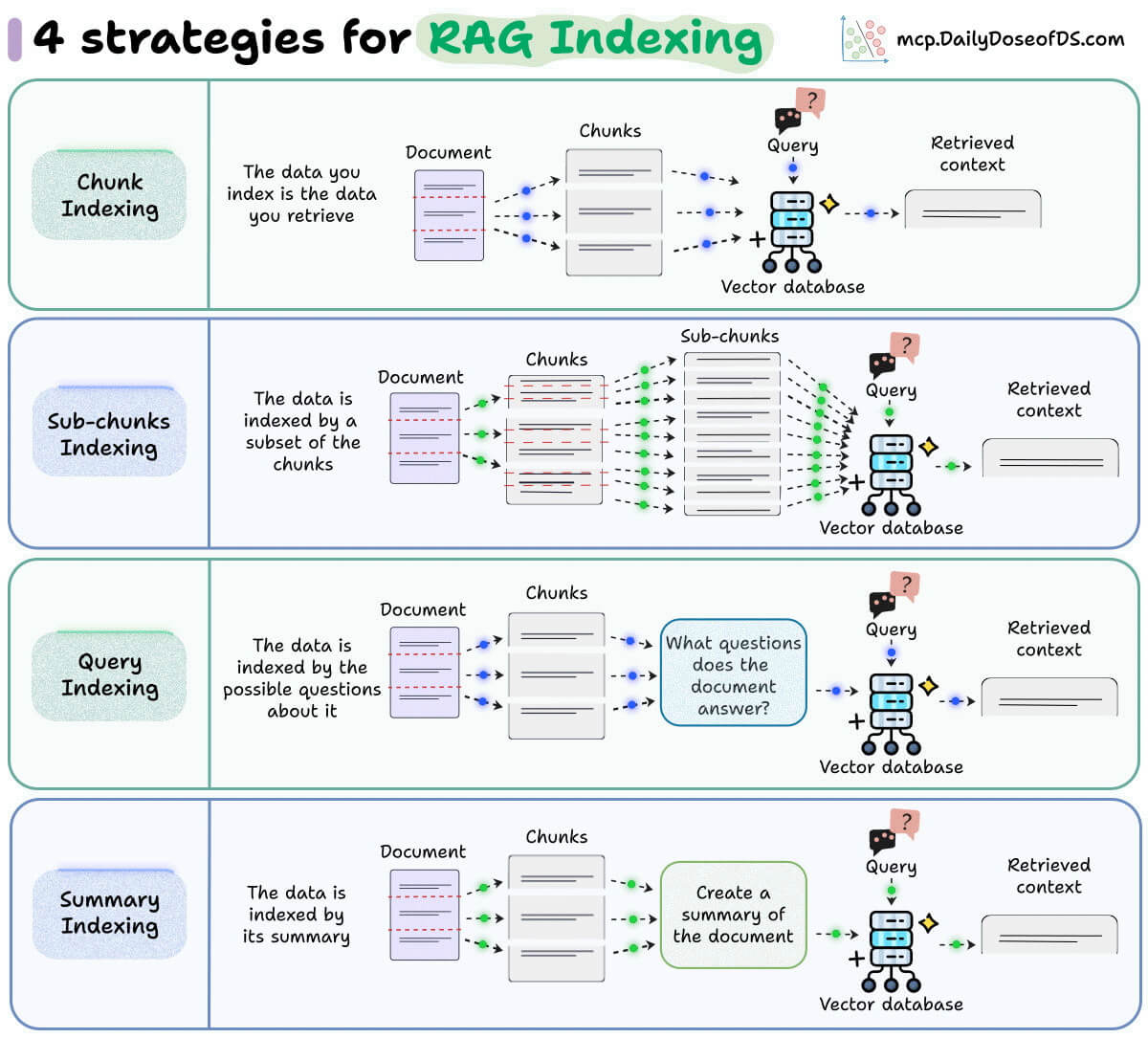
Here's a common misconception about RAG!
Most people think RAG works like this: index a document → retrieve that same document.
But indexing ≠ retrieval.
What you index doesn't have to be what you feed the LLM.
Once you understand this, you can build RAG systems that actually work.
Here are 4 indexing strategies that separate good RAG from great RAG:
1) Chunk Indexing
↳ This is the standard approach. Split documents into chunks, embed them, store in a vector database, and retrieve the closest matches.
↳ Simple and effective, but large or noisy chunks will hurt your precision.
2) Sub-chunk Indexing
↳ Break your chunks into smaller sub-chunks for indexing, but retrieve the full chunk for context.
↳ This is powerful when a single section covers multiple concepts. You get better query matching without losing the surrounding context your LLM needs.
3) Query Indexing
↳ Instead of indexing raw text, generate hypothetical questions the chunk could answer. Index those questions instead.
↳ User queries naturally align better with questions than raw document text. This closes the semantic gap between what users ask and what you've stored.
↳ Perfect for QA systems.
4) Summary Indexing
↳ Use an LLM to summarize each chunk. Index the summary, retrieve the full chunk.
↳ This shines with dense, structured data like CSVs and tables where raw text embeddings fall flat.
The bottom line:
You don't need to retrieve exactly what you indexed. Match your indexing strategy to your data, and your RAG system will perform significantly better.
What indexing strategies have worked best for you?
English

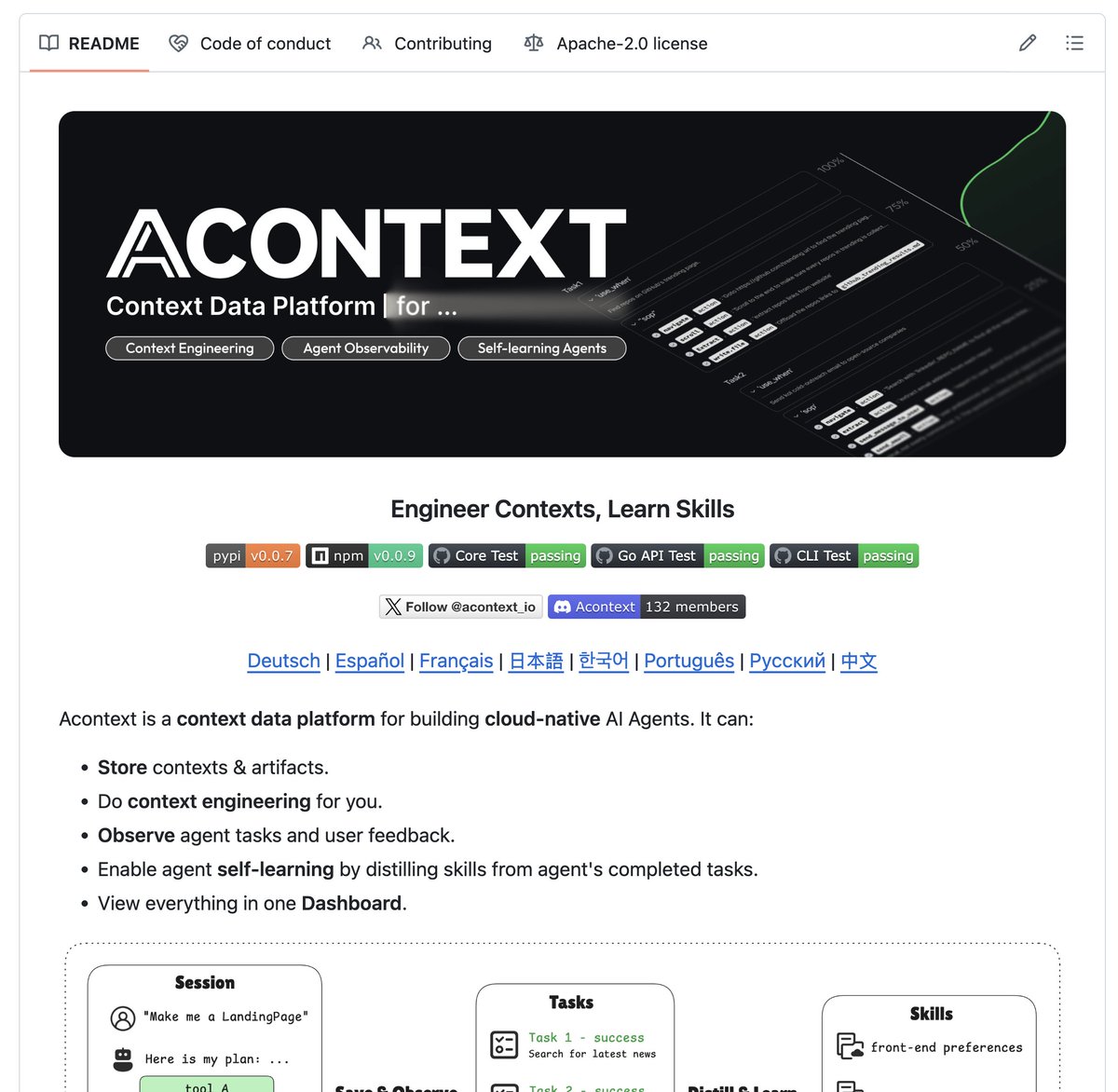
Prompt engineering is dead. Context engineering is the new king.
I've talked to many people building agents, and most are duct-taped together using a bunch of services:
• One to store messages
• One to manage memory
• Artifacts in S3
• A database acting as a journal
This is a complex mess.
Agents don't learn from their experience. They can't observe their own behavior and do something with it because it's all scattered everywhere.
Fortunately, we are trying to solve this:
Check out Acontext (GitHub Repository link below). This is the first platform I've seen that's centered around context:
STORE what happens → OBSERVE it → LEARN from it.
This simple shift is huge for building agents.
Some of the highlights:
1. The entire context lives in one place: messages, memory, files, tool calls, and session data. No need to bring in third-party tools.
2. Real observability by tracking agents at the task level.
3. The platform watches tasks that are completed, identifies execution patterns, and turns them into new skills automatically.
This last point is what surprised me the most:
An agent actually gets better at doing the things it succeeds at!
Acontext is open source, and it takes just one command to set up. It comes with Python and TypeScript SDKs.
See the link to the repository below.
English

Introducing KnowledgeTools — a gem from my private collection that lets Agents reason over a knowledge base.
It builds on the "think" tool from Anthropic and gives the model 3 new tools: Think → Search → Analyze.
By iteratively thinking, searching, and analyzing, Agents can reason over a set of documents, yielding incredible improvements over traditional and Agentic RAG.
Give it a try and let me know what you think!
Link to code below

English

Hiring has been extremely challenging 😅 I interviewed 10+ people in the past week, and my reasoning process converges to
* in the area they work, have they thought deeply about the problems and can give insights that I otherwise wouldn't know?
* can they think critically?
* how good are they at communicating?
If yes to all these questions + good engineering skills, I do everything I can to recruit.
I actually find fresh PhDs generally do better at these things than experienced people.
Nathan Lambert@natolambert
My raw thoughts on the job market -- both for those hiring and those searching -- at the cutting edge of AI. interconnects.ai/p/thoughts-on-…
English
@_avichawla @akshay_pachaar trajectory A is better than B" can you share link to paper about this
English


@sandstep1 @lateinteraction i am aware but my point is that this kind of info should be in the papers
English
i finally read the Recursive Language Models paper by Alex L. Zhang, Tim Kraska and @lateinteraction.
First, I really really liked it. Fantastic idea, framing and execution. Very cool approach. Read it.
But, and this is an issue with so many "LLM systems" papers today, I really wish it was more detailed. There are just not enough details for me to understand the core mechanism, which is the REPL and the implementation of recursive calls. I could of course *imagine* what they did, but not know for sure, which is a pitty, because I suspect that is where a lot of the heavy lifting is. We (as a field) must get better at describing our systems more accurately at these levels.
English