Sabitlenmiş Tweet

RL with verifiable rewards? Works great ✨
Realistic or non-verifiable tasks? Still a mess 📉
Reward models and AI judges? Fragile and inconsistent 💔
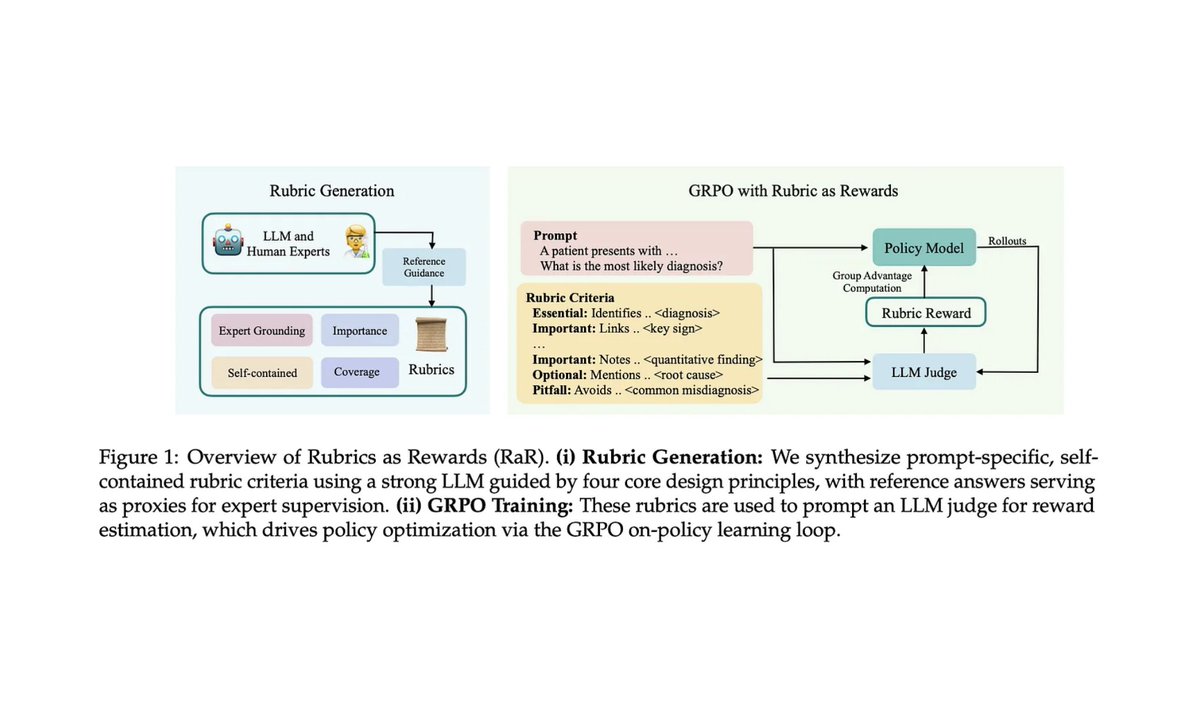
Our proposal? RL from Checklist Feedback 📜
arxiv.org/abs/2507.18624
👇
English
Vijay V.
1.1K posts

@vijaytarian
Grad student at CMU. I do research on ̶a̶p̶p̶l̶i̶e̶d̶ ̶N̶L̶P̶ ̶ large language models. he/him

1/ Humans often can’t state exactly what they want, making things hard for AI agents. Obvious fix: ask clarifying questions. But which ones? We studied this empirically with coding agents. Effective clarification comes down to two properties: answerability and task relevance.





For the avoidance of doubt, the OpenAI - @DeptofWar contract flows from the touchstone of “all lawful use” that DoW has rightfully insisted upon & xAI agreed to. But as Sam explained, it references certain existing legal authorities and includes certain mutually agreed upon safety mechanisms. This, again, is a compromise that Anthropic was offered, and rejected. Even if the substantive issues are the same there is a huge difference between (1) memorializing specific safety concerns by reference to particular legal and policy authorities, which are products of our constitutional and political system, and (2) insisting upon a set of prudential constraints subject to the interpretation of a private company and CEO. As we have been saying, the question is fundamental—who decides these weighty questions? Approach (1), accepted by OAI, references laws and thus appropriately vests those questions in our democratic system. Approach (2) unacceptably vests those questions in a single unaccountable CEO who would usurp sovereign control of our most sensitive systems. It is a great day for both America’s national security and AI leadership that two of our leading labs, OAI and xAI have reached the patriotic and correct answer here 🇺🇸




Distillation can be legitimate: AI labs use it to create smaller, cheaper models for their customers. But foreign labs that illicitly distill American models can remove safeguards, feeding model capabilities into their own military, intelligence, and surveillance systems.
AI agents are evolving beyond simple tasks to complex, multi-turn and multi-step interactions. But how do we train them with RL when verifiable rewards don't exist for open-ended conversations and building execution environments for thousands of tools is unscalable? Introducing 🛠️CM2: RL with Checklist Rewards for Multi-Turn and Multi-Step Agentic Tool Use [arxiv.org/abs/2602.12268] Core Contributions: 🔄 Multi-turn and Multi-step tool use senario ✅ Checklist Rewards: Replaces vague scalar scores with fine-grained, evidence-based binary criteria. 🛠️ Scalable Tool Simulation: Trains on 5,000+ tools using a hybrid LLM simulator, removing the need for manual API engineering. 👍 SOTA Performance: Achieves +8-12 point gains on τ^2-Bench, BFCL-V4 & ToolSandbox, surpassing larger open-source models.




With the talk of automated science and agents training models nowadays, I'd like to highlight one of our older works *prompt2model* by @vijaytarian and @GenAI_is_real We had an automatic pipeline of data acquisition, data transformation, fine tuning, and evaluation.

RL with verifiable rewards? Works great ✨ Realistic or non-verifiable tasks? Still a mess 📉 Reward models and AI judges? Fragile and inconsistent 💔 Our proposal? RL from Checklist Feedback 📜 arxiv.org/abs/2507.18624 👇


my most controversial opinion is that you shouldn’t trust anyone that calls themself an “AI researcher” but has never gotten a first author paper through peer review