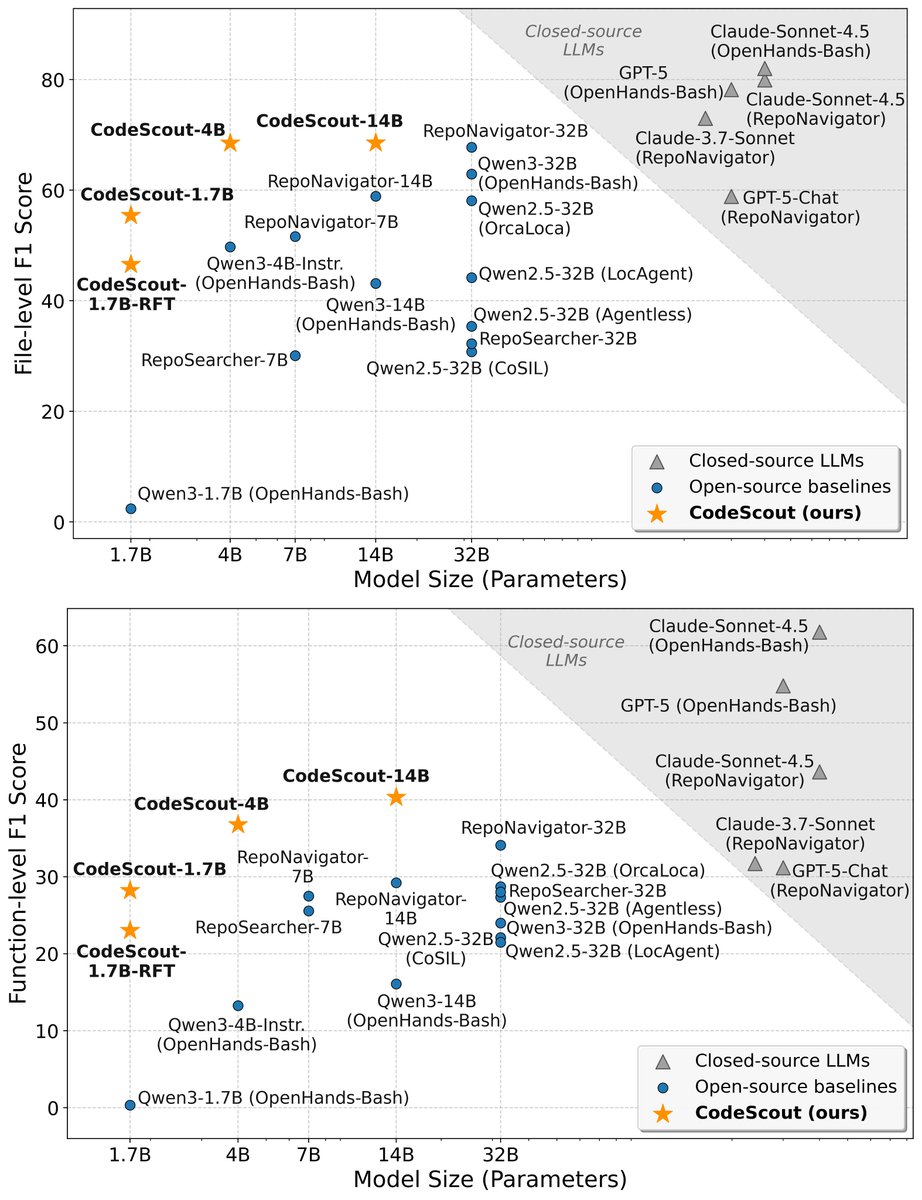
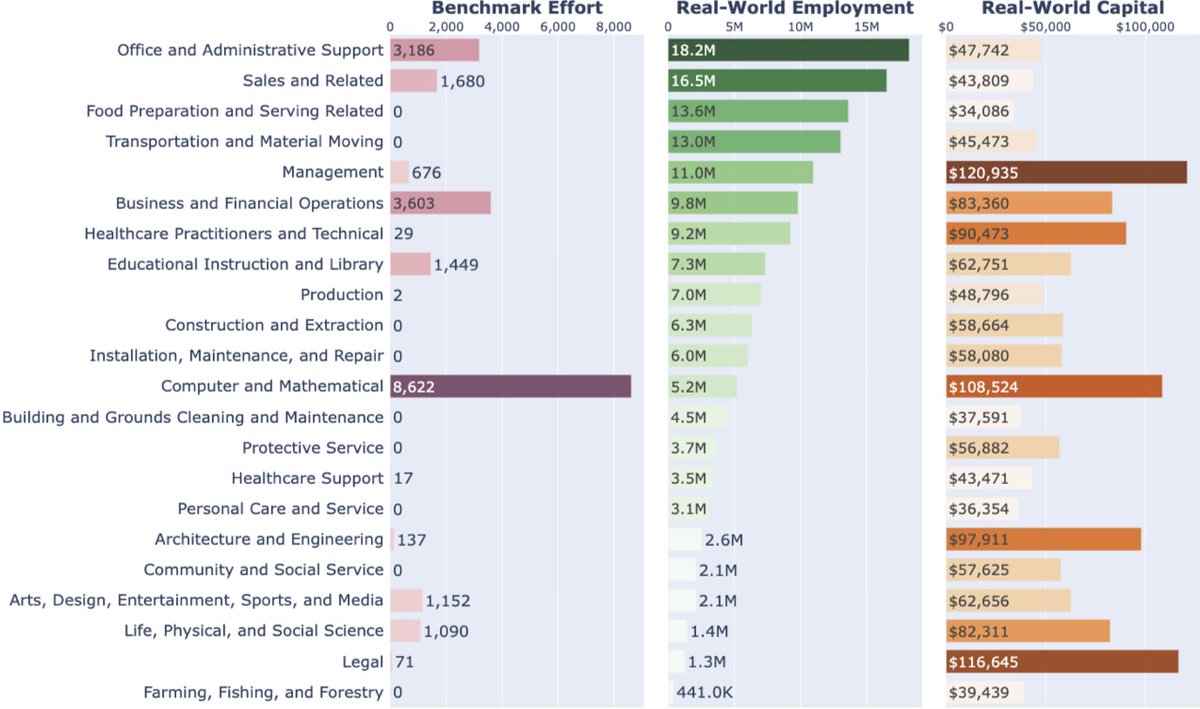
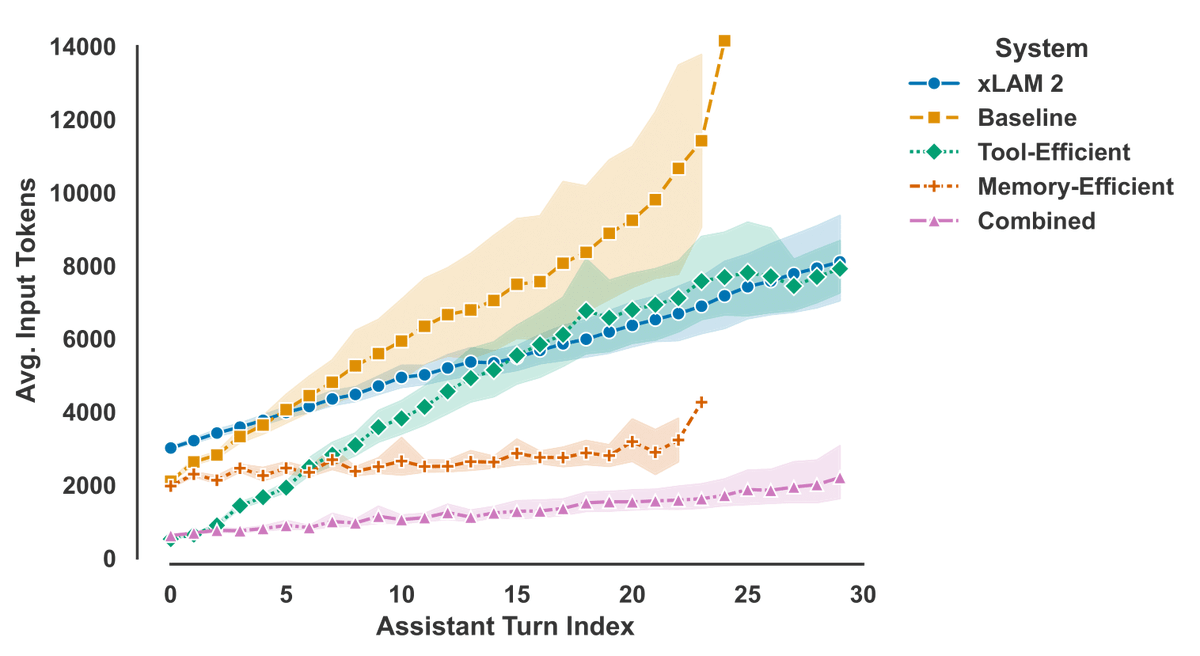
8/ Our work shows you can decompose clarification into task relevance and answerability, as intrinsic measures to optimize its effectiveness.
Paper: arxiv.org/abs/2604.14624
Code + data: github.com/sani903/Teachi…
A big thanks to my mentors for the project @vijaytarian and @gneubig
English